 206 i.e 26*(N+1) broker nodes to be present in the
system.
206 i.e 26*(N+1) broker nodes to be present in the
system.
|
Abstract
We believe that it is interesting to study the system and software architecture of environments which integrate the evolving ideas of computational grids, distributed objects, web services, peer-to-peer networks and message oriented middleware. Such peer-to-peer (P2P) Grids should seamlessly integrate users to themselves and to resources which are also linked to each other. We can abstract such environments as a distributed system of "clients" which consist either of "users" or "resources" or proxies thereto. These clients must be linked together in a flexible fault tolerant efficient high performance fashion. In this paper, we study the messaging or event system - termed GES or the Grid Event Service - that is appropriate to link the clients (both users and resources of course) together. For our purposes (registering, transporting and discovering information), events are just messages - typically with time stamps. The messaging system GES must scale over a wide variety of devices - from hand held computers at one end to high performance computers and sensors at the other extreme. We have analyzed the requirements of several Grid services that could be built with this model, including computing and education and incorporated constraints of collaboration with a shared event model. We suggest that generalizing the well-known publish-subscribe model is an attractive approach and here we study some of the issues to be addressed if this model is used in the GES. |
The web in recent years has experienced an explosion in the number of devices users employ to access services. A single user may access a certain service using multiple devices. Most services allow clients to access the service through a broker. The client is then forced to interact with the service via this broker throughout the duration that it is using the service. If the broker fails, the client is denied servicing till such that the failed broker recovers. In the event that this service is running on a fixed set of brokers the client, since it knows about this set of brokers, could then connect to one of these brokers and continue using the service. Whether the client missed any servicing and whether the service would notify the client of this missed servicing depends on the implementation of the service. In all these implementations the identity of the broker that the client connects to is just as important as the service itself. Clients do not always maintain an online presence, and when they are online they may the access the service using a different device with different computing and content-handling capabilities. The communication channels employed during every such service interaction may have different bandwidth constraints and communication latencies. Besides this a client accesses services from different geographic locations.
A truly distributed service, would allow a client to use services by connecting to a broker nearest to the client's geographical location. By having such local broker, a client does not have to re-connect all the way back to the broker that it was last attached to. If the client is not satisfied with the response times that it experiences or if the broker that it has connected to fails, the client could very well choose to connect to some other local broker. Concentration of clients from a specific location accessing a remote broker, leads to very poor bandwidth utilization and affects latencies associated with other services too. Also it should not be assumed that a failed broker node would recover within a finite amount of time. Stalling operations for certain sections of the network, and denying service to clients while waiting for failed processes to recover could result in prolonged, probably interminable waits. Such a model potentially forces every broker to be up and running throughout the duration that this service is being provided. Models that require brokers to recover within a finite amount of time generally imply that each broker has some state. Recovery for brokers that maintain state involves state reconstruction, usually involving a calculation of state from the neighboring brokers. This model runs into problems when there are multiple neighboring broker failures. Invariably brokers get overloaded, and act as black holes where messages are received but no processing is performed. By ensuring that the individual brokers are stateless (as far as the servicing is concerned), we can allow these brokers to fail and not recover. A failure model that does not require a failed node to recover within a finite amount of time, allows us to purge such slow processes and still provide the service while eliminating a bottleneck.
What is indispensable is the service that is being provided and not the brokers which are cooperating to provide the service. Brokers can be continuously added or fail and the broker network can undulate with these additions and failures of brokers. The service should still be available for clients to use. Brokers thus do not have an identity - any one broker should be just as good as the other. Clients however have an identity, and their service needs are very specific and vary from client to client. Any of these brokers should be able to service the needs of every one of these millions and millions of clients. It's the system as a whole, which should be able to reconstruct the service nuggets that a client missed during the time that it was inactive. Clients just specify the type of events that they are interested in, and the content that the event should at least contain. Clients do not need to maintain an active presence during the time these interesting events are taking place. Once it registers an interest it should be able to recover the missed event from any of the broker nodes in the system. Removing the restriction of clients reconnecting back to the same broker that it was last attached to and the departure from the time-bound recovery failure model, leads to a situation where brokers could be dynamically instantiated based on the concentration of clients at certain geographic locations. Clients could then be induced to roam to such dynamically created brokers for optimizing bandwidth utilization. The network can thus undulate with the addition and failure/purging of broker node processes.
The system we are considering needs to support communications for 109 devices. The users using these devices would be interested in peer-to-peer (P2P) style of communication, business-to-business (B2B) interaction or a system comprising of agents where discoveries are initiated for services from any of these devices. Finally, some of these devices could also be used as part of a computation. The devices are thus part of a complex distributed system. Communication in the system is through events, which are encapsulated within messages. Events form the basis of our design and are the most fundamental units that entities need to communicate with each other. Events are anything transmitted including updates, objects themselves (file uploads), database updates and audio/video streams. These events encapsulate expressiveness at various levels of abstractions - content, dependencies and routing. Where, when and how these events reveal their expressive power is what constitutes information flow within our system. Clients provide services to other clients using events. These events are routed by the system based on the service advertisements that are contained in the messages published by the client. Events routed to a broker are queued and routing decisions are made based on the service advertisements contained in these events and also based on the state of the network fabric.
We believe that it is interesting to study the system and software architecture of environments which integrate the evolving ideas of computational grids, distributed objects, web services, peer-to-peer networks and message oriented middleware. Such peer-to-peer (P2P) Grids should seamlessly integrate users to themselves and to resources which are also linked to each other. We can abstract such environments as a distributed system of "clients" which consist either of "users" or "resources" or proxies thereto. These clients must be linked together in a flexible fault tolerant efficient high performance fashion. In this paper, we study the messaging or event system - termed GES or the Grid Event Service - that is appropriate to link the clients (both users and resources of course) together. For our purposes (registering, transporting and discovering information), events are just messages - typically with time stamps. The messaging system GES must scale over a wide variety of devices - from hand held computers at one end to high performance computers and sensors at the other extreme. We have analyzed the requirements of several Grid services that could be built with this model, including computing and education and incorporated constraints of collaboration with a shared event model. We suggest that generalizing the well-known publish-subscribe model is an attractive approach and here we study some of the issues to be addressed if this model is used in the GES.
Here we study an advanced publish/subscribe mechanism for GES which goes beyond JMS and other operational publish/subscribe systems in many ways. A basic JMS environment has a single server (although by linking multiple JMS invocations you can build a multi-server environment and you can also implement the function of a JMS server on a cluster). We propose that GES be implemented on a network of brokers where we avoid the use of the term servers for two reasons; the publish/subscribe broker service could be implemented on any computer - including a users desktop machine. Secondly we have included the many application servers needed in a P2P Grid as clients in our abstraction for they are the publishers and subscribers to many of the events to be serviced by the GES. Brokers can run on either on separate machines or on clients whether these are associated with users or resources. This network of brokers will need to be dynamic for we need to service the needs of dynamic clients. For example suppose one started a distance education session with six distributed classrooms each with around 20 students; then the natural network of brokers would have one for each classroom (created dynamically to service these clusters of clients) combined with static or dynamic brokers associated with the virtual university and perhaps the particular teacher in charge.
Here we study the architecture and characteristics of the broker network. We are using a particular internal structure for the events (defined in XML but currently implemented as a Java object). Further we assume a sophisticated matching of publishers and subscribers defined as general topic objects (defined by an XML Schema that we have designed). However these are not the central issues to be discussed here. Our study should be useful whether events are defined and transported in Java/RMI or XML/SOAP or other mechanisms; it does not depend on the details of matching publishers and subscribers. Rather, we are interested in the capabilities needed in any implementation a GES in order to abstract the broker system in a scalable hierarchical fashion (section 2); the delivery mechanism (section 3); the guarantees of reliable delivery whether brokers crash or disappear or whether clients leave or (re)join the system (section 4). This section also discusses persistent archiving of the event streams. We have emphasized the importance of dynamic creation of brokers but this was not implemented in our initial prototype. However by looking at the performance of our system with different static broker topologies we can study the impact of dynamic creation and termination of broker services.
In this section we outline the destinations that are associated with an event. We discuss the connection semantics for any client within the system, and also present our rationale for a distributed model in implementing the solution. We then present our scheme for the organization of the broker network, and the nomenclature that we would be referring to in the remainder of this paper.
An example of an internal destination list is "Mail" where the recipients are clearly stated. Examples of external destination lists include sports score, stock quotes etc. where there is no way for the issuing client to be aware of the destination lists. External destination lists are a function of the system and the types of events that the clients, of the system, have registered their interest in.
Associated with every clients is its profile, which keeps track of information pertinent to the client. This includes the application type., events the client is interested in and the broker node the client was attached to in its previous incarnation.
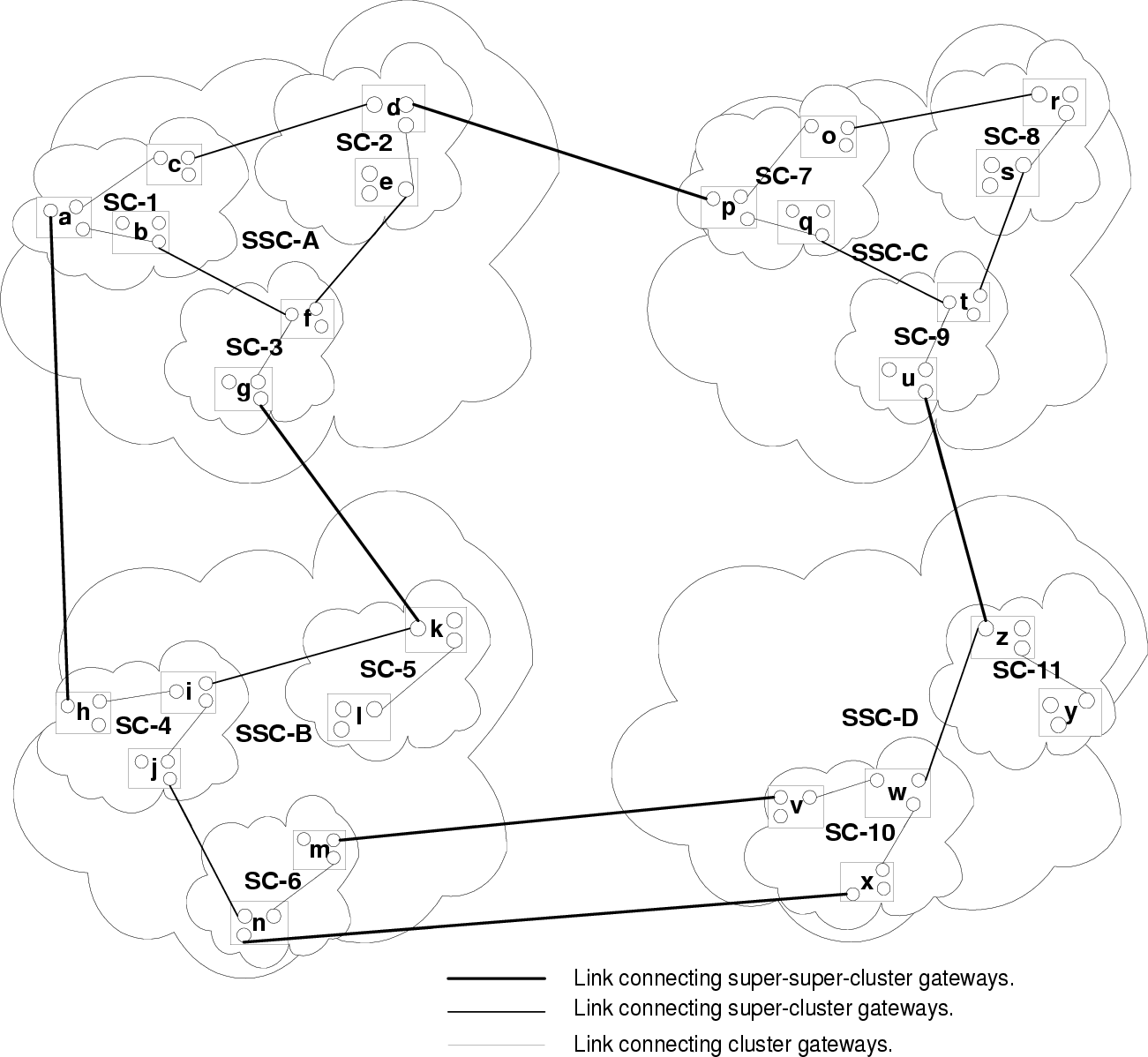
Several such clusters grouped together as an entity comprises a level-2 unit of our network and is referred to as a
super-cluster. Clusters within a super-cluster have one or more links with at least one of the other clusters
within that super-cluster. When we refer to the links between two clusters, we are referring to the
links connecting the nodes in those individual clusters. In general there would be multiple links
connecting a single cluster to several other clusters. This approach provides us with a greater degree of
fault-tolerance, by providing us with multiple routes to reach nodes within other clusters. This
topology could be extended in a similar fashion to comprise of super-super-clusters (level-3 units),
super-super-super-clusters (level-4 units) and so on. A client thus connects to a broker node, which is part of a
cluster, which in turn is part of a super-cluster and so on and so forth. We limit the number of
super-clusters within a super-super-cluster, the number of clusters within a super cluster and the
number of nodes within a cluster. This limit, the block-limit, is set at 64. In an N-level system
this scheme allows for 2N6 × 2N - 16 × 206 i.e 26*(N+1) broker nodes to be present in the
system.
We now delve into the small world graphs introduced in [44] and employed for the analysis of real world peer-to-peer systems in [34, pages 207 - 241]. In a graph comprising several nodes, pathlength signifies the average number of hops that need to be taken to reach from one node to the other. Clustering coefficient is the ratio of the number of connections that exist between neighbors of node and the number of connections that are actually possible between these nodes. For a regular graph consisting of n nodes, each of which is connected to its nearest k neighbors - for cases where n » k » 1, the pathlength is approximately n/2k. As the number of vertices increases to a large value the clustering coefficient in this case approaches a constant value of 0.75.
At the other end of the spectrum of graphs is the random graph, which is the opposite of a regular graph. In the random graph case the pathlength is approximately log n/ log k, with a clustering coefficient of k/n. The authors in [44] explore graphs where the clustering coefficient is high, and with long connections (inter-cluster links in our case). They go on to describe how these graphs have pathlengths approaching that of the random graph, though the clustering coefficient looks essentially like a regular graph. The authors refer to such graphs as small world graphs. This result is consistent with our conjecture that for our broker node network, the pathlengths will be logarithmic too. Thus in the topology that we have the cluster controllers provide control to local classrooms etc, while the links provide us with logarithmic pathlengths and the multiple links, connecting clusters and the nodes within the clusters, provide us with robustness.
 at level exists within the GES context Cj + 1 of a level ( + 1) unit. In an N-level
system, a unit at level can be uniquely identified by (N - ) GES context identifiers of each of the
higher levels. Of course, the units at any level within a GES context Ci + 1 should be able to
reach any other unit within that same level. If this condition is not satisfied we have a network
partition.
at level exists within the GES context Cj + 1 of a level ( + 1) unit. In an N-level
system, a unit at level can be uniquely identified by (N - ) GES context identifiers of each of the
higher levels. Of course, the units at any level within a GES context Ci + 1 should be able to
reach any other unit within that same level. If this condition is not satisfied we have a network
partition.
Let us consider a connection, which exists between nodes in a different cluster, but within the same super-cluster. In this case the nodes that maintain this connection have different GES cluster contexts i.e. their contexts at level-1 are different. These nodes are thus referred to as gatekeepers at level-1. Similarly, we would have connections existing between different super-clusters within a super-super-cluster GES context Ci3. In an N-level system gatekeepers would exist at every level within a higher GES context. The link connecting two gatekeepers is referred to as the gateway, which the gatekeepers provide, to the unit that the other gatekeeper is a part of.
+ 1 but have differing GES contexts Cj, Ck, the nodes are designated as
gatekeepers at level - i.e. g (C+1). Thus, in figure 1 we have 12 super-super-cluster gatekeepers, 18
super-cluster gatekeepers (6 each in SSC-A and SSC-C, 4 in SSC-B and 2 in SSC-D) and 4
cluster-gatekeepers in super-cluster SC-1.
(C+1). Thus, in figure 1 we have 12 super-super-cluster gatekeepers, 18
super-cluster gatekeepers (6 each in SSC-A and SSC-C, 4 in SSC-B and 2 in SSC-D) and 4
cluster-gatekeepers in super-cluster SC-1.
The event delivery problem is one of routing events to clients based on the type of events that clients are interested in. Events need to be relayed through the broker network prior to being delivered to clients. The dissemination process should efficiently deliver events to the destinations, which could be internal or external to the event. In the latter case the system needs to compute the destination lists pertaining to the event. The system merely acts as a conduit to efficiently route the events from the issuing client to the interested clients. A simple approach would be to route all events to all clients, and have the clients discard those events that they are not interested in. This approach would however place a strain on network resources. Under conditions of high load and increasing selectivity by the clients, the number of events that a client discards would far exceed the number of events it is actually interested in. This scheme also affects the latency associated with the reception of real time events at the client. The increase in latency is due to the cumulation of queuing delays associated with the uninteresting/flooded events. The system thus needs to be very selective of the kinds of events that it routes to a client.
The approach adopted by the OMG [33] is one of establishing channels and registering suppliers and consumers to those event channels. The channel approach in the event service [32] approach could entail clients (consumers) to be aware of a large number of event channels. The two serious limitations of event channels are the lack of event filtering capability and the inability to configure support for different qualities of service. These are sought to be addressed in the Notification Service [31] design. However the Notification service attempts to preserve all the semantics specified in the OMG event service, allowing for interoperability between Event service clients and Notification service clients. Thus even in this case a client needs to subscribe to more than one event channel. In TAO [25], a real-time event service that extends the CORBA event service is available. This provides for rate-based event processing, and efficient filtering and correlation. However even in this case the drawback is the number of channels that a client needs to keep track of.
In some commercial JMS implementations, events that conform to a certain topic are routed to the interested clients. Refinement in subtopics is made at the receiving client. For a topic with several subtopics, a client interested in a specific subtopic could continuously discard uninteresting events addressed to a different subtopic. This approach could thus expend network cycles for routing events to clients where it would ultimately be discarded. Under conditions where the number of subtopics is far greater than the number of topics, the situation of client discards could approach the flooding case.
In the case of servers that route static content to clients such as Web pages, software downloads etc. some of these servers have their content mirrored on servers at different geographic locations. Clients then access one of these mirrored sites and retrieve information. This can lead to problems pertaining to bandwidth utilization and servicing of requests, if large concentrations of clients access the wrong mirrored-site. In an approach sometimes referred to as active mirroring, websites powered by EdgeSuite [13] from Akamai, redirect their users to specialized Akamized URLs. EdgeSuite then accurately identifies the geographic location from which the clients have accessed the website. This identification is done based on the IP addresses associated with the clients. Each client is then directed to the server farm that is closest to the client's network point of origin. As the network load and server loads change clients could be redirected to other servers.
connection is established, the
connection information is disseminated only within the higher level GES context Ci + 1 of the sub-system that
the gatekeepers are a part of. Thus, connections established between broker nodes in a cluster are not
disseminated outside that cluster.
When the connection information is being disseminated throughout the GES context Ci + 1, it arrives at
gatekeepers at various levels. Depending on the kind of link this information is being sent over, the information
contained in the connection is modified. Details regarding the information encapsulated in a connection, the
update of this information during disseminations and the enforcement of dissemination constraints can be found
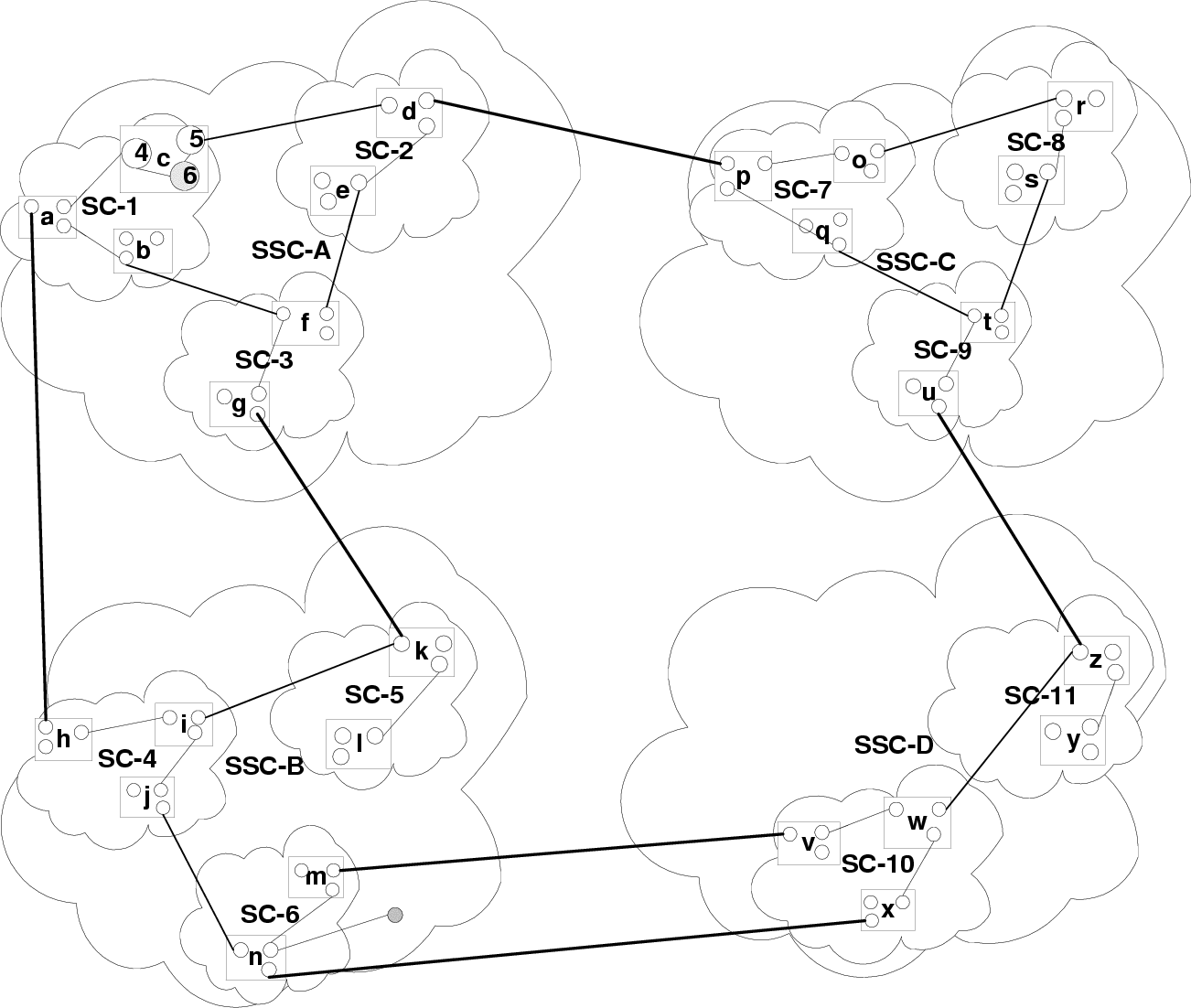
in [38, 37, 35]. Thus, in figure 2 the connection between SC-2 and SC-1 in SSC-A, is disseminated as one
between node 5 and SC-2. When this information is received at 4, it is sent over as a connection between the
cluster c and SC-2. When the connection between cluster c and SC-2 is sent over the cluster gateway to
cluster b, the information is not updated. As was previously mentioned, the super cluster connection
(SC-1,SC-2) information is disseminated only within the super-super-cluster SSC-A and is not
sent over the super-super-cluster gateway available within the cluster a in SC-1 and cluster g in
SC-3.
Every edge created due to the dissemination of connection information also has a link count associated with
it, which is incremented by one every time a new connection is established between two units that were already
connected. This scheme also plays an important role in determining if a connection loss would
lead to partitions. Further, associated with every edge is the cost of traversal. In general the cost
associated with traversing a level- link from a unit ux increases with increasing values of both x and .
This cost scheme is encapsulated in the link cost matrix, which can be dynamically updated to
reflect changes in link behavior. Thus, if a certain link is overloaded, we could increase the cost
associated with traversal along that link. This check for updating the link cost could be done every few
seconds.
The first node in the connectivity graph is the vertex node, which is the level-0 broker node hosting the
connectivity graph. The nodes within the connectivity graph are organized as nodes at various
levels. A graph node k at level in the connectivity graph is denoted as nk. Associated with every
level- node in the graph are two sets of links, the set LUL, which comprises of connections to nodes
nia 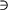 a < and LD with connections to nodes nib b > . When a connection is received at a
node, the node checks to see if either of the graph nodes (representing the corresponding units at
different levels) is present in the connectivity graph. If any of the units within the connection is
not present in the connectivity graph, the corresponding graph node is added to the connectivity
graph.
a < and LD with connections to nodes nib b > . When a connection is received at a
node, the node checks to see if either of the graph nodes (representing the corresponding units at
different levels) is present in the connectivity graph. If any of the units within the connection is
not present in the connectivity graph, the corresponding graph node is added to the connectivity
graph.
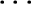 , an}. The values these attributes can take are dictated and
constrained by the type of the attribute. Clients within the system that issue these events, assign values to these
attributes. The values these attributes take comprise the content of the event. All clients are not interested in all
the content, and are allowed to specify a filter on the content that is being disseminated within the system.
Thus a filter allows a client to register its interest in a certain type of content. Of course one can
employ multiple filters to signify interest in different types of content. These filters specified by the
client constitutes its profile. The organization of these profiles, dictates the efficiency of matching
content.
, an}. The values these attributes can take are dictated and
constrained by the type of the attribute. Clients within the system that issue these events, assign values to these
attributes. The values these attributes take comprise the content of the event. All clients are not interested in all
the content, and are allowed to specify a filter on the content that is being disseminated within the system.
Thus a filter allows a client to register its interest in a certain type of content. Of course one can
employ multiple filters to signify interest in different types of content. These filters specified by the
client constitutes its profile. The organization of these profiles, dictates the efficiency of matching
content.
We use the general matching algorithm, presented in [1], of the Gryphon system to organize profiles and match
the events. Constraints from multiple profiles are organized in the profile graph. Every attribute on which a
constraint is specified constitutes a node in the profile graph. When a constraint is specified on an attribute ai,
the attributes a1, a2, 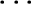 , ai-1 appear in the profile graph. A profile comprises of constraints on
successive attributes in an event's signature. The nodes in the profile graph are linked in the order
that the constraints have been specified. Any two successive constraints in a profile result in an
edge connecting the nodes in the profile graph. Depending on the kinds of profiles that have been
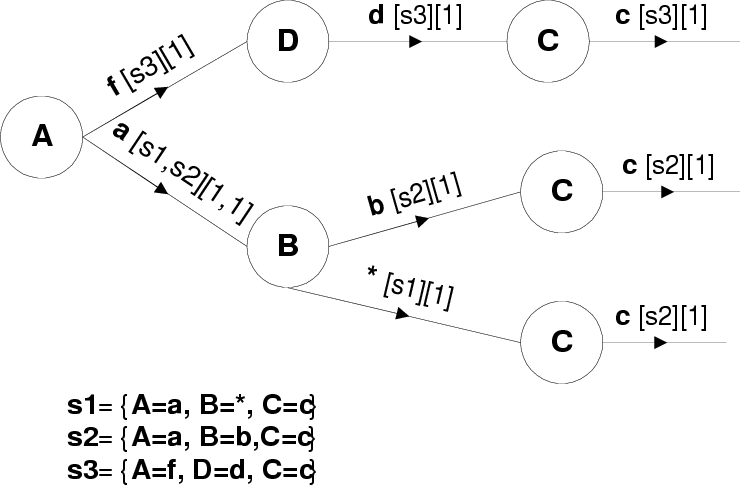
specified by clients, there could be multiple edges, originating from a node. Figure 4 depicts the
profile graph constructed from three different profiles. The example depicts how some of the profiles
share partial constraints between them, some of which result in profiles sharing edges in the profile
graph.
, ai-1 appear in the profile graph. A profile comprises of constraints on
successive attributes in an event's signature. The nodes in the profile graph are linked in the order
that the constraints have been specified. Any two successive constraints in a profile result in an
edge connecting the nodes in the profile graph. Depending on the kinds of profiles that have been
specified by clients, there could be multiple edges, originating from a node. Figure 4 depicts the
profile graph constructed from three different profiles. The example depicts how some of the profiles
share partial constraints between them, some of which result in profiles sharing edges in the profile
graph.
Along every edge we maintain information regarding the units that are interested in its traversal. For each of
these units we also maintain the number of predicates 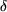
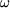 within that unit that are interested in the traversal
of that edge. The first time an edge is created between two constraints as a result of the profile
specified by a unit, we add the unit to the route information maintained along the edge. For a new
profile new added by a unit, if two of its successive constraints already exist in the profile graph,
we simply add the unit to the existing routing information associated with the edge. If the unit
already exists in the routing information, we increment the predicate count associated with that
destination.
within that unit that are interested in the traversal
of that edge. The first time an edge is created between two constraints as a result of the profile
specified by a unit, we add the unit to the route information maintained along the edge. For a new
profile new added by a unit, if two of its successive constraints already exist in the profile graph,
we simply add the unit to the existing routing information associated with the edge. If the unit
already exists in the routing information, we increment the predicate count associated with that
destination.
per unit that are interested in two successive
constraints allows us to remove certain edges and nodes from the profile graph, when no clients
are interested in the constraints any more. Figure 4 provides a simple example of the information
maintained along the edges. When an event comes in we first check to see if the profile graph contains
the first attribute contained in the event. If that is the case we can proceed with the matching
process. When an event's content is being matched, the traversal is allowed to proceed only if
-
As an event traverses the profile graph, for each destination edge that is encountered if the event satisfies the destination edge constraint, that destination is added to the destination list associated with the event.
changes+1 compute destination lists for the u units that it serves as a
g+1 for. A cluster gatekeeper would maintain profiles of all the broker nodes contained with that
cluster. A gatekeeper g+1 should thus maintain information regarding the profile graphs at each of
the u units. Profile graph Pi + 1 maintains information contained in profiles P at all the u
units within ui + 1. This should be done so that when an event arrives over a g+1 in ui + 1
-
's, are those with content such that at least one
destination exists for those events within the sub-units that comprise the profile for u.
, with content such that ui would have had a
destination within the sub-units whose profile it maintains.Properties (a) and (b) ensure that the events routed to a unit, are those that have at least one client interested in the content contained in the event.
For profile changes that result in a profile change of the unit, the changes need to be propagated to relevant nodes, that maintain profiles for different levels. A cluster gateway snapshots the profile of all clients attached to any of the broker nodes that are a part of that cluster. The change in profile of the broker node should in turn be propagated to the cluster gateway(s) within the cluster that the node is a part of. A profile change in broker (as a result of a change in an attached client's profile) needs to be propagated to the unit (cluster, super-cluster, etc) gatekeeper within the unit that the broker is a part of. In general the gatekeepers to which the profile changes need to be propagated are computed as follows --
) node in the connectivity graph.
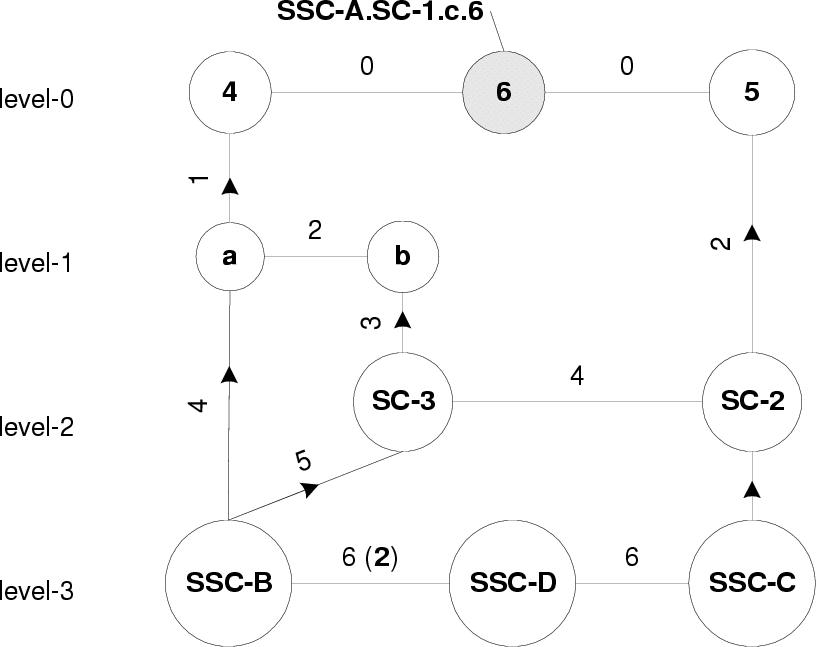
gateway at the unit corresponding to the graph node.This scheme provides us with information regarding the level- gateway, within the part of the system that we are
interested in. In the connectivity graph depicted in figure 3 any 0 changes at any of the nodes within cluster
c, need to be routed to node 4. Any 1 changes at node 4 need to be routed to node 5, and also to a
node in cluster b. Similarly 2 changes at node 5 needs to be routed to the level-3 gatekeeper
in cluster a and superclusters SC-3, SC-2. When such propagations reach any unit/super-unit
the process is repeated till such time that the gateway that the node seeks to reach is reached.
Every profile change has a unique-id associated it, which aids in ensuring that the reference count
scheme does not fail due to delivery of the same profile change multiple times within the same
unit.
Prior to routing an event across the gateway a level- gatekeeper takes the following sequence of actions
-
routing information for the event to determine if the event has already been
consumed by the unit at level-. If this is the case the event will not be sent over the gateway to
that unit.
When a gatekeeper g with GES context Ci is presented with an event it computes the u-1's within Ci
that the event must be routed to. A cluster gatekeeper, when it receives an event, computes the broker
destinations associated with that event. This calculation is based on the profiles available at the gatekeeper as
outlined in the profile propagation protocol. At every node the best hops to reach the destinations are
computed. Thus, at every node the best decision is taken. Nodes and links that have not been failure suspected
are the only entities that can be part of the shortest path. The event routing protocol, along with the profile
propagation protocol and the gateway information ensure the optimal routing scheme for the dissemination of
events in the existing topology.
Reliable delivery involves the guaranteed delivery of events to intended recipients. The delivery guarantees need to be satisfied even in the presence of single or multiple broker failures, link failures and network partitions. In GES clients need not maintain an active online presence and can also roam the network attaching themselves to any of the nodes in the broker network. Events missed by clients in the interim need to be delivered to these clients irrespective of the failures that have or are currently present in the system.
Systems such as Sienna [12, 11] and Elvin [43, 21, 42] focus on efficiently disseminating events, and do not sufficiently address the reliable delivery problem in the presence of failures. In Gryphon the approach to dealing with broker failures is one of reconstructing the broker state from its neighboring brokers. This approach requires a failed broker to recover within a finite amount of time, and recover its state from the brokers that it was attached to prior to its failure. SmartSockets [16] provides high availability/reliability through the use of software redundancies. Mirror processes receiving the same data and performing the same sequence of actions as the primary process, allows for the mirror process to take over in the case of process failures. The mirror process approach runs into scaling problems as the number of processes increase, since each process needs to have a mirror process. Since there is an entire server network that would be mirrored in this approach the network cycles expended for dissemination also increases as the number of server nodes increases. SmartSockets also allows for routing tables to be updated in real time in response to link failures and process failures. What is not clear though, is how the system is affected if both the process and its mirror counterpart fail. TIB/Rendezvous [17] integrates fault tolerance through delegation to another software TIB/Hawk which provides it with immediate recovery from unexpected failures or application outages. This is achieved through the distributed TIB/Hawk micro-agents, which support autonomous network behavior, while continuing to perform local tasks even in the event of network failures.
Message queuing products such as IBM's MQSeries [27] and Microsoft's MSMQ [26] are statically pre-configured to forward messages from one queue to another. This leads to the situation where they generally do not handle changes to the network (node/link failures) very well. They also require these queues to recover within a finite amount of time to resume operations. To achieve guaranteed delivery, JMS provides two modes: persistent for sender and durable for subscriber. When messages are marked persistent, it is the responsibility of the JMS provider [15, 29, 28, 14] to utilize a store-and-forward mechanism to fulfill its contract with the sender (producer).
In our failure model a unit can fail and remain failed forever. The broker nodes involved in disseminations compute paths based on the active nodes and traversal times within the system. The routing scheme is thus based on the state of the network at any given time. Brokers could be dynamically created, connections established or removed, and the events would still be routed to the relevant clients. Any given node in the system would thus see the broker network undulate, as the brokers are being added and removed. Connections could also be instantiated dynamically based on the average pathlength for communication with any other node within the system. The connectivity graph maintains abbreviated system views; each node in this graph could also maintain information regarding the average pathlengths for communication with any other node within the unit, which the graph node represents. Connections could be dynamically instantiated to vary clustering coefficients and also to reduce average pathlengths for communications. The routing algorithms and the failure model allow support for dynamic reconfiguration of networks.
unit,
then we denote the replication granularity for nodes within that part of the sub system as r. Stable storages
exist within the context of a certain unit, with the possibility of multiple stable storages at different
levels within the same unit. We do not impose a homogeneous replication granularity throughout
the system. Instead, we impose a constraint on the minimum replication scheme for the system.
In an N-level system, comprising of level-N units, we require that every node have a replication
granularity of at least rN . Thus, in a system comprising of super-super-clusters we require that
every broker node within every super-super-cluster have a replication granularity of at least r3.
This is, of course, the coarsest grained replication scheme. There could be units present within
the system that have a replication strategy, which is more finely grained. The other constraint,
which we impose is that within a level- unit ui there can be only one stable storage at level
.
|
storage, we try to update the replication granularities associated with the nodes
within the level- unit ui that the stable storage is a part of. For a node x if the node's replication
granularity is rmx, there are two possible outcomes. If m > the node's replication granularity is
updated to i.e. rx. On the other hand if m < the replication granularity for the node is left
unchanged. Thus for example if the unit had a granularity of r3x and r2 has been added, the granularity
is changed to r2x. A condition where m = is an error condition since it depicts the presence
of multiple stable storages at the same level, a situation which should not arise because of the
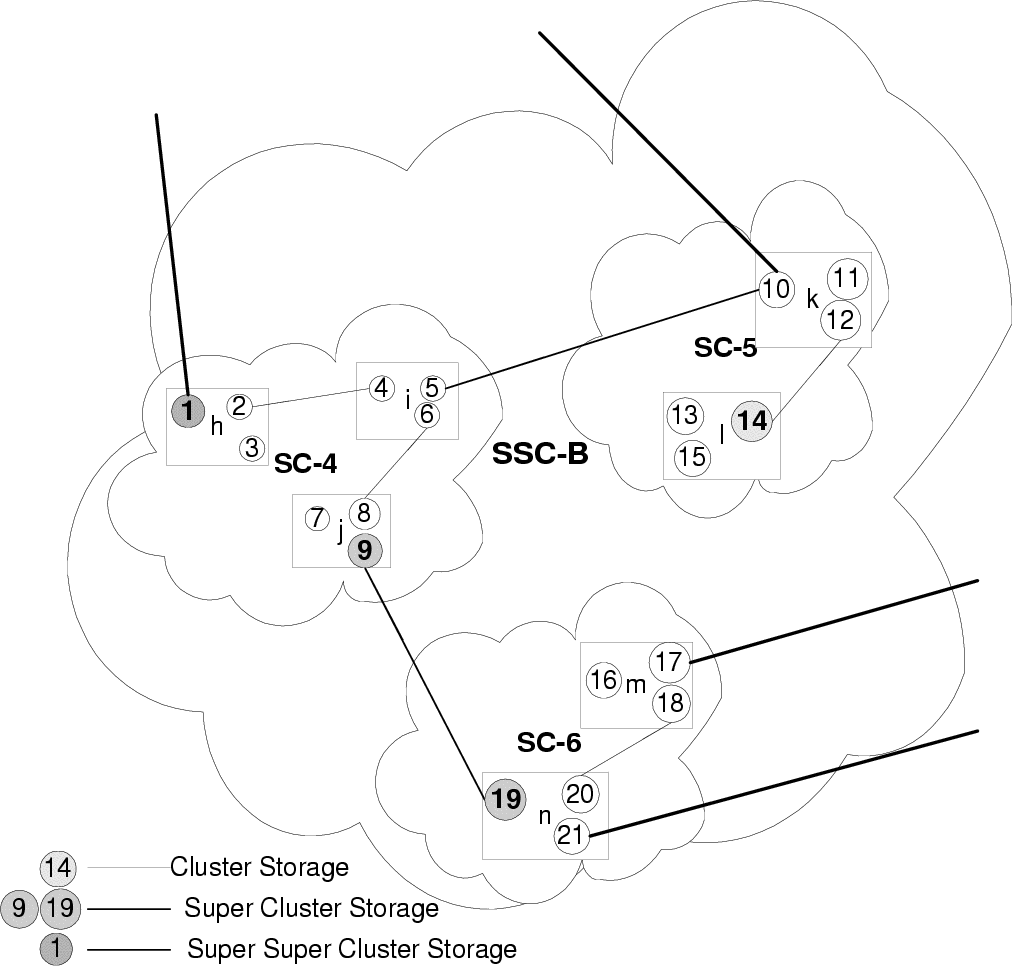
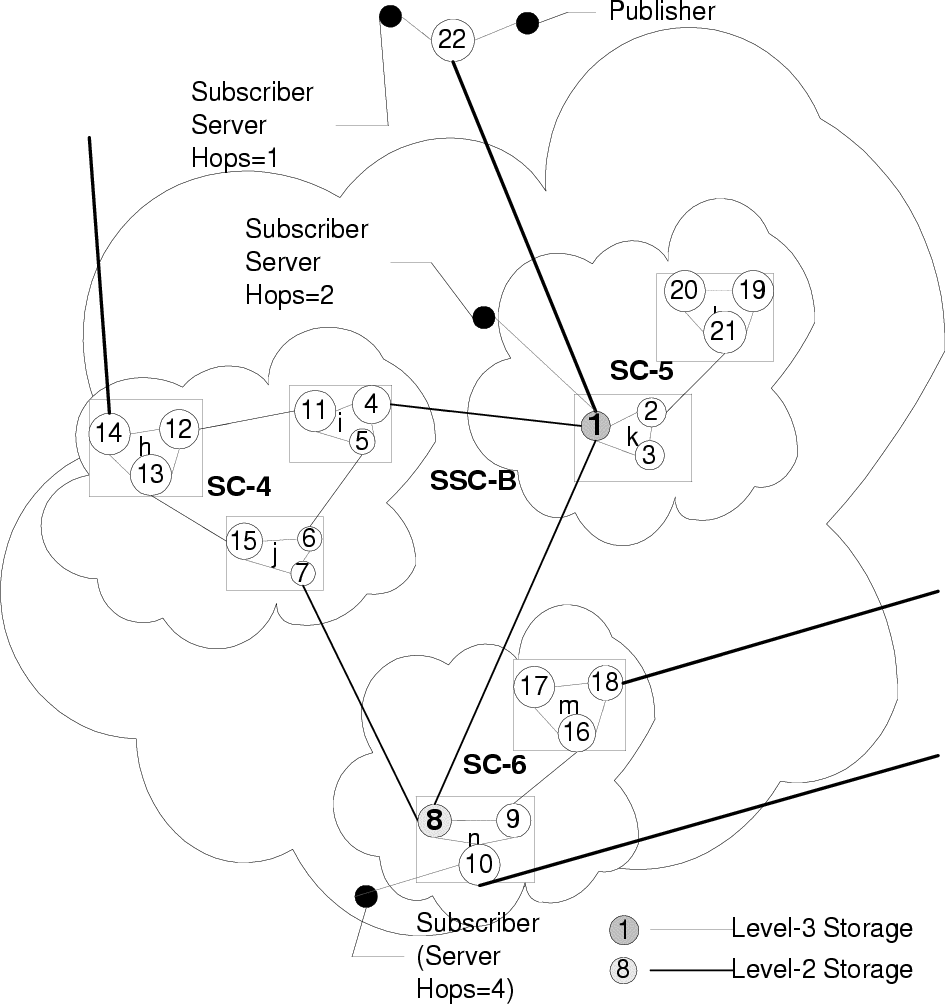
constraint that we have imposed. In the topology in figure 5 if we were to set up a level-2 stable
storage at node 10, the replication granularities at nodes 10,11 and 12 would be updated from r3 to
r2 . The replication granularity for every broker node in the cluster SC-5.l remains unchanged at
r1 .
, this node is responsible for computing
destinations, comprising of units at level-(-1), within the level- unit that the node belongs to.
Along with these destinations the node also computes the predicate count per destination that are
interested in receiving the event, this feature allows us to garbage collect events upon receiving
acknowledgements.
If finer grained stable storages are present within the subsystem with r, the receipt notification is slightly
different. As soon as the event is stored to the finer grained stable storage, this stable storage
sends a notification to the coarser grained storage indicating the receipt of the event and also the
predicate count that can be decremented for the sub-unit that this storage is servicing. Thus, in figure
5, when an event stored at node 1 is received at node 19, we can assume that all nodes in unit
SC-6 can be serviced and decrement the reference counts at the level-3 stable storage at node 1
accordingly.
Epochs are used to aid the reconnected clients and also to recover from failures. We use epochs to ensure that the recovery queues constructed for clients would not comprise of events that a client was not originally interested in. Failure to ensure this could lead to starvation of some of the clients. We also need epochs to provide us with a precise indication of the time from which point on a client should receive events. Not having this precise indication (during recoveries) leads to client starvations and also would also cause the system to expend precious network cycles in routing these events. We also have an epoch associated with every profile change and require that the client to waits till it receives the epoch notification, before it can disconnect from the system.
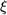 , are truly determined by the replication granularities that exist in
different parts of the system. Some of the details pertaining to epoch generation are listed below
-
there is a epoch
, are truly determined by the replication granularities that exist in
different parts of the system. Some of the details pertaining to epoch generation are listed below
-
there is a epoch  associated with it.
associated with it.For a profile associated with a client, we denote individual profile predicates as . Events are routed to a
client based on the that exist within a profile . However, every event received at a client needs to have an
epoch associated with it to aid in the recovery from failures and also to service events that have not been
received by the client. The arrival of such an event results in an update of the corresponding epoch associated
with the client's profile. The replication granularity within the system could be different in different sub
systems. Within a subsystem having a replication granularity r, it is possible that there are subsystems with
replication granularity r-1, r-2, 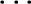 , r0. In such cases the epochs assigning process is delegated to the
corresponding replicators.
, r0. In such cases the epochs assigning process is delegated to the
corresponding replicators.
e , (d0e, d1e, 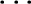 , dne), (p0e, p1e,
, dne), (p0e, p1e,  , pne), e.type, e.length, e.serialize >.
, pne), e.type, e.length, e.serialize >.
If n < m, the new finer grained stable storage should access the coarser grained storage with rm and retrieve the events, which were meant to be disseminated within the unit uin. The predicate count associated with the destinations for each individual event needs to be updated accordingly to reflect the predicate counts associated with the sub-units in uin. The epochs associated with these retrieved events should however remain unchanged. This is especially crucial since there are clients, attached to (disconnected from) broker nodes in the unit uin, which have epoch numbers associated with their profiles based on the ones assigned by storage hosting rm. The epochs associated with the client profiles should remain consistent even if a new stable storage is added. Once this event retrieval process is complete, the newly added stable storage is ready to assign epoch numbers to the events.
The system storage node maintains the list of all known uN destinations within the system. This destination list is associated with every event that is stored by the system storage. Associated with these events is a sequence number, which is different from the epoch number associated with the events that clients receive. Further, sequence numbers associated with events are used only by the system storages to conjecture the events that they should have received from any other system storage within the system. These sequence numbers are not used by the clients or the broker nodes within the system to detect missing events. Once the event is stored to such a system storage, it is ready to be sent across to the other uN destinations within the system. Also, for an event that is issued by a client within uiN, the event is stored to stable storage (to ensure routing to other uN units within the system) within uiN and not at any other system storages at the other uN units within the system. When the events are being sent across gateway gN for dissemination to other uN units, every event has a sequence number associated with it and also the unit uiN in which this event was issued. This is useful since the rN replicators (which serve as system storages) in other units can know which unit to send the acknowledgements (either positive or negative) to.
Stable storages at higher levels are aware of the finer grained replication schemes that exist within its unit. If a coarser grained stable storage is servicing the broker the client was last attached to, the system would use the higher level stable storage to retrieve the client's interim events. Otherwise the system would delegate this retrieval process to the finer grained stable storage, which now services the client's lower level GES context.
For a profile associated with a client, when a disconnected client joins the system it presents the node the
it connects to in its present incarnation the following -
received from the replicator within the replication granularity r of the sub system
that it was formerly attached to.
.Item (a) provides us with the stable storage that has stored events for the client. Item (b) provides us with the precise instant of time from which point on, event queues of events needs to be constructed and routed to the client's new location. Item (c) provides for the precise recovery of the disconnected client . Details regarding the precise recovery mechanism can be found in [38, 35].
In this section we present results pertaining to the performance of the Grid Event Service (GES) protocols. We first proceed with outlining our experimental setups. We use two different topologies with different clustering coefficients. The factors that we measure include latencies in the delivery of events and variance in the latencies. We measure these factors under varying publish rates, event sizes, event disseminations and system connectivity. We intend to highlight the benefits of our routing protocols and how these protocols perform under the varying system conditions, which were listed earlier.
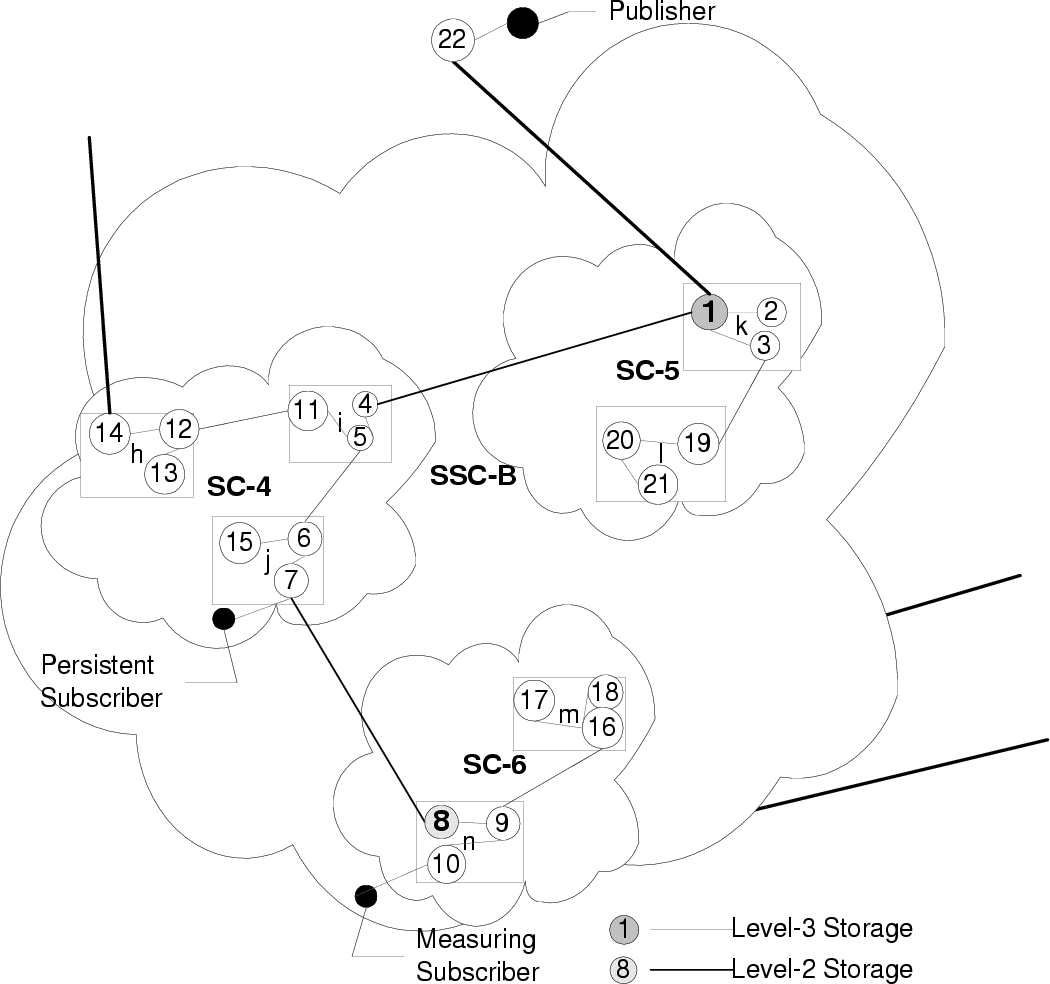
Each broker node process is hosted on 1 physical Sun SPARC Ultra-5 machine (128 MB RAM, 333 MHz), with no SPARC Ultra-5 machine hosting two or more broker node processes. For the purpose of gathering performance numbers we have one publisher in the system and one measuring subscriber (the client where we do our measurements). The publisher and the measuring subscriber reside on the same SPARC Ultra-5 machine and are attached to nodes 22 and 10 respectively in the topology outlined in figure 6. In addition to this there are 100 subscribing client processes, with 5 client processes attached to every other broker node (nodes 22 and 10 do not have any other clients besides the publisher and measuring subscriber respectively) within the system. The 100 client node processes all reside on a SPARC Ultra-60 (512 MB RAM, 360 MHz) machine. The publisher is responsible for issuing events, while the subscribers are responsible for registering their interest in receiving events. The run-time environment for all the broker node and client processes is Solaris JVM (JDK 1.2.1, native threads, JIT).
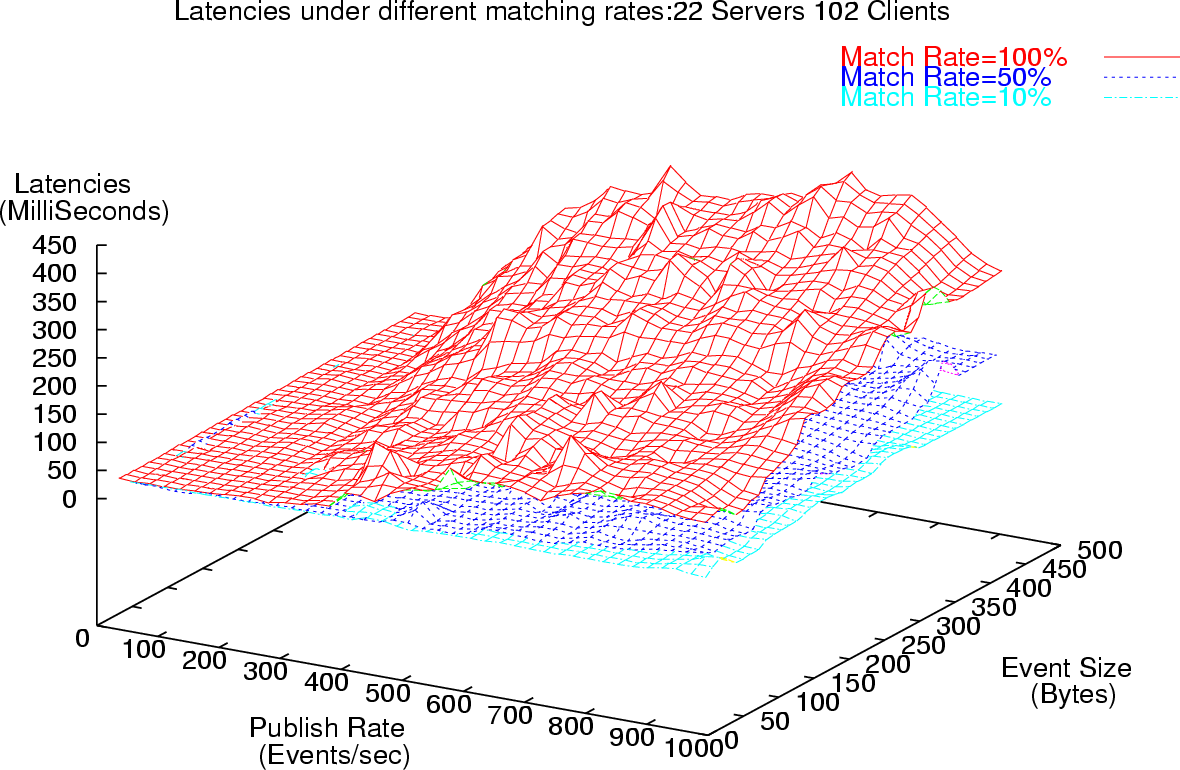
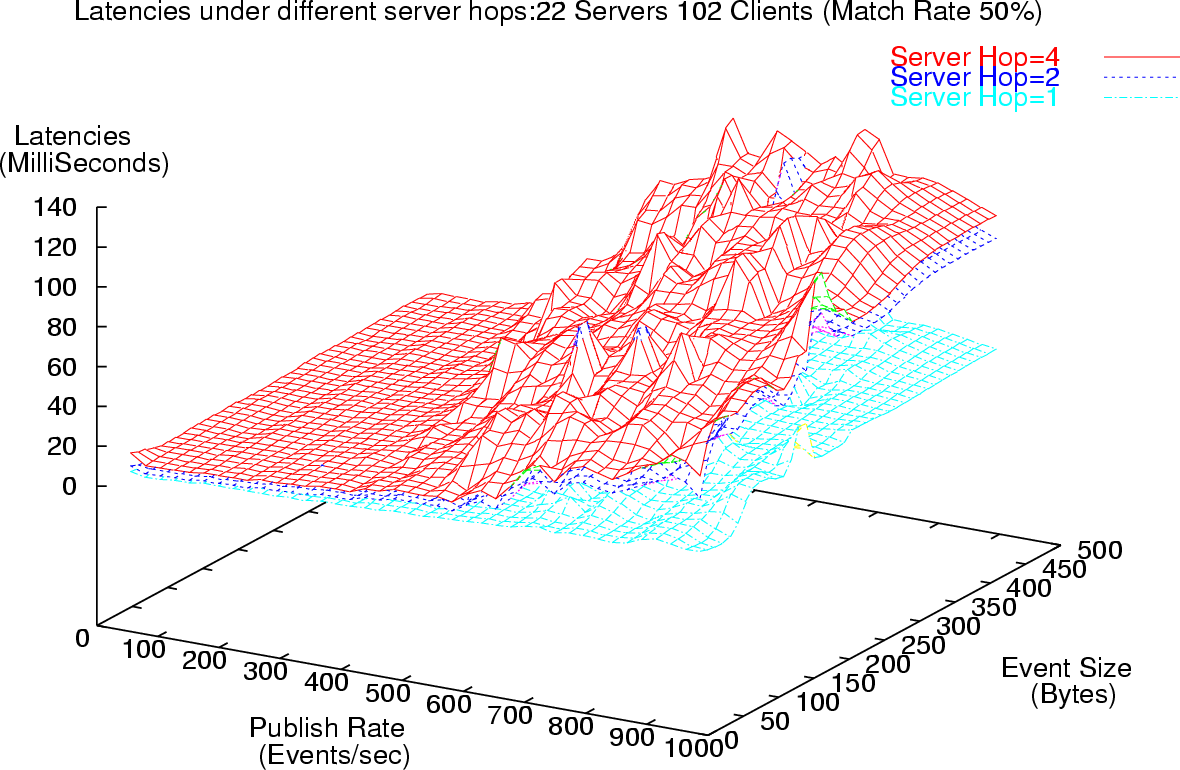
For each matching rate we vary the size of the events from 30 to 500 bytes, and vary the publish rates at the publisher from 1 Event/Sec to around 1000 Events/second. For each of these cases we measure the latencies in the reception of events. To compute latencies we have the publishing client and the measuring subscriber residing on the same machine. Events issued by the publisher are timestamped and when they are received at the subscribing client the difference between the present time and the timestamp contained in the received event constitutes the latency in the dissemination of the event at the subscriber via the broker network. Having the publisher and one of the subscribers on the same physical machine with access to the same underlying clock, obviates the need for clock synchronization and also accounts for clock drifts.
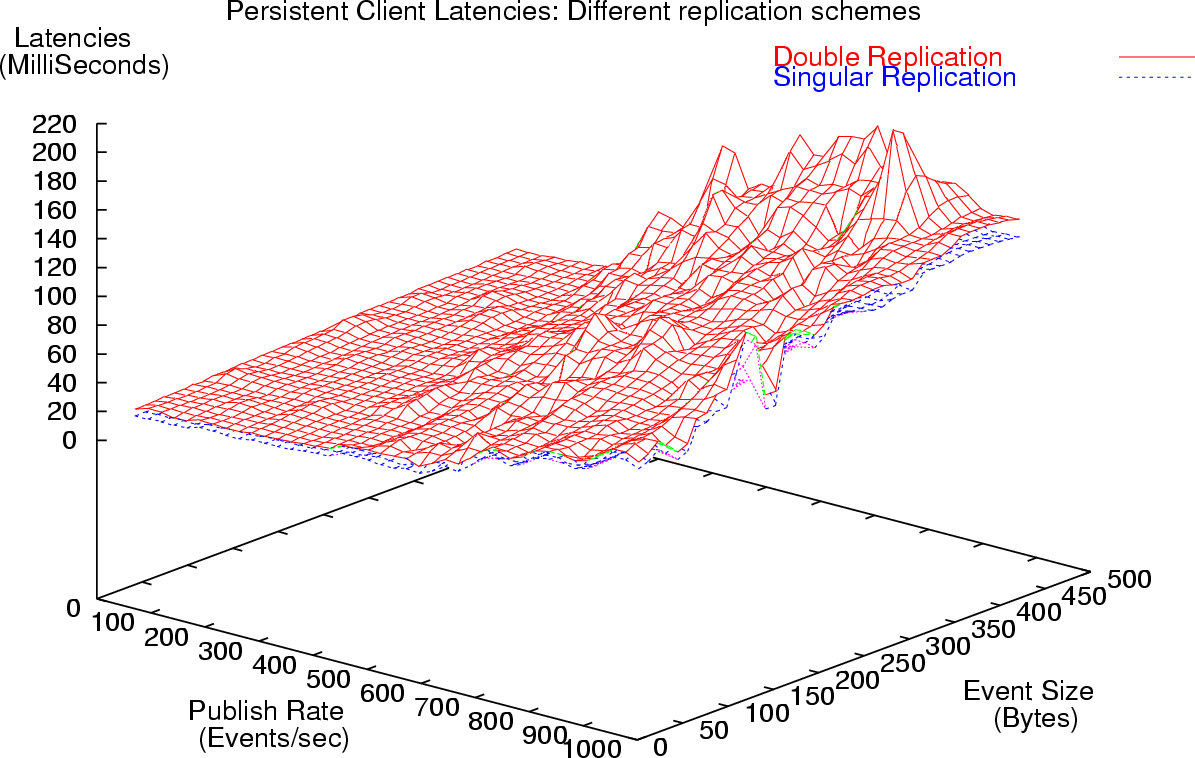
Figure 7 depicts the pattern of decreasing latencies with decreasing matching rates. Table 2 outlines the reduction in latencies and the variance associated with the latencies corresponding to the sample of events received at a client. This reduction in the latencies for decreasing matching rates, is a result of the routing algorithms that we have in place. These routing algorithms ensure that events are routed only to those parts of the system where there are clients, which are interested in the receipt of those events. In the flooding approach, all events would still have been routed to all clients irrespective of the matching rates. Additional results for latencies at different matching rates, system throughput measurements and changes in variance in the latency samples can be found in [38, 36, 35].
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
In this paper, we have presented the Grid Event Service (GES), a distributed event service designed to run on a very large network of broker nodes. The delivery guarantee needs to be met across client roams and also in the presence of broker failures. GES comprises of a suite of protocols, which are responsible for the organization of nodes, creation of abbreviated system views, management of profiles and the hierarchical dissemination of content based on these profiles. The broker topology ensures that pathlengths would only increase logarithmically with geometric increases in the size of the broker network. The feature of having multiple links between two units/super-units ensures a greater degree of fault tolerance. Links could fail, and the routing to the affected units is performed using the alternate links.
The system views at each of the broker nodes respond to changes in system inter-connections, aiding in the detection of partitions and the calculation of new routes to reach units within the system. The organization of connection information ensures that connection losses (or additions) are incorporated into the connectivity graph hosted at the broker nodes. The protocols in GES ensure that the routing is intelligent and can handle sparse/dense interest in certain sections of the system. GES's ability to handle the complete spectrum of interests equally well, lends itself as a very scalable solution under conditions of varying publish rates, matching rates and message sizes.
The paper outlined a scheme for the delivery of events in the presence of broker node failures. In our scheme a unit could fail and remain failed forever. The only requirement that we impose is that if a stable storage fails, it should recover within a finite amount of time. The replication strategy, that we adopted allows us to add stable storages and also to withstand stable storage failures. The replication strategy, epochs associated with received events and profile ID's associated with client profiles allowed us to account for a very precise recovery of events for clients with prolonged disconnects or those which have roamed the network.
GES could be extended very easily to support dynamic topologies. Based on the concentration of clients at specific locations, bandwidth utilization can be optimized with the creation of dynamic brokers at some of the clients. This scheme fits very well with our failure model for system units, where they can remain failed forever. Detection schemes can be employed to detect slow nodes, which serve as performance bottlenecks. Forcing these affected nodes to fail then reconfigures the system.
Clients can connect to local brokers instead of reconnecting all the way back to the remote broker that it was last connected to. This scheme optimizes bandwidth utilization. This optimization is very pronounced when there is a high concentration of clients accessing the remote broker. The failure model of the system, which allows a broker node or a unit/super-unit of broker nodes to fail and remain failed forever and still satisfy delivery guarantees is another significant contribution, which also allows the system to be easily extensible. This model ensures that clients need not wait for a broker to recover after this broker has failed. During failures clients do not experience a denial of service in this model. The service, as mentioned earlier, extends very naturally into dynamic topologies allowing for the dynamic instantiation and purging of brokers and connections. Changes in network fabric are incorporated by the routing algorithms, which ensure that the routing decisions made at a node are based on the current state of the system. The replication strategy presented in this paper, could be augmented to include mirror storages, which maintain information identical to that of the stable storages, and take over in the event of stable storage failures. This feature would add additional robustness and reduce the time required to recover from stable storage failures.
The results in section 5 demonstrated the efficiency of the routing algorithms and confirmed the advantages of our dissemination scheme, which intelligently routes messages. Industrial strength JMS solutions, which support the publish subscribe paradigm generally are optimized for a small network of brokers. The seamless integration of multiple broker nodes in our framework and the failure model that we impose on broker nodes provides for very easy maintenance of the broker network.
[1] Marcos Aguilera, Rob Strom, Daniel Sturman, Mark Astley, and Tushar Chandra. Matching events in a content-based subscription system. In Proceedings of the 18th ACM Symposium on Principles of Distributed Computing, May 1999.
[2] Ken Arnold, Bryan O'Sullivan, Robert W. Scheifler, Jim Waldo, and Ann Wollrath. The Jini Specification. Addison-Wesley, June 1999.
[3] Mark Astley, Joshua Auerbach, Guruduth Banavar, Lukasz Opyrchal, Rob Strom, and Daniel Sturman. Group multicast algorithms for content-based publish subscribe systems. In Middleware 2000, New York, USA, April 2000.
[4] Gurudutt Banavar, Tushar Chandra, Bodhi Mukherjee, Jay Nagarajarao, Rob Strom, and Daniel Sturman. An Efficient Multicast Protocol for Content-Based Publish-Subscribe Systems. In Proceedings of the IEEE International Conference on Distributed Computing Systems, Austin, Texas, May 1999.
[5] Anindya Basu, Bernadette Charron Bost, and Sam Toueg. Solving problems in the presence of process crashes and lossy links. Technical Report TR 96-1609, Dept. Of Computer Science, Cornell University, Ithaca, NY-14853, September 1996.
[6] Kenneth Birman. Replication and Fault tolerance in the ISIS system. In Proceedings of the 10th ACM Symposium on Operating Systems Principles, pages 79-86, Orcas Island, WA USA, 1985.
[7] Kenneth Birman. The process group approach to reliable distributed computing. Communications of the ACM, 36(12):36-53, 1993.
[8] Kenneth Birman. A response to cheriton and skeen's criticism of causal and totally ordered communication. Technical Report TR 93-1390, Dept. Of Computer Science, Cornell University, Ithaca, NY 14853, October 1993.
[9] Kenneth Birman and Keith Marzullo. The role of order in distributed programs. Technical Report TR 89-1001, Dept. Of Computer Science, Cornell University, Ithaca, NY 14853, May 1989.
[10] Romain Boichat, Patrick Th. Eugster, Rachid Guerraoui, and Joe Sventek. Effective Multicast programming in Large Scale Distributed Systems: The DACE Approach. Concurrency: Practice and Experience, 2000.
[11] Antonio Carzaniga, David S. Rosenblum, and Alexander L. Wolf. Achieving scalability and expressiveness in an internet-scale event notification service. In Proceedings of the Nineteenth Annual ACM Symposium on Principles of Distributed Computing, pages 219-227, Portland OR, USA, July 2000.
[12] Antonio Carzaniga, David S. Rosenblum, and Alexander L. Wolf. Content-based addressing and routing: A general model and its application. Technical Report CU-CS-902-00, Department of Computer Science, University of Colorado, Jan 2000.
[13] Akamai Corporation. EdgeSuite: Content Delivery Services . Technical report, URL: http://www.akamai.com/html/en/sv/edgesuite_over.html, 2000.
[14] Firano Corporation. A Guide to Understanding the Pluggable, Scalable Connection Management (SCM) Architecture - White Paper. Technical report, http://www.fiorano.com/ products/fmq5_scm_wp.htm, 2000.
[15] Progress Software Corporation. SonicMQ: The Role of Java Messaging and XML in Enterprise Application Integration. Technical report, URL: http://www.progress.com/sonicmq, October 1999.
[16] Talarian Corporation. Smartsockets: Everything you need to know about middleware: Mission critical interprocess communication. Technical report, URL: http://www.talarian.com/products/smartsockets, 2000.
[17] TIBCO Corporation. TIB/Rendezvous White Paper. Technical report, URL: http://www.rv.tibco.com/whitepaper.html, 1999.
[18] D Dolev and D Malki. The transis approach to high-availability cluster communication. In Communications of the ACM, volume 39(4). April 1996.
[19] Guy Eddon and Henry Eddon. Understanding the DCOM Wire Protocol by Analyzing Network Data Packets. Microsoft Systems Journal, March 1998.
[20] Message Passing Interface Forum. MPI: A Message-Passing Interface Standard. Technical report, Message Passing Interface Forum, May 1994.
[21] John Gough and Glenn Smith. Efficient recognition of events in a distributed system. In Proceedings 18th Australian Computer Science Conference (ACSC18), Adelaide, Australia, 1995.
[22] Katherine Guo, Robbert Renesse, Werner Vogels, and Ken Birman. Hierarchical message stability tracking protocols. Technical Report TR97-1647, Dept. Of Computer Science, Cornell University, Ithaca, NY 14853, 1997.
[23] Vassos Hadzilacos and Sam Toueg. A modular approach to fault-tolerant broadcasts and related problems. Technical Report TR94-1425, Dept. Of Computer Science, Cornell University, Ithaca, NY-14853, May 1994.
[24] Mark Happner, Rich Burridge, and Rahul Shrama. Java message service. Technical report, Sun Microsystems, November 1999.
[25] T.H. Harrison, D.L. Levine, and D.C. Schmidt. The design and performance of a real-time CORBA object event service. In Proceedings of the OOPSLA’97, Atlanta, Georgia, October 1997.
[26] Peter Houston. Building distributed applications with message queuing middleware - white paper. Technical report, Microsoft Corporation, 1998.
[27] IBM. IBM Message Queuing Series. http://www.ibm.com/software/mqseries, 2000.
[28] Softwired Inc. iBus Technology. http://www.softwired-inc.com, 2000.
[29] iPlanet. Java Message Queue (JMQ) Documentation. Technical report, URL: http://docs.iplanet.com/docs/manuals/javamq.html, 2000.
[30] Javasoft. Java Remote Method Invocation - Distributed Computing for Java (White Paper). http://java.sun.com/marketing/collateral/javarmi.html, 1999.
[31] The Object Management Group (OMG). CORBA Notification Service. URL: http://www.omg.org/technology/documents/formal/notificationservice.htm, June 2000. Version 1.0.
[32] The Object Management Group (OMG). OMG's CORBA Event Service. URL: http://www.omg.org/technology/documents/formal/eventservice.htm, June 2000. Version 1.0.
[33] The Object Management Group (OMG). OMG's CORBA Services. URL: http://www.omg.org/technology/documents/, June 2000. Version 3.0.
[34] Andy Oram, editor. Peer-To-Peer - Harnessing the Benefits of a Disruptive Technology. O'Reilly & Associates, Inc., 1.0 edition, March 2001.
[35] Shrideep Pallickara and Geoffrey Fox. The grid event service (ges) framework: Research direction & issues. Technical report, IPCRES Grid Computing Laboratory, 2001.
[36] Shrideep Pallickara and Geoffrey Fox. Initial results from an early prototype of the grid event service. Technical report, IPCRES Grid Computing Laboratory, 2001.
[37] Shrideep Pallickara and Geoffrey Fox. Routing events in the grid event service. Technical report, IPCRES Grid Computing Laboratory, 2001.
[38] Shrideep B. Pallickara. A Grid Event Service. PhD thesis, Syracuse University, June 2001.
[39] R Renesse, K Birman, and S Maffeis. Horus: A flexible group communication system. In Communications of the ACM, volume 39(4). April 1996.
[40] Aleta Ricciardi, Andre Schiper, and Kenneth Birman. Understanding partitions and the "no partition" assumption. In Proceedings of the Fourth Workshop on Future Trends of Distributed Systems, Lisbon, Portugal, September 1993.
[41] Fred Schneider. Implementing fault-tolerant services using the state machine approach: A tutorial. In ACM Computing Surveys, volume 22(4), pages 299-319. ACM, December 1990.
[42] Bill Segall and David Arnold. Elvin has left the building: A publish/subscribe notification service with quenching. In Proceedings AUUG97, pages 243-255, Canberra, Australia, September 1997.
[43] Bill Segall, David Arnold, Julian Boot, Michael Henderson, and Ted Phelps. Content based routing with elvin4. In Proceedings AUUG2K, Canberra, Australia, June 2000.
[44] D.J. Watts and S.H. Strogatz. Collective Dynamics of 'Small-World' Networks. Nature, 393:440, 1998.