For the Swendsen-Wang cluster algorithm, all sites need to calculate their cluster labels, so can use standard domain decomposition.
The measurements can be done in parallel, just as for Metropolis.
Updating the spins can easily be done in parallel,
as can setting up the bonds --- all the sites just look at their
nearest neighbors in the positive directions, and put a bond between them
with probability
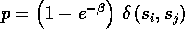 for
the Potts model.
for
the Potts model.
The only difficult problem in parallel is the connected component labeling, that is, assigning to all the sites a cluster label that is unique for each cluster. So implementing an efficient parallel Swendsen-Wang cluster algorithm is basically equivalent to the problem of implementing an efficient parallel connected component labeling algorithm.