Project Status of the NPAC/SRC CEM Project

TASKS FINISHED
-
All the code development on Intel, CM5 and IBM SP-1 has been finished.
An efficient matrix filling algorithm is developed which requires no
communication at all. Thus the filling part of the code solely
depends on node performance of parallel system.
-
Porting of the Intel version to IBM SP-1 PVM version took just one day,
due to the portability of BLACS/ScaLAPACK and PVM. Also this code is
ported to NPAC's 8-node DEC Alpha Farm (Gigaswitch-connected) and the
ATM testbed of 2 SUN IPXs.
-
Production runs for test cases with
matrix size up to 10,000 (including EMCC
real test cases) have been conducted on the following platforms:
- CCSF 512-node Intel Delta
- CCSF 56-node Intel Paragon
- NASA AMES NAS 208-node Intel Paragon
- CCSF 64-node Intel iPSC/860
- Minnesota AHPCRC 512-node CM5
- ANL 128-node IBM SP-1 (only 64-node used)
-
The performance results are very encouraging.
For all the platforms, the speedup for the filling part is
almost linear and IBM SP-1 gives the best filling performance.
(the filling part is not dominated by floating-point calculation,
about 50% floating-point, 50% memory access).
For the LU solver, CM5 CMSSL solver achieves the best. For a
matrix size = 10,000 case, we got 16 GFlops on 512-node
CM5 with VU. The same case on 512-node Intel Delta is 8 GFlops.
The same case on 56-node Paragon is about 4 GFlops. (note that
the LU timing on the Intel platforms are not optimized timing
as we use the same ScaLAPACK partition in both filling and solving
parts of the code and in the production run a data partition, represented
by a blocksize and virtual processor grid, only optimized for
filling is used.)
-
The parallel code has been ported to IBM SP-1 with the HPswitch running
EUI-H protocol, after receiving a prereleased unoptimized BLACS version
on EUI-H from ORNL/UTK.
-
An interactive simulation/visualization system for this application is developed
under the AVS(Application Visualization System) which allows run-time steering
of model parameters input(currently the azimuth - the transmitter's angle,
and other visualization parameters), initiating simulation on multiple parallel
systems(currently IBM SP1 and CM5), and graphically displaying 2D far-field
along with 3D geometry target with or without visible gridding on the surface. Click
here to take a look of the graphical user interface.
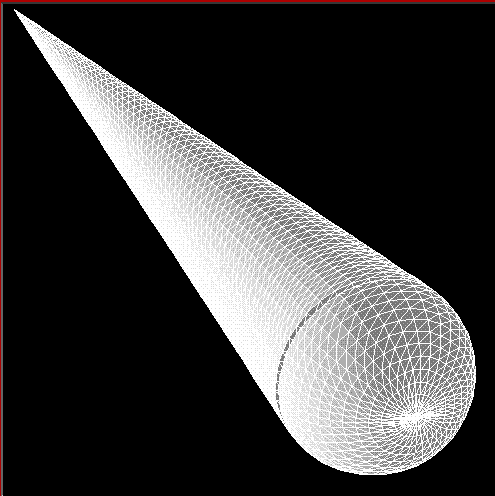
Following (geometry) test cases have been conducted for the parallel
ParaMom package:
NASA almond Wedge Cylinder with Gap Semi-sphere(symmetry)



Sphere Cylinder Plane



VFY Cone Sphere with Gap Circular Cavity



Rectangular Cavity Wedge Plat Cylinder


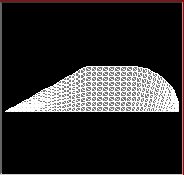
Plate Cylinder Business Card Double Ogive



Single Ogive

TASKS PLANNED
-
On Intel platform, experiment with parallel I/O approach to allow
different partitions in filling and LU to achieve optimized performance
for both filling and ScaLAPACK algorithms, while using CFS/PFS as a buffer
to move data between filling and LU slover.
-
On Intel Paragon, insert the Prosolver-DES factor and solve routines
into the code to replace the ScaLAPACK LU solver.
-
On the CM5, start to look into out-of-core filling algorithm.
-
Port the code to Cray T3D.
Northeast Parallel Architectures Center, Syracuse University, npac@npac.syr.edu
This page is maintained by Gang Cheng, gcheng@npac.syr.edu.
Last change: 04/14/94
{kind=link}