If we can easily compute an arbitrary element of the sequence, we can also parallelize the algorithm by splitting it into contiguous sub-sequences separated by a large distance D, one on each processor. For instance, D could be the period divided by the number of processors. Splitting into N such sequences for N processors will mean that
Processor 1 has sequence 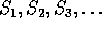
Processor 2 has sequence 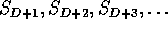
Processor k has sequence 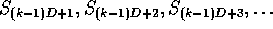
This method will give the same results on different processors if we take N to be the number of abstract (rather than physical) processors. i.e. the number of elements in a data parallel array.