 Figure 1: Industry View of Enterprise Computing
Figure 1: Industry View of Enterprise ComputingWeb Technologies in High Performance Distributed Computing
DRAFT
Geoffrey Fox, Wojtek Furmanski
September 1,1997
NPAC 3-131 CST
Syracuse University
111 College Place
Syracuse
NY 13244-4100
Introduction: Tactical and Strategic Issues
The underlying assumption of this chapter is that industry is building a rich distributed computing environment which is aimed at either worldwide or Intranet applications of Web technologies. By this term, we mean at the lower level the collection of standards and tools such as HTML, HTTP, MIME, CGI, Java, JavaScript, VRML, JDBC and other Java frameworks, dynamic Java servers and clients including applets and servlets. At a higher level collaboration, security, commerce, multimedia and other applications/services are rapidly developing. Note the open interfaces of the Web are equally if not more important than the explicit technologies. (http://www.npac.syr.edu/projects/webspace/webbasedhpcc/ )This rich collection of capabilities has implications for HPCC at several different levels. Examples of some of the useful tactical implications are:
However probably most important are strategic implications of recent Web related developments which could affect the overall architecture of a high performance parallel or distributed computing system. First we note that we have seen many other major broad-based hardware and software developments -- such as IBM business systems, UNIX, Macintosh/PC desktops, video games -- but these have not had profound impact on HPCC software. However we suggest the Web developments are different for they give us a world-wide/enterprise-wide distributing computing environment. Previous software revolutions could help particular components of a HPCC software system but the Web can in principle be the backbone of a complete HPCC software system -- whether it be for some global distributed application, an enterprise cluster or a tightly coupled large scale parallel computer. In a nutshell, we suggest that "all we need to do" is to add "high performance" (as measured by bandwidth and latency) to emerging commercial web systems. This "all we need to" may be very hard but by using the Web as a basis we inherit a multi-billion investment and what in many respects is the most powerful productive software environment ever built. Thus we should look carefully into the design of any HPCC system to see how it can leverage this commercial environment.
Note that we are blatantly pragmatic; even if the Web has made the "wrong" choice in some area, it may still be best to go along with this to gain the advantages of the overall system. This implies decisions cannot just be made on the basis of fundamental principles but rather must be aware of the limited HPCC funds. One should spend these where possible on those issues (i.e. "high performance") which are either specific to the field or interfacing HPCC features with the Web and so have most leverage.
Figure 1: Industry View of Enterprise Computing
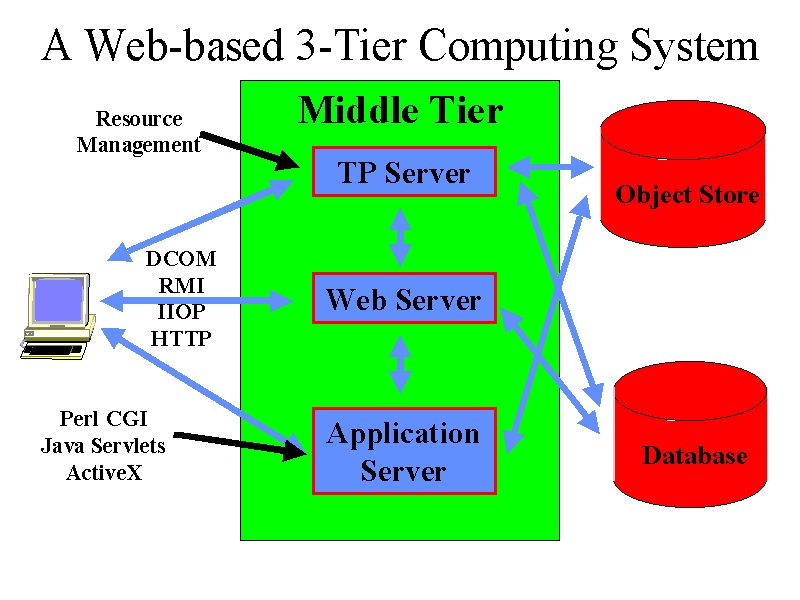
A recent issue of Byte (http://www.byte.com/art/9708/sec5/art1.htm) has an interesting discussion of the 3-tier computing model shown in figure 1. Here a middle tier of custom servers (a.k.a. middleware) acts as a gateway to backend capabilities such as those given by the databases sketched in the figure. Microsoft is developing COM and JavaSoft "Enterprise Javabeans" to implement this middle tier which in its simplest Web implementation is a worldwide network of Java web servers which implement the basic distributed information system of the Web. This can be generalized to include large scale computing resources as sketched below.
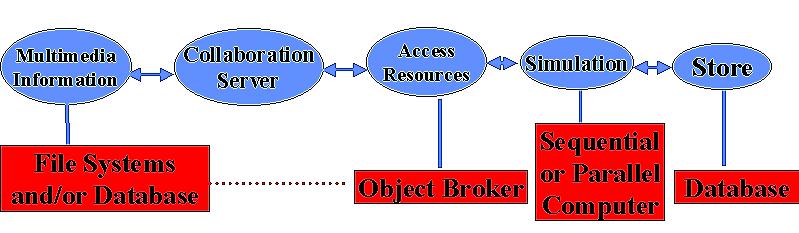
Figure 2: Middle (blue) and backend (red) tier
Although still qualitative, this discussion captures our essential strategy for combining HPCC and Web technologies. The Web builds a high functionality and modest performance distributed computing system from which we get essentially all services with required capability but perhaps totally inadequate performance. Note that we can classify many of the needed HPCC or parallel computing tools/techniques into either decomposition or integration. Decomposition is achieved by a parallel algorithm, a parallelizing compiler such as HPF or by the user writing a Fortran plus message passing code "by hand". MPI integrates decomposed parts together with high bandwidth and low latency constraints. Similarly systems such as AVS or Khoros integrate coarser grain components with attractive visual interfaces. The Web provides integration (of information, people, and computers) but not decomposition services. However most of the demands of next generation applications -- computational steering, data-intensive problems, collaboration, advanced distributed visualization -- are largely integration issues. The great success of parallel algorithm research has provided us with a good understanding of decomposition. We now need to integrate these together into sophisticated user-friendly systems.
Note: One could conveniently reference Kennedy's chapter here!
Multidisciplinary Applications
We can illustrate the Web technology strategy with a simple multidisciplinary application involving the linkage of two modules A and B -- say CFD and structures applications respectively. One could view the linkage sequentially as in top of fig. 3 but often one needs higher performance and one would "escape" into an MPI (or PVMPI) layer which linked decomposed components of A and B with high performance. Here we view MPI as the "machine language" of the higher-level web communication model given by approaches such as WebFlow from NPAC.
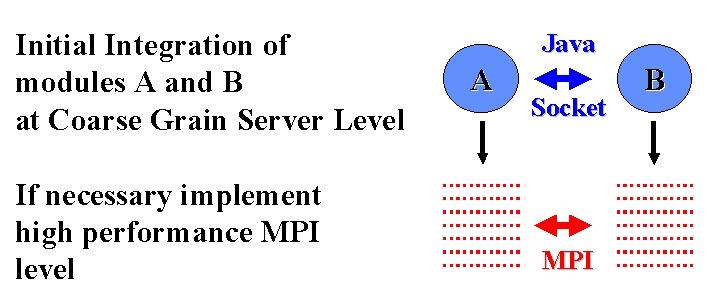
Figure 3: Web (Top) and HPCC (Lower) Implementations of two linked parallel modules
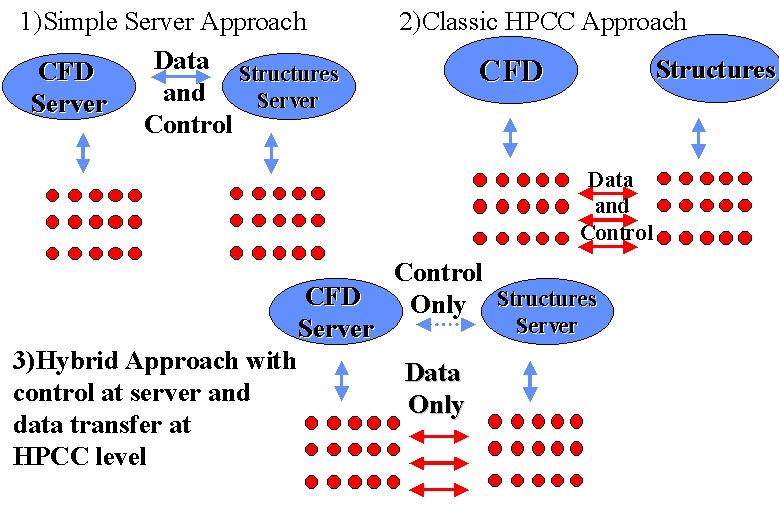
Figure 4: 3 ways of Linking Two Modules
Figure 4 refines this in a critical way and points out that there is a middle ground between the two implementations of fig. 3 where one keeps control (initialization etc.) at the server level and "only" invokes the high performance back end for the actual data transmission. This appears to obtain the advantages of both Web and HPCC approaches for we have the functionality of the Web and where necessary the performance of HPCC software. As we propose to start with Web software as the baseline, this strategy implies that one can confine HPCC software development to providing high performance data transmission with all of the complex service provision inherited naturally from the Web.
Javabean Communication Model
We note that Javabeans (which are one natural basis of implementing program modules in our approach) provide a rich communication mechanism, which supports the separation of control (handshake) and implementation. As shown below in figure 5, Javabeans use the JDK 1.1 AWT event model with listener objects and a registration/call-back mechanism.
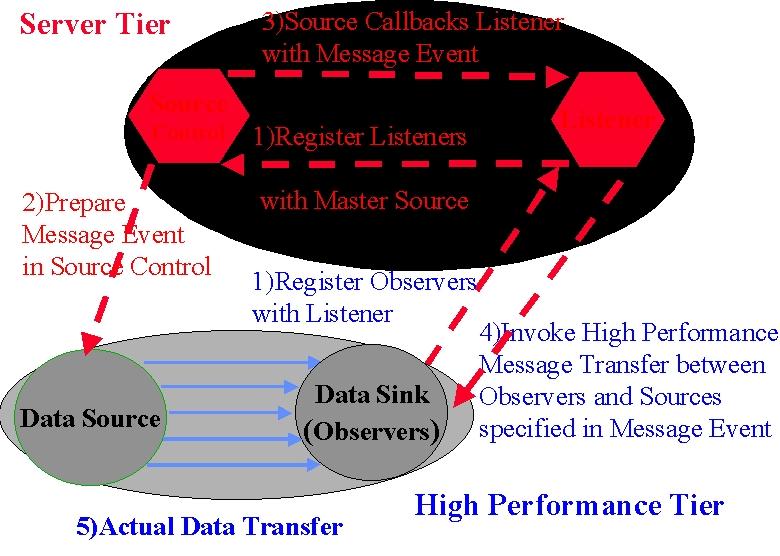
Figure 5: JDK 1.1 Event Model used by (inter alia) Javabeans
Javabeans communicate indirectly with one or more "listener objects" acting as a bridge between the source and sink of data. In the model described above, this allows a neat implementation of separated control and explicit communication with listeners and control objects residing in middle tier. They decide if high performance is necessary or possible and invoke the specialized HPCC layer. This approach can be used to advantage in "run-time compilation" and resource management with execution schedules and control logic in the middle tier and libraries such as MPI, PCRC and CHAOS implementing the determined data movement. Parallel I/O and "high-performance" CORBA can also use this architecture. In general, this listener model of communication provides the essential virtualization of communication that allows a separation of control and data transfer that is largely hidden from the user and the rest of the system. Note that current Internet security systems (such as SSL and SET) use public keys in the control level but secret key cryptography in bulk data transfer. This is another illustration of the proposed hybrid multi-tier communication mechanism.
Web Collaboration Mechanisms
The Java Server model for the middle tier naturally allows one to integrate collaboration into the computing model and our approach allow one to "re-use" collaboration systems built for the general Web market. Thus one can without any special HPCC development, address areas such as computational steering and collaborative design, which require people to be integrated with the computational infrastructure. In fig. 6, we define collaborative systems as integrating client side capabilities together. In steering, these are people with analysis and visualization software. In engineering design, one would also link design (such as CATIA or Autocad) and planning tools. In both cases, one would need the base collaboration tools such as white-boards, chat rooms and audio-video conferencing.
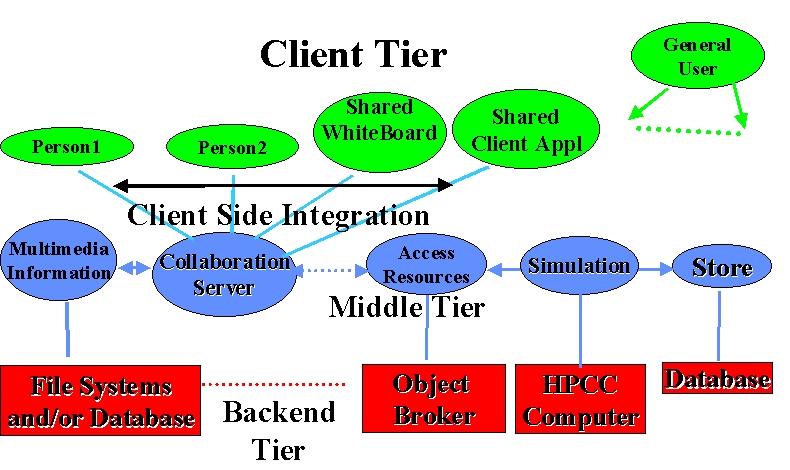
Figure 6: Collaboration in the 3 tier computing model. Typical clients (on top right) are independent but Java collaboration systems link multiple clients.
If we are correct in viewing collaboration as client-side integration, the 3 tier model naturally separates HPCC and collaboration and allows us to integrate into the HPCC environment, the very best Web technology which is likely to come from larger fields such as business or (distance) education.
Note: Reference collaboration and high-end visualization chapter here.
NPAC has developed two systems TANGO and WebFlow, which illustrate some of these points nicely. Both use Java servers for their middle tier level. TANGO that is for our crude discussion essentially identical to NCSA's Habanero provides collaboration services as in fig. 6. Client side applications are replicated using an event distribution model and to put a new application into TANGO one must be able to define both its absolute state and changes therein. Using Java object serialization or similar mechanisms, this state is maintained identically in the linked applications. On the other hand, WebFlow can be thought of a Web version of AVS or Khoros and as in figs. 3 and 4 integrates program modules together using a dataflow paradigm. Now the module developer must define data input and output interfaces and handling programs but normally there would be need to replicate the state of module.
The Object Web and Distributed Simulation
The emergence of IIOP (Internet Inter-ORB Protocol), CORBA2, and the realization that CORBA is naturally synergistic with Java is starting a new wave of "Object Web" developments that could have profound importance. Java is not only a good language to build brokers but also Java objects are the natural inhabitants of object databases. The resultant architecture in fig. 7 shows a small object broker (a so-called ORBlet) in each browser as in Netscape's current plans.
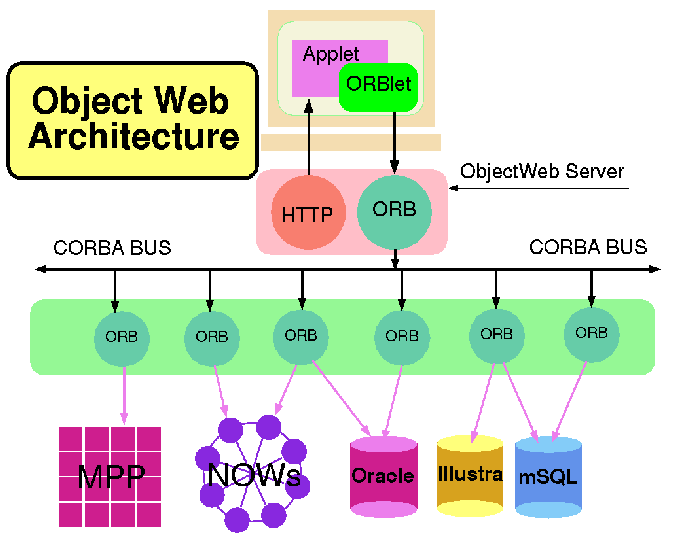
Figure 7: Integration of Object Technologies (CORBA) and the Web
Note: we will evolve this section once we see what is covered in Gannon-Grimshaw chapter.
The integration of HPCC with distributed objects provides an opportunity to link the classic HPCC ideas with those of DoD's distributed simulation DIS or Forces Modeling FMS community. The latter do not make extensive use of the Web these days but they appear to have a commitment to CORBA with their HLA (High Level Architecture) and RTI (Runtime Infrastructure) initiatives. The Naval postgraduate school at Monterey has built some interesting web-linked DIS prototypes. However distributed simulation is traditionally built with distributed event driven simulators managing C++ or equivalent objects. We suggest that the object web (and parallel and distributed ComponentWare) is a natural convergence point for HPCC and DIS/FMS. This would provide a common framework for time stepped and event driven simulations. Further it will allow one to more easily build systems that integrate these concepts as is needed in many major DoD projects -- as exemplified by FMS and IMT CHSSI projects.
HPCC ComponentWare
HPCC does not have a good reputation for the quality and productivity of its programming environments. Indeed one of the difficulties with adoption of parallel systems, is the rapid improvement in performance of workstations and recently PC's with much better development environments. Parallel machines do have a clear performance advantage but this for many users, this is more than counterbalanced by the greater programming difficulties. There are two major reasons for the lower quality of HPCC software. Firstly parallelism is intrinsically hard to find and express. Secondly the PC and workstation markets are substantially larger than HPCC and so can support a greater investment in attractive software tools such as the well-known PC visual programming environments. The Web revolution offers an opportunity for HPCC to produce programming environments that are both more attractive than current systems and further are much more competitive with those of the PC and workstation world. Firstly the latter must face some difficult issues as they move to a distributed environment which has challenges where in some cases the HPCC community has substantial expertise. Secondly as described above, we claim that HPCC can leverage the huge software investment of these larger markets.
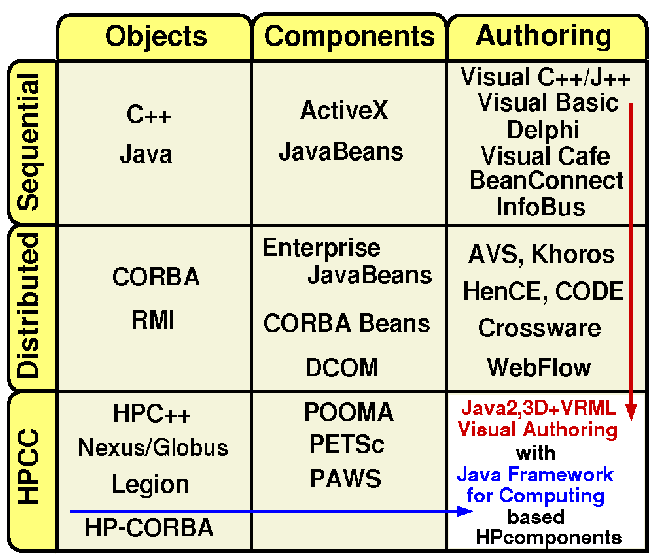
Figure 8: System Complexity (vertical axis) versus User Interface (horizontal axis) tracking of some technologies
In fig. 8, we sketch the state of object technologies for three levels of system complexity -- sequential, distributed and parallel and three levels of user (programming) interface -- language, components and visual. Industry starts at the top left and moves down and across the first two rows. Much of the current commercial activity is in visual programming for sequential machines (top right box) and distributed components (middle box). Crossware (from Netscape) represents an initial talking point for distributed visual programming. Note that HPCC already has experience in parallel and distributed visual interfaces (CODE and HenCE as well as AVS and Khoros). We suggest that one can merge this experience with Industry's object Web deployment and develop attractive visual HPCC programming environments. Currently NPAC's WebFlow system uses a Java graph editor to compose systems built out of modules. This could become a prototype HPCC ComponentWare system if it is extended with the modules becoming Javabeans and the integration with CORBA. Note the linkage of modules would incorporate the generalized communication model of fig. 5. Returning to fig. 1, we note that as industry moves to distributed systems, they are implicitly taking the sequential client-side PC environments and using them in the much richer server (middle-tier) environment which traditionally had more closed proprietary systems.
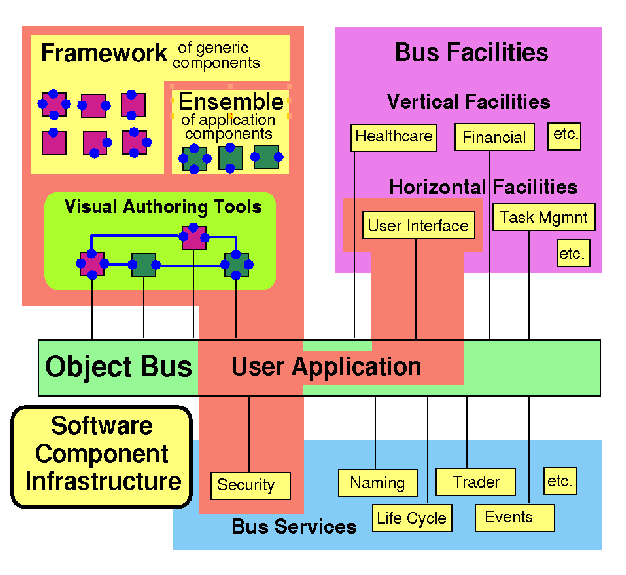
Figure 9:Visual Authoring with Software Bus Components
We will then generate an environment such as fig. 9 including object broker services, and a set of horizontal (generic) and vertical (specialized application) frameworks. These represent a combination of library and interfaces and are illustrated by the set of announced Java frameworks (Applet, Enterprise (includes database and CORBA), security, commerce, media and Javabeans). We have suggested that it would be useful to establish a set of frameworks for computing in the same spirit. These could define common interfaces to backend services needed by users, compilers, debuggers, resource managers etc. (see http://www.sis.port.ac.uk/~mab/Computing-FrameWork/ ). An important initial activity is to evolve Java and if necessary its virtual machine (VM) to better support scientific computing. (http://www.npac.syr.edu/projects/javaforcse/june21summary.html)
We do not have much experience with an environment such as fig. 9, but suggest that HPCC could benefit from its early deployment without the usual multi-year lag behind the larger industry efforts for PC's. Further the diagram implies a set of standardization activities (establish frameworks) and new models for services and libraries that could be explored in prototype activities.