Published Abstracts for 1997
Concurrency: Practice and Experience
1997 Publications
Application-Level Load Migration and Its Implementation on Top
of PVM
J. Song, H. K. Choo, and K. M. Lee
The development and experiment of a load (process) migration scheme
conceptually similar to moving house is described. The basic idea is to
migrate a process by starting a new process on another processor with
checkpoint data prepared by the old process itself but transferred
automatically by the migration system. The new process will then unpack
the data and resume the computation. The migration mechanism of our
facility is implemented by a set of library calls on top of PVM. It
performs functions such as freezing and unfreezing communications,
checking load conditions, selecting destination processors, starting new
processes, and receiving migrated data. Before migrating, a process
needs to freeze communication, handle pending messages in the receive
buffer, and pack checkpoint data. Besides the usual merits of
concurrency, location transparency, and the absence of residual
dependency, our scheme solves the incoming message problem at the
application level and is portable and easy to use in a heterogeneous
environment. Our experiment shows that our facility can help to
utilize 74% of idle CPU cycles of a network of workstations with less
than 6% overhead to their normal operations.
Short Code: [Song:97a]
Reference: Vol. 9, No. 1, pp. 1-19 (C277)
Variable Instruction Scheduling for MIMD Interpretation on
Pipelined SIMD Machines and for Compositional Instruction Sets
Nael B. Abu-Ghazaleh, and Philip A. Wilsey
Functional parallelism may be supported on SIMD machines by
interpretation. The programs and data of each function are loaded on
the processing elements (PEs) and the control unit of the machine
executes a central control algorithm that causes the concurrent
interpretation of these functions. The performance of this paradigm
has been shown to benefit considerably from a variable instruction
issue schedule that delays execution of expensive and rarely occuring
operations. Two new features of the interpretation paradigm, namely
pipelined SIMD machines and compositional instruction sets, change the
nature of the mathematical model used for variable instruction
scheduling significantly. In this paper, a previously developed
mathematical model of the interpretation process is extended to allow
for compositional instructions and pipelining. We develop and present
algorithms that produce variable instruction schedules for the extended
model and investigate whether variable instruction issue is useful for
these cases. We show that the variable instruction issue improves the
performance of pipelined machines but is not very effective for
compositional instruction sets, especially when the composition matrix
is not sparse.
Short Code: [Abu-Ghazaleh:97a]
Reference: Vol. 9, No. 1, pp. 21-39 (C274)
Dimension-Exchange-Based Global Load Balancing on Injured Hypercubes
Jie Wu
A study is made of a global load balancing scheme on hypercubes with
faulty links based on dimension exchange, where each node exchanges
workloads with its neighbors along a selected dimension in such a way
that their workloads become equal. A global load balancing algorithm
that can tolerate n-1 faulty links is first presented. It is then
extended to connected hypercubes with up to 2n-3 faulty links.
Comparisons between the proposed scheme with the regular
dimension-exchange-based scheme are also presented. Simulation results
show that the average number of message exchanges required in the
proposed scheme is very close to the one obtained from the regular
dimension-exchange-based scheme.
Short Code: [Wu:97a]
Reference: Vol. 9, No. 1, pp. 41-61 (C275)
GLU: A High-Level System for Granular Data-Parallel Programming
R. Jagannathan, C. Dodd, and I. Agi
We describe a high-level system for granular data-parallel programming
called GLU in which parallel applications are described as succinct
implicitly parallel intensional compositions using sequential imperative
functions. We show how different architecture-independent parallel
programs can be generated from the high-level application description. We
also show how GLU enables functional debugging of parallel applications
without requiring their parallel execution. To illustrate the efficiency
of parallel programs generated in GLU, we consider the results of a
performance study of three real parallel GLU applications, executed on two
different parallel computers. Finally, we compare GLU to other very
high-level systems for granular data-parallel programming.
Short Code: [Jagannathan:97a]
Reference: Vol. 9, No. 1, pp. 63-83 (C192)
Connection Resource Management for Compiler-Generated Communication
Susan Hinrichs
Traditionally parallel compilers have targeted a standard message
passing communication library when generating communication code (e.g.
PVM, MPI). The standard message passing model dynamically reserves
communication resources for each message. For regular, repeating
communication patterns, a static communication resource reservation
model can be more efficient. By reserving resources once for many
communication exchanges, the communication startup time is better
amortized. Plus, with a global view of communication, the static model
has a wider choice of routes. While the static resource reservation
model can be a more efficient communication target for the compiler,
this model reveals the problems of scheduling use of limited
communication resources. This paper uses the abstraction of a
communication resource to define two resource management problems and
presents three algorithms that can be used by the compiler to address
these problems. Initial measures of the effectiveness of these
algorithms are presented from two programs for an 8x8 iWarp
system.
Short Code: [Hinrichs:97a]
Reference: Vol. 9, No. 2, pp. 85-112 (C276)
Parallel Multidimensional Bisection
William Baritompa, and Sami Viitanen
A parallel framework of the multidimensional bisection global optimization
method of Wood is presented. The idea is to split the bracketing region
between processors, thus achieving parallel function evaluations. Using an
OCCAM-2 implementation on the Hathi-2 multitransputer system we explore
some different strategies for load balancing and present some results.
Short Code: [Baritompa:97a]
Reference: Vol. 9, No. 2, pp. 113-121 (C206)
Contextual Debugging and Analysis of Multithreaded Applications
M. Bednorz, A. Gwozdowski, and K. Zielinski
Multithreaded programs are especially difficult to test and debug.
The aim of the paper is to present a new concept of multithreaded
program analysis and debugging based on contextual visualisation of
the program components that influence thread execution. For this
purpose, a dedicated software package called MTV (multithreading
viewer) has been designed and implemented. It performs above the
run-time library level, and hence only a programmer's view of multiple
threads of control execution may be analyzed. The paper presents
tested program code instrumentation, communication and synchronization
between the instrumented program and MTV. Next, a general concept of
contextual visualisation of multithreaded programs has been
elaborated. A scheme of the MTV cooperation with the monitored
program is discussed. The user interface has been desribed. A
representation of the multithreaded program state has been shown, and
the capability of MTV for certain classes of error recognition has
been specified and illustrated by a few examples. These examples have
been not intended to be exhaustive, but they rather indicate the
opportunitites to exploit MTV for analysis of complex applications.
Short evaluation of the proposed contextual visualisation techniques
with application to multithreaded program analysis concludes the
paper.
Short Code: [Bednorz:97a]
Reference: Vol. 9, No. 2, pp. 123-139 (C258)
Message Based Cooperation Between Parallel Depth and Itensity
Matching Algorithms
W. J. Austin, and A. M. Wallace
A parallel vision system for object recognition and location based on
cooperative depth and intensity processing is described. The parallel
algorithm for intensity data processing is based on generation of
hypothesised matches between line junctions in the image and space curve
intersections in the model. These hypotheses lead to back projection of
the model and verification of promising hypotheses. The parallel algorithm
for depth data processing is based on a tree search algorithm constrained
by pairwise geometry between primitives. As each algorithm proceeds,
partial results are interchanged to direct the other concurrent process to
a more promising or more viable solution. The architecture has been
implemented and evaluated on a multi-transputer machine, and is illustrated
by several examples of pose definition of a test object.
Short Code: [Austin:97a]
Reference: Vol. 9, No. 2, pp. 141-162 (C298)
A PRAM Oriented Programming System
C. Leon, C. Rodriguez, F. Garcia, and F. de Sande
A PRAM-oriented programming language called ll and its
implementation on transputer networks are presented. The approach taken
is a compromise between efficiency and simplicity. The ll
language has been conceived as a tool for the study, design, analysis,
verification, and teaching of parallel algorithms. A method for the
complexity analysis of ll programs called PRSW is introduced.
The ll compiler guarantees the conservation of the PRSW
complexity of the algorithms translated. Furthermore, the
computational results illustrate the good behaviour of the system for
PRAM algorithms.
Short Code: [Leon:97a]
Reference: Vol. 9, No. 3, pp. 163-179 (C299)
Load Balancing Schemes for Extrapolation Methods
Thomas Rauber and Gudule R¨unger
Solving initial value problems (IVPs) for ordinary differential
equations (ODEs) has long been believed to be an inherently sequential
procedure. But IVP solvers using the extrapolation method provide high
quality solutions and offer a large potential for parallelism. In this
paper, we present algorithms for extrapolation methods on distributed
memory multiprocessors that combine different levels of parallelism.
These algorithms differ mainly in the partitioning of the processors
into groups which are responsible for the execution of the independent
tasks of the extrapolation method. We present the algorithms in a
compute-communicate scheme using appropriate primitives for the
communication. A detailed analysis shows that a sophisticated load
balancing scheme is required to achieve a good speedup. We describe an
optimal method based on Lagrange multipliers, investigate several
simple heuristic schemes, and compare the heuristic schemes with an
estimation for the optimal solution. An implementation of these
schemes on an Intel iPSC/860 confirms the predicted runtimes.
Short Code: [Rauber:95a]
Reference: Vol. 9, No. 3, pp. 181-202 (C300)
Contour Ranking on Coarse Grained Machines: A Case Study for
Low-level Vision Computations
F. Hameed, S. E. Hambrusch, A. A. Khokhar, and J. N. Patel
In this paper we present parallel solutions for performing image
contour ranking on coarse-grained machines. In contour ranking, a
linear representation of the edge contours is generated from the edge
contours of a raw image. We describe solutions that employ different
divide-and-conquer approaches and that use different communication
patterns. The combining step of the divide-and-conquer solutions uses
efficient sequential techniques for merging information about
subimages. The proposed solutions are implemented on Intel Delta and
Intel Paragon machines. We discuss performance results and present
scalability analysis using different image and machine sizes.
Short Code: [Hameed:95a]
Reference: Vol. 9, No. 3, pp. 203-221 (C263)
Experiences with a Wide Area Network Metacomputing Management
Tool using IBM SP2 Parallel Systems
R. Baraglia, G. Faieta, M. Formica, and D. Laforenza
The need to deal with highly complex scientific problems has led some
researchers to use geographically distributed computing resources as a
single powerful parallel machine. The work metacomputing has
been coined to describe this new approach. This paper outlines some
experiences in metacomputing carried out on a wide area network. A
brief overview is given of the main issues concerning metacomputing and
some experiments in this field are reported. WAMM, the metacomputer
visual interface we have developed, is described. Astrophysics is a
particularly fruitful field for numerical-intensive computer
simulation, because the systems under study, stars and galaxies, are
not amenable to controlled laboratory experiments. An astrophysical
application of the gravitational n-Body problem, developed in
conjunction with the Scuola Normale Superiore of Pisa, that was used to
test WAMM's utility in metacomputer management, and some performance
figures related to the case study are given. Work related to WAMM and
conclusions are presented.
Short Code: [Baraglia:97a]
Reference: Vol. 9, No. 3, pp. 223-239 (C272)
Parallel Generation of Adaptive Multiresolution Structures for
Image Processing
Xi Li, Sotirios G. Ziavras, and Constantine N. Manikopoulos
In this paper we present an algorithm for creating
region-adjacency-graph (RAG) pyramids on TurboNet, an experimental
parallel computer system. Each level of these hierarchies of
irregular tesselations is generated by independent stochastic
processes that adapt the structure of the pyramid to the content of
the image. RAGs can be used in multiresolution image analysis to
extract connected components from labeled images. The implementation
of the algorithm is discussed and performance results are presented
for three different communication techniques which are supported by
the TurboNet's hybrid architecture. The results indicate that
efficient communications are vital to good performance of the
algorithm.
Short Code: [Li:97a]
Reference: Vol. 9, No. 4, pp. 241-254 (C260)
SUMMA: Scalable Universal Matrix Multiplication Algorithm
R. A. van de Geijn, and J. Watts
In this paper, we give a straightforward, highly efficient, scalable
implementation of common matrix multiplication operations. The
algorithms are much simpler than previously published methods, yield
better performance, and require less work space. MPI implementations
are given, as are performance results on the Intel Paragon system.
Short Code: [Geijn:97a]
Reference: Vol. 9, No. 4, pp. 255-274 (C267)
Automatic Selection of Load Balancing Parameters using Compile-time
and Run-time Information
B. S. Siegell, and P. A. Steenkiste
Clusters of workstations are emerging as an important architecture.
Programming tools that aid in distributing applications on workstation
clusters must address problems of mapping the application,
heterogeneity and maximizing system utilization in the presence of
varying resource availability. Both computation and communication
capabilities may vary with time due to other applications competing
for resources, so dynamic load balancing is a key requirement. For
greatest benefit, the tool must support a relatively wide class of
applications running on clusters with a range of computation and
communication capabilities. We have developed a system that supports
dynamic load balancing of distributed applications consisting of
parallelized DOALL and DOACROSS loops. The focus of this paper is on
how the system automatically determines key load balancing parameters
using run-time information and information provided by programming
tools such as a parallelizing compiler. The parameters discussed are
the grain size of the application, the frequency of load balancing,
and the parameters that control work movement. Our results are
supported by measurements on an implementation for the Nectar system
at Carnegie Mellon University and by simulation.
Short Code: [Siegell:97a]
Reference: Vol. 9, No. 4, pp. 275-317 (C305)
A Comparison of Optimization Heuristics for the Data Mapping
Problem
Nikos Chrischoides, Nashat Mansour, and Geoffrey Fox
In this paper we compare the performance of six heuristics with
suboptimal solutions for the data distribution of two-dimensional
meshes that are used for the numerical solution of partial
differential equations (PDEs) on multicomputers. The data mapping
heuristics are evaluated with respect to seven criteria covering load
balancing, interprocessor communication, flexibility and ease of use
for a class of single-phase iterative PDE solvers. Our evaluation
suggests that the simple and fast block distribution heuristic can be
as effective as the other five complex and computational expensive
algorithms.
Short Code: [Chrisochoides:97a]
Reference: Vol. 9, No. 5, pp. 319-343 (C215)
A Poly-Algorithm for Parallel Dense Matrix Multiplicationon
Two-Dimensional Process Grid Topologies
Jin Li, Anthony Skjellum, and Robert D. Falgout
In this paper, we present several new and generalized parallel dense
matrix multiplication algorithms of the form 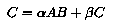 on two-dimensional process grid topologies. These algorithms can deal
with rectangular matrices distributed on rectangular grids. We
classify these algorithms coherently into three categories according
to the communication primitives used and thus we offer a taxonomy for
this family of related algorithms.
All these algorithms are represented in the data distribution
independent approach and thus do not require a specific data
distribution for correctness. The algorithmic compatibility
condition result shown here ensures the correctness of the matrix
multiplication. We define and extend the data distribution
functions and introduce permutation compatibility and
algorithmic compatibility. We also discuss permutation compatible
data distribution (modified virtual 2D data distribution).
We conclude that no single algorithm always achieves the best
performance on different matrix and grid shapes. A practical approach
to resolve this dilemma is to use poly-algorithms. We analyze the
characteristics of each of these matrix multiplication algorithms and
provide initial heuristics for using the poly-algorithm.
All these matrix multiplication algorithms have been tested on the IBM
SP2 system. The experimental results are presented in order to
demonstrate their relative performance characteristics, motivating the
combined value of the taxonomu and new algorithms introduced here.
on two-dimensional process grid topologies. These algorithms can deal
with rectangular matrices distributed on rectangular grids. We
classify these algorithms coherently into three categories according
to the communication primitives used and thus we offer a taxonomy for
this family of related algorithms.
All these algorithms are represented in the data distribution
independent approach and thus do not require a specific data
distribution for correctness. The algorithmic compatibility
condition result shown here ensures the correctness of the matrix
multiplication. We define and extend the data distribution
functions and introduce permutation compatibility and
algorithmic compatibility. We also discuss permutation compatible
data distribution (modified virtual 2D data distribution).
We conclude that no single algorithm always achieves the best
performance on different matrix and grid shapes. A practical approach
to resolve this dilemma is to use poly-algorithms. We analyze the
characteristics of each of these matrix multiplication algorithms and
provide initial heuristics for using the poly-algorithm.
All these matrix multiplication algorithms have been tested on the IBM
SP2 system. The experimental results are presented in order to
demonstrate their relative performance characteristics, motivating the
combined value of the taxonomu and new algorithms introduced here.
Short Code: [Li:97b]
Reference: Vol. 9, No. 5, pp. 345-389 (C202)
A Block Jacobi Method on a Mesh of Processors
Domingo Giménez, Vicente Hernández, Robert van de Geijn,
and Antonio M. Vidal
In this paper, we study the parallelization of the Jacobi method to
solve the symmetric eigenvalue problem on a mesh of processors. To
solve this problem obtaining a theoretical efficiency of 100% it is
necessary to exploit the symmetry of the matrix. The only previous
algorithm we know exploiting the symmetry on multicomputers is that of
van de Geijn (1991), but that algorithm uses a storage scheme adequate
for a logical ring of processors, so having a low scalability. In this
paper we show how matrix symmetry can be exploited on a logical mesh of
processors obtaining a higher scalability than that obtained with van
de Geijn's algorithm. In addition, we show how the storage scheme
exploiting the symmetry can be combined with a scheme by blocks to
obtain a highly efficient and scalable Jacobi method for solving the
symmetric eigenvalue problem for distributed memory parallel
computers. We report performance results from the Intel Touchstone
Delta, the iPSC/860, the Alliant FX/80 and the PARSYS SN-1040.
Short Code: [Gimenez:97a]
Reference: Vol. 9, No. 5, pp. 391-411 (C270)
Notebook Interfaces for Networked Scientific Computing: Design
and WWW Implementation
S. Weerawarana, A. Joshi, E. N. Houstis, J. R. Rice, and A. C.
Catlin
Advances in wired and wireless networking technologies are making
networked computing the most common form of high performance
computing. Similarly, software like Mosaic and Netscape have not only
unified the networked computing landscape, but they made it available
to the masses in a simple, machine independent way. These
developments are changing the way we do computational science, learn,
research, collaborate, access information and resources, the maintain
local and global relations. We envision a scenario where large scale
computational science and engineering applications like virtual
classrooms and laboratories are ubiquitous, and information resources
are accessible on-demand from anywhere. In this paper we present the
design of a user interface that will be appropriate to this scenario.
We argue that interfaces modeled on the pen and paper paradigm are
suited in this context. Specifically, we present the software
architecture of a notebook interface. We lay down the requirements
for such an interface and present its implementation using the World
Wide Web. A realization of the notebook model is presented for a
problem solving environment (PDELab) to support the numerical
simulation of PDE based applications on a network of heterogeneous
high performance machines.
Short Code: [Weerawarana:97a]
Reference: Vol. 9, No. 7, pp. 675-695 (C280)
Performance Modeling of Dense Cholesky Factorization on the
MasPar MP-2
Vivek Garg and David E. Schimmel
In this paper we study various implementations of Cholesky
factorization on SIMD architectures. A submatrix algorithm is
implemented on the MasPar MP-2 using both block and torus-wrap data
mappings. Both LLT and LDLT (square root free)
implementations of the algorithm are investigated. The execution
times and performance results for the MP-2 are presented. The
performance of these algorithms is characterized in terms of the
problem size, machine size, and other machine dependent
communication and computation parameters. Analysis for the
communication and computation complexities for these algorithms is
also presented, and models to predict the performance are derived.
The torus-wrap mapped implementations outperformed the block
approach for all problem sizes. The LDLT implementation
outperformed LLT for small to medium problem sizes.
Short Code: [Garg:97a]
Reference: Vol. 9, No. 7, pp. 697-719 (C273)
Parallel Program Analysis on Workstation Clusters: Speedup
Profiling and Latency Hiding
Roberto Togneri
Parallel programming on workstation clusters is subject to many
factors and problems which determine the potential success or
failure of any individual implementation. The most obvious
problems are the difficulty in developing parallel algorithms and
the high communication latency which may render such algorithms
inefficient. In an attempt to address some of these issues we
propose a strategy for estimating the potential speedup of a parallel
program based on computation ande communication profiling. We show
that our proposed strategy yields accurate estimates of the
speedup. We also propose a complete communication model so that
the speedup can be estimated under different programming inputs and
show that moderately accurate estimates can be obtained. High
communicatin latency is the major problem with workstation cluster
computing. We attempt to examine this problem from the system
level point of view and experimentally that latency hiding can
allow almost full utilisation of the CPU resource even though
individual programs may suffer from high communication latencies.
Short Code: [Togneri:97a]
Reference: Vol. 9, No. 7, pp. 721-751 (C294)
Algorithms for Solving a Spatial Optimisation Problem on a
Parallel Computer
F. George, N. Radcliffe, M. Smith, M. Birkin, and M. Clarke
In a collaborative project between GMAP Ltd. and EPCC, an existing
heuristic optimisation scheme for strategic resource planning was
parallelised to run on the data parallel Connection Machine CM-200.
The parallel software was found to run over 2,700 times faster than the
original workstation software. This has allowed the exploration of
complex business planning strategies at a national, rather than
regional, level for the first time. The availability of a very fast
evaluation program for planning solutions also enabled an investigation
of the use of genetic algorithms in place of GMAP's existing heuristic
optimisation scheme. The results of this study show that genetic
algorithms can provide better quality solutions in terms of both
predicted profit from the solution, and spatial diversity to provide a
range of possible solutions. This paper discusses both the
parallelisation of the original optimisation scheme and the use of
genetic algorithms in place of this method.
Short Code: [George:97a]
Reference: Vol. 9, No. 8, pp. 753-780 (C301)
Performance Comparison of a Set of Periodic and Non-Periodic
Tridiagonal Solvers on SP2 and Paragon Parallel Computers
Xian-He Sun, and Stuti Moitra
Various tridiagonal solvers have been proposed in recent years for
different parallel platforms. In this paper, the performance of three
tridiagonal solvers, namely, the parallel partition LU algorithm, the
parallel diagonal dominant algorithm, and the reduced diagonal
dominant algorithm, is studied. These algorithms are designed for
distributed-memory machines and are tested on an Intel Paragon and an
IBM SP2 machines. Measured results are reported in terms of execution
time and speedup. Analytical study are conducted for different
communication topologies and for different tridiagonal systems. The
measured results match the analytical results closely. In addition to
address implementation issues, performance considerations such as
problem sizes and models of speedup are also discussed.
Short Code: [Sun:97a]
Reference: Vol. 9, No. 8, pp. 781-801 (C279)
A Benchmark Study Based on the Parallel Computation of the
Vector Outer-Product A=uvT Operation
Rudnei Dias da Cunha
In this paper we benchmark the performance of the Cray T3D,
IBM 9076 SP/1 and Intel Paragon XP/S parallel computers, using
implementations of parallel algorithms for the computation of the
vector outer-product A=uvT operation. The vector
outer-product
operation, although very simple in nature, requires the computation of
a large number of floating-point operations and its parallelization
induces a great level of communication between the processors. It is
thus suited to measure the relative speed of the processor, memory
subsystem and network capabilities of a parallel computer. It should
not be considered a ``toy problem,'' since it arises in numerical
methods in the context of the solution of systems of non-linear
equations - still a difficult problem to solve. We present algorithms
for both the explicit shared-memory and message-passing programming
models together with theoretical computation models for those
algoritjms. Actual experiments were run on those computers, using
Fortran 77 implementations of the algorithms. The results obtained
with these experiments show that due to the high degree of
communication between the processors one needs a parallel computer with
fast communications and carefully implemented data exchange routines.
The theoretical computation model allows prediction of the speed-up to
be obtained for some problem size on a given number of processors.
Short Code: [Cunha:97a]
Reference: Vol. 9, No. 8, pp. 803-819 (C295)
Parallel Join for IBGF Partitioned Relational Databases
M. Bozyigit, S. A. Mohammed, and M. Al-Tayyeb
This study is concerned with a parallel join operation where the
subject relations are partitioned according to an Interpolation Based
Grid File (IBGF) scheme. The partitioned relations and
directories are distributed over a set of independently accessible
external storage units, together with the partitioning control data.
The join algorithms executed by a mesh type parallel computing system
allow handling of uniform as well as nonuniformly partitioned
relations. Each processor locates and retrieves the data partitions
it is to join at each step of the join process, in synchronization with
other processors.
The approach is found to be feasible as the speedup and efficiency
results found by simulation are consistent with theoretical bounds.
The algorithms are tuned to join-key distributions, so that effective
load balancing is achieved during the actual join.
Short Code: [Bozyigit:97a]
Reference: Vol. 9, No. 8, pp. 821-836 (C324)