 Resource
Management and Scheduling
Resource
Management and Scheduling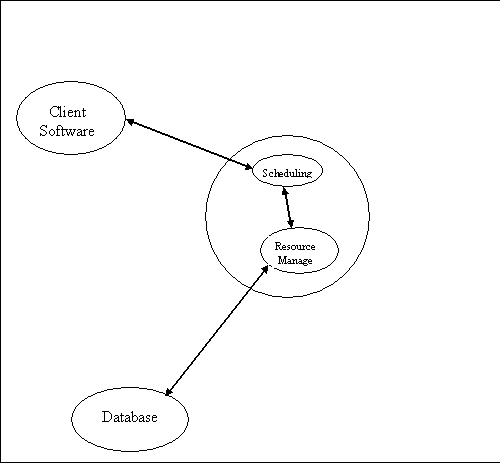
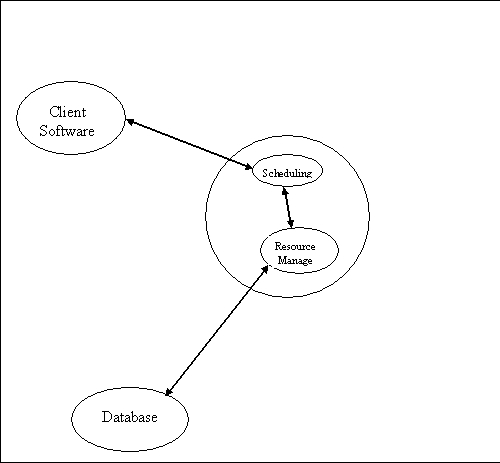
In its simplest form RM/S can be viewed as consisting of three Client/Middleware/Backend models.
1) Client Software <-> Schedular
2) Schedular <-> Resource manager
3) Resource manager <-> Resouce database
With <-> representing some form of middleware software and protocol.
Model 1)
In this first model the client software can be either native, for example, an LSF client running under an LSF managed domain. Or, it could be an alien, where a foreign client (Codine) wants to interact with, for example, an LSF managed domain.
Traditionally, the "de facto" protocol that was used between the client
and server software was NQS (I will look
up the services that NQS provided - mab). More recently, vendors have
created a super set of NQS (non-standard, but has basic NQS functionality)
or a totally proprietary protocols have been implemented.
Model 2)
This model is part of EASY-LL. It was formed so that the EASY schedular
could be married with the resource management part of LoadLever.
The protocol between the schedular and resource manager is an open API.
I feel that it is not important as part of this talk, perhaps it should
be mentioned in the paper as it is important in that it enables the client
software (schedular) to be plugged into any resource management software
(LL, Codine or whatever). Which, in itself, is what
we will be discussing.
Model 3)
This model is just a client accessing a database and even though most venors do not use JDBC at the moment I would imagine that they will at some stage soon. It is as per MetaWeb, the resouce management software needs to interact with a database of dynamic resouce utilisation and configuration information.
Other comments:
Another element can obviously be added into our scenario, that of the
actual user interface. Here there will be an xterm/motif-window/browser
communicating with the client software. The protocol that it uses to communcate
with the client software should be the same as that used to communicate
with the schedular.