RPC technology simplifies the design of distributed software systems
by providing a means to separate one program into two
cooperating processes using a procedural interface.
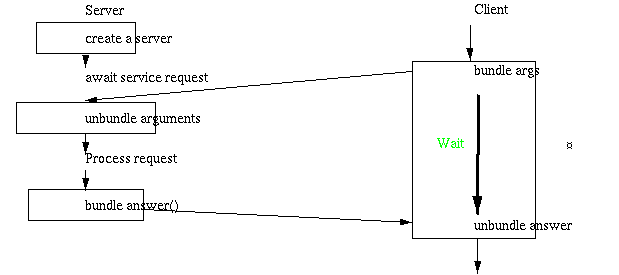
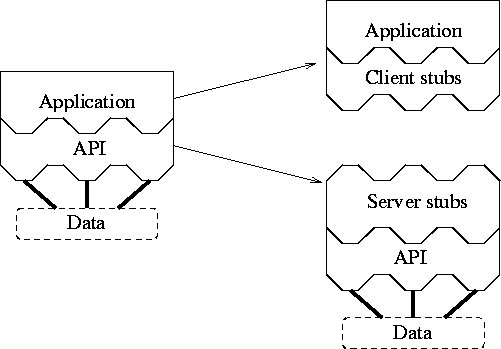
The RPC client and server `stubs' form the communication interface between the application program and server. The client stubs encode their arguments and sends them over the network to matching stubs in the server. The server stubs extract the arguments from the network and compute results based on the arguments. The server stubs return to the client the results of the computations.
RPC client stubs can serve as replacements for the API functions invoked by an application program. Once arguments are passed into the server stub it can `compute the result' by calling the API function for which the client stub is a replacement. The server stub then returns as its result the return value of the API call.
From the a user point of point, there is no difference between this access and an access to a local file using the standard API library. This is because the RPC client stubs preserve exactly the semantics of the standard API since there is a one-to-one mapping between function calls in the RPC client stubs (i.e., client library), the RPC server stubs (the transmission protocol) and the standard implementation of the API.
A major problem with RPC technology is that it is based on a strict request-reply paradigm. While certain data sets work well in that context, others do not. For example, access to data sets that from a relational databases, and thus are of unknown length. A good data server for such a data set would begin returning records to the user program before the server completes sending the result of a given access. However, the request-reply nature of RPCs makes this difficult.
Further complicating the use of RPCs is that all network interprocess
communications code is nominally contained in the RPC
server. Thus the server is responsible for all access logging and all
security precautions. While basic access to a network is fairly
easy to provide, more advanced functions quickly add to the complexity
of the server and can easily dominate the time required to
design and build it as well as the effort required to support it.