| 3.1 INDEPENDENT 指令 |
INDEPENDENT指令可以放在一个索引DO循环或FORALL语句的前面。它向编译器声明紧随它的DO循环中的迭代或紧随它的FORALL中的操作都可以各自独立执行--即可以以任何次序执行,或交替执行,或同时执行,而不改变程序的语义。
INDEPENDENT指令放在DO循环和FORALL的前面来声明其动作并一般认为适用于该循环或FORALL。INDEPENDENT指令的语法是:
H301 independent-directive is INDEPENDENT[,new-clause] H302 new-clause is NEW(variable-name-list) H303 reduction-clause is REDUCTION(reduction-variable-list) H304 reduction-variable is array-variable-name or scalar-variable-name or structure-component
约束:紧跟着INDEPENDENT指令的第一条非注释行必须是一个DO语句,FORALL语句,或FORALL结构。
约束:如果紧跟着INDEPENDENT指令的第一条非注释行是一个DO语句,则该语句必须包含一个含有DO变量的循环控制选项。
约束:如果出现NEW子句或REDUCTION子句,则紧跟着INDEPENDENT指令的第一条非注释行必须是一个DO语句。
约束:NEW或REDUCTION子句中所命名的变量以及任何部件或元素一定不能:
.是一个哑元。
.具有SAVE或TARGET属性。
.是COMMON中的对象或与COMMON中对象存储相联。
.是使用相联的。
.是宿主相联的。
.通过宿主相联在另一个作用域单元内被访问。
.一个归约变量不能出现在同一INDEPENDENT指令的NEW子句中,也不能出现在紧跟着的DO语句,FORALL语句,或FORALL结构作用域范围(例如词法部分等)内的任何NEW子句或归约子句中。
.归约变量中的结构部件不能包含下标区域列表。
约束:归约变量必须是内部类型。它不能是字符类型。
基本原理:第二个约束意味着INDEPENDENT指令不能适用于WHILE循环或一个简单DO循环(例如,一个“do forever”)。在这些情况中,INDEPENDENT指令仅能指示0步或1步循环;潜在的混淆也许会超过可能的收益。(基本原理结束)
当应用于一个DO循环时,程序员通过INDEPENDENT指令声明没有任何迭代会直接或间接影响其它迭代。下面的操作定义了这样的冲突:
.对同一自动变量赋值的任何两个操作相互冲突。(一个数据对象称为自动的,仅当它不包含子对象)
—例外:如果一个变量出现在NEW子句中,则DO循环不同迭代中对它的赋值相互之间不冲突。3.1.2节将解释其原因。
—例外:如果一个变量出现在REDUCTION子句中,则DO循环范围内通过归约语句对它的赋值与同一循环中其它归约语句对它的赋值不冲突。3.1.3节将解释其原因。
.对一个自动对象的赋值操作与任何使用该对象值的操作相冲突。
—例外:如果一个变量出现在NEW子句中,则DO循环一个迭代中对它的赋值与其它迭代中该变量的使用不冲突。3.1.2节将解释其原因。
—例外:如果一个变量出现在REDUCTION子句中,则DO循环范围内通过归约语句对它的赋值与同一循环中归约语句对它的使用不冲突。3.1.3节将解释其原因。
基本原理:这些是能够并行执行的典型的Bernstein条件。注意,一个变量同一值的两次赋值相互冲突,因此具有这种赋值的INDEPENDENT循环不符合HPF标准。之所以不允许这种赋值,是由于这种重叠赋值在一些硬件上很难得到支持,而且给定的定义可以在概念上更清晰。类似地,将对同一位置赋予多个值声明为INDEPENDENT也是不符合HPF标准的,即使程序在逻辑上可以接受任何可能值。在这种情况下,“概念上更清晰”的参数以及愿意避免非确定性行为有利于给定解。(基本原理结束)
.ALLOCATE语句,DEALLOCATE语句,NULLIFY语句或指针赋值语句与任何其它的访问-包括指针赋值,同一指针的分配,释放或清空-相冲突。另外,ALLOCATE或DEALLOCATE语句同已分配或释放对象的任何其它使用或赋值相冲突。
基本原理:这些约束将Bernstein条件扩展到指针。因为Fortran指针是对象或子对象的别名,而非第一类数据类型,所以其约束需要比其它变量更精细。(基本原理结束)
.任何一个将控制转移到循环体外分枝目标语句的操作都与循环内的所有其它操作相冲突。
.EXIT,STOP或PAUSE语句的任何执行与循环内的所有其它操作相冲突。
基本原理:分枝(通过GOTO或I/O语句中的ERR=分枝)暗示循环的一些迭代不能执行,这会与那些计算发生激烈的冲突。EXIT和其它语句也是一样。注意,除了不允许交替返回到循环之外的语句,这些条件并没限制INDEPENDENT循环中的过程调用。(基本原理结束)
.READ操作对其输入列表(input-item-list)中的对象进行赋值;而WRITE或PRINT操作使用其输出列表中(output-item-list)的对象值。正如上面的每一个条件,I/O操作可能与其它的操作(包括其它的I/O操作)相冲突。
.内部READ操作使用其内部文件;而内部WRITE操作对其内部文件赋值。这些使用和赋值可能象上面概述的一样同其它操作相冲突。
.除了与同一文件或单元相关联的INQUIRE外,任何两个文件操作都相互冲突。两个INQUIRE操作相互之间不冲突;但是,一个INQUIRE操作与任何其它的关联于同一文件的I/O操作相冲突。
基本原理:因为Fortran仔细定义了数据传送或文件定位语句之后的文件位置,因此这些操作影响程序的全局状态。(注意,即使对于直接访问的文件也定义了文件位置)。多个非前进性数据传送语句影响文件位置的方式类似于对一个变量同一值的多次赋值,并由于相同的原因而被禁止。多重OPEN和CLOSE操作影响文件和单元的状态,这是另一种全局副作用。INQUIRE不影响文件状态,因此不影响其它的查询。可是,其它的文件操作可能影响INQUIRE所报告的特性。
.循环中所执行的任何数据的重对准或重分配(见第七节)与对同一数据的任何访问或任何其它重对准相互冲突。数据的重对准或重分配可由REALIGN或REDISTRIBUTE指令产生,也可由一些描述性或指示性映射指令对子程序参数的重映射产生。
基本原理:REALIGN和REDISTRIBUTE可以改变存储某一特定数组元素的处理器,它同任何对该元素的赋值或使用相冲突。类似地,多次重映射操作可导致相同的元素被存储在多个位置中。
同一推论适用于过程调用边界所执行的重映射,即使此重映射在调用返回时未被执行。在调用执行过程中,数组元素的所在地已经改变了,这样就会与下列情况相冲突:任何调用者中对它的访问,同一过程其它引用对它的访问,以及数组的重映射(诸如另一个过程调用所产生的重映射)(基本原理结束)
对于FORALL的INDEPENDENT的解释类似于对于DO解释:它声明如果一个FORALL索引的组合对一个自动存储单元赋值,则不存在其它的组合对该单元进行读操作。如果都具有INDEPENDENT指令,则具有同一程序体的DO和FORALL是等价的。3.1.1节将阐述这一点。
如果对一个过程的调用发生在INDEPENDENT循环或FORALL中,则该过程中任何本地变量在每次调用中都认为是不同的,除非它们具有SAVE属性。这一点与Fortran标准是一致的。因此,不同迭代的调用中对本地变量的使用不会与上面所定义的相互冲突。
对实现者的建议:一个合法的Fortran实现通常可以避免每次调用都在本地创建不同的存储。HPF实现同样可以做到这一点;可是,这种实现必须仍然以同样的方式解释INDEPENDENT。如果在每次调用中没有为本地数据分配唯一的存储位置,则INDEPENDENT循环必须串行执行以保证这些语义(否则必须采用其它的技术来避免冲突访问)(对实现者的建议结束)
注意,所有这些都描述了冲突行为;它们不允许专门的语法。INDEPENDENT循环中,如果由于控制流的原因,一些语句不能执行,则即使这些语句的出现违反了这些约束中的一条或更多条也是允许的。在计算资源可以获得的情况下,这些约束可以保证INDEPENDNET循环安全地并行执行。本指令纯粹是建议性的,如果编译器不能利用这些信息的话,可以随意忽略它。
对实现者的建议:虽然这些约束允许INDEPENDENT循环的安全并行实现,但它们并不表示这一实现在所有的结构或程序中是有用的(或者甚至可能的)。例如:
.INDEPENDENT循环可能调用一个具有显式映射本地变量的例程。则此实现必须或者实现这一映射(这可能要求调用的串行化),或者使显式指令无效(这可能使用户感到意外)
.INDEPENDENT循环可能在每次迭代中具有非常不同的行为。例如:
!HPF$ INDEPENDENT
DO i = 1,3
IF (i.EQ.1) CALL F(A)
IF (i.EQ.2) CALL G(B)
IF (i.EQ.3) CALL H(C)
END DO
它为SIMD机器上的实现造成了显而易见的问题。
.INDEPENDENT循环可能调用一个访问全局映射数据的子程序。在分布存储的机器上,产生所引用数据的通信可能是具有挑战性的,因为一般来说无法保证数据的拥有者也调用此子程序。
在所有这些情况下,实现者都有义务产生正确的行为,但同时可能限制了优化。如果INDEPENDENT声明可以忽略,则推荐实现时能够提供一些反馈。(对实现者的建议结束)
DO i=1,3 FORALL(i=1:3) lhsa(i)=rhsa(i) lhsa(i)=rhsa(i) lhsb(i)=rhsb(i) lhsb(i)=rhsb(i) END DO END FORALL
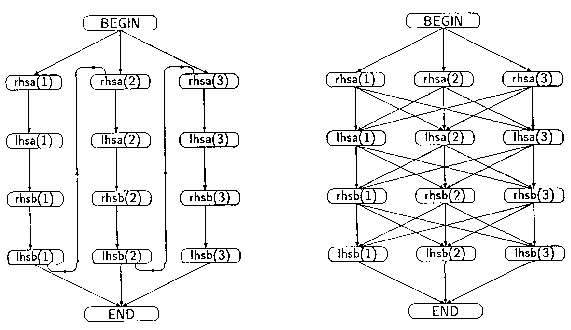
插图 3.1:没有INDEPENDENT声明的DO循环及FORALL中的依赖
!HPF$ INDEPENDENT !HPF$ INDEPENDENT DO i=1,3 FORALL (i=1:3) lhsa(i)=rhsa(i) lhsa(i)=rhsa(i) lhsb(i)=rhsb(i) lhsb(i)=rhsb(i) END DO END FORALL
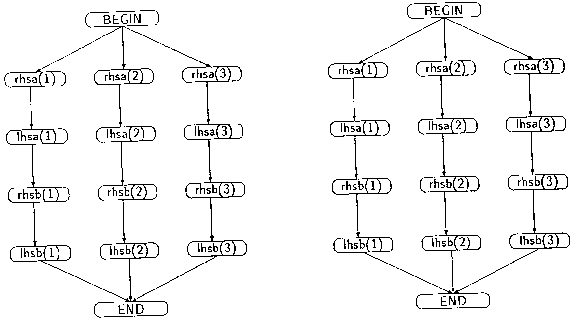
插图 3.2:有INDEPENDENT声明的DO循环及FORALL中的依赖
从图示上看,通过从描述程序的前向图中去掉一些边,就可以实现INDEPENDENT指令的可视化。插图3.1显示了DO和FORALL中可能正常出现的一些依赖。(多数依赖没有显示出来)一个从左手部节点(例如,“lhsa(1)”)指向右手部节点(“rhsb(1)”)的箭头意味着右手部的计算可能使用左手部节点所赋的值。这样,右手部的计算必须发生在左手部完成其存储之前。类似地,一个从右手部节点指向左手部节点的箭头意味着左手部可能覆盖右手部计算所需的值,并强制一个次序。从BEGIN开始一直到END之间的所有边描述了控制依赖。INDEPENDENT指令声明编译器需要执行的唯一依赖是插图3.2中的那些依赖。也就是说,使用INDEPENDENT的程序员必须证明如果编译器仅执行这些边,则此结果程序与存在所有边的程序是等价的。注意,INDEPENDENT DO和FORALL语句所声明的依赖集合是相同的。
如果编译器可以证明这些声明中的某一个是不正确的,希望它能产生一个警告。但是,我们不要求做到这一点。包含任何这种类型错误声明的程序都是不符合HPF标准的,这样也就没被HPF所定义,并且编译器可以采取任何它认为适当的行动。
!HPF$ INDEPENDENT
DO I=2,99
A(I)=B(I-1)+B(I)+B(I+1)
END DO
这是INDEPENDENT循环最简单的一个例子。(为简化起见,本节中的所有例子都假定代码中所使用的任何变量之间没有存储或顺序相联)每个迭代对数组A的不同位置赋值,这样就满足了上面的第一个条件。因为右手部未使用A的任何元素,即未对循环中赋值的任何位置做读操作,这样就满足了第二个条件。注意,这里重复使用了B的许多元素;这一点在INDEPENDENT的定义中是允许的。不管涉及到什么变量值,此循环都是INDEPENDENT的。
!HPF$ INDEPENDENT
FORALL (I=2:N) A(I)=B(I-1)+B(I)+B(I+1)
本例与第一个例子在所有的方面都等价。
!HPF$ INDEPENDENT
DO I=1, 100
A(P(I))=B(I)
END DO
此INDEPENDENT指令声明数组P没有任何重复的入口(否则当对A赋值时可能导致冲突)。此DO循环因此等价于Fortran语句:
A(P(1:100))=B(1:100)
NEW子句声明所命名的变量在INDEPENDENT循环的每个迭代中用作私有变量。即,如果在DO循环的每个迭代中为NEW变量创建新的对象并在每次迭代结束时破坏那些对象,则不会出现相互冲突的赋值和使用。这样,就不会有任何值从循环之前的执行中流入到NEW变量中,同时(最重要的)也不会有任何值通过NEW变量从一个迭代流入到另一个迭代中。
对用户的建议:NEW子句中可以出现指针或可分配的变量。在这些情况下,上面段落的解释是,我们不应在循环的入口处依赖这种变量的值,相关的状态或分配状态;另一方面,在使用这种变量之前,应在循环体中对其分配或对指针赋值。同时建议在对这种变量最后一次使用之后,应在循环体中将其释放或清空。(对用户的建议结束)
基本原理:NEW变量提供了一种方式以便在INDEPENDENT循环中定义临时变量。没有这一特征,许多概念上独立的循环都将从本质上重写(包括将标量扩展成数组)以满足上面所描述的相当严格的要求。注意,将一个临时变量定义成NEW只需在对其赋值的最内词法层进行即可,这是因为所有圈着它的INDEPENDENT声明都必须将该NEW考虑在内。还需注意,用于嵌套DO循环的索引变量必须定义成NEW;这种代替将索引变量的范围限制在循环自身,它改变了Fortran语义。可是,FORALL的索引受FORALL语义的约束;它们不要求NEW定义。(基本原理结束)
!HPF$ INDEPENDENT, NEW(I)
DO I=1,10
A(I)=B(I-1)
END DO
本例无论有无NEW子句都将是正确的;无论在哪种情况下,编译器都能确信将对数组A的赋值并行化。但是另一方面,NEW子句声明循环完成后就不再使用循环索引I。一些编译器可能使用这一信息来避免更新其它处理器上的重复拷贝,或完成其它的优化。
!HPF$ INDEPENDENT, NEW(I2)
DO I1=1,N1
!HPF$ INDEPENDENT, NEW(I3)
DO I2=1,N2
DO I3=2,N3 !内层循环不是独立的
A(I1,I2,I3)=A(I1,I2,I3)-A(I1,I2,I3-1)*B(I1,I2,I3)
END DO
END DO
END DO
因为对A的每个元素的计算依赖于前面的迭代,因此内层循环不是独立的。可是,由于两个外层循环访问A的不同元素,所以它们是独立的。由于在最外层循环的不同迭代中对内层循环索引进行赋值和使用,因此需要NEW子句。
REDUCTION子句声明通过一系列交互,相关的操作对INDEPENDENT循环中的变量进行更新。进一步讲,循环中不使用REDUCTION变量的中间值(当然,对其自身更新时是一个例外)。这样,循环之后REDUCTION变量的值是归约树的结果。
基本原理:REDUCTION变量提供了一种方式来累加INDEPENDENT循环中所产生的值。没有这一特征,程序员就必须在一个大小等于循环迭代数的临时数组中存储更新信息,然后在循环之后,使用某个内部归约函数或XXX_SCATTER库函数。这一方法的问题是临时数组可能过于庞大。(基本原理结束)
归约的语义将在3.1.4节中详细讨论。本节定义正确的语法。
任何归约变量在其紧跟的DO循环是活动时(例如正执行)都要受到保护。除了一个例外,当保护它的循环活动时,不能对其引用。它可以出现在一个特殊形式赋值语句的特殊位置,而且这些语句必须在循环范围之内(例如词法体)。特别地,它不能出现在任何HPF指令中,包括NEW子句的变量列表中。这一点包括同一INDEPENDENT指令的任何NEW子句。
一个归约语句是下列特殊形式的赋值语句,它出现在INDEPENDENT DO循环的范围内,其归约变量名出现在归约子句中。此描述不是HPF语法的一部分;但它对于定义这种允许归约变量的受约束的赋值语句特别有用。
H305 reduction-stmt is reduction-variable-ref=expr reduction-op reduction-variable-ref or reduction-variable-ref = reduction-variable-ref reduction-op op or reduction-variable-ref = reduction-function (reduction-variable-ref,expr) or reduction-variable-ref = reduction-function (expr, reduction-variable-ref)
H306 reduction-variable-ref is variable
H307 reduction-op is + or - or * or / or .AND. or .EQV. or .NEQV.
H308 reduction-function is MAX or MIN or IAND or IOR or IEOR
在等号后面归约变量之前或之后的操作符或函数是归约操作符。
3.1节头两个声明说明了这样一个事实:归约变量出现在归约语句的允许位置不会导致INDEPENDENT循环迭代间的冲突。对归约变量的任何其它赋值或引用确实要与归约语句发生冲突;包括它出现在子程序中或归约语句的表达式(expr)部分。
如果一个变量在INDEPENDENT循环中被归约语句更新,则必须通过将该变量在INDEPENDENT指令的归约子句中显式出现来对其进行保护,该INDEPENDENT指令位于最外层的INDEPENDENT循环且它的NEW语句不包含那个变量。
对用户的建议:当执行归约语句时,一些DO循环的嵌套将是活动的。如果在进行变量更新的归约语句周围,存在几个嵌套INDEPENDENT DO循环,则哪一个DO循环应该得到归约子句?回答是最外层的那一个,同时遵循下面的约束:归约变量不能出现在该循环的NEW子句或一个受约束的循环中。
!HPF$ INDEPENDENT, NEW(J), REDUCTION(X)
DO I=1, 10
!HPF$ INDEPENDENT
DO J=1, 20
X=X+J
ENDDO
ENDDO
不能将归约子句移到内层INDEPENDENT指令中。因为外层循环的每次迭代都要通过归约操作对X进行更新(二十次),因此直到外层循环完成它才能得到一个正确定义的值。(对用户的建议结束)
对归约变量(reduction-variable)的引用可以是一个数组元素或数组区域。出现在一条归约语句的两个引用必须在词法上是相同的。Fortran的操作符优先级规则以及表达式中括号的使用必须保证归约操作符是右手部的顶级操作符(例如,最后对它估算)。不允许下面两种形式的归约语句:
reduction-variable-ref = expr - reduction-variable-ref
reduction-variable-ref = expr - reduction-variable-ref
注意,INDEPENDENT指令的语法不允许在归约子句中将一个数组元素或数组区域指定为归约变量。虽然这种子对象可以出现在一个归约语句中,也只能将整个数组和字符变量当作一个归约变量。
在它们的数学定义中,所允许的归约操作符和函数都是相关联的(即使Fortran语言处理器中算数操作符的通常实现以及基础硬件不是相关联的)
在大多数情况下,更新给定规约变量的多个归约语句中(如果有多个的话)只能使用一个操作符。但是允许在同一个归约变量上一起使用+和-:在数学上,减只是求反相加。例如:
!HPF$ INDEPENDENT, REDUCTION(X)
DO I = 1, 100
X(IDX(I,1))=X(IDX(I,1))+Y(I)
X(IDX(I,2))=X(IDX(I,2))-Y(I)
END DO
乘(*)和除(/)也是一样的。除此之外,不允许其它操作符混用。
HPF指明了具有归约语句的INDEPENDENT DO循环的一个允许的并行实现,因此也指明了这种循环的语义。
正如Fortran内部函数SUM的结果被定义成一个依赖于实现的其数组元素的近似求和,INDEPENDENT DO循环出口处的归约变量的值同样没被HPF完全指明。一种可能的值是通过循环的串行执行计算得到,但是也可产生该值其它的依赖于实现的近似值。任何这种依赖于实现的值都近似于循环串行执行所产生的值。在忽略四舍五入错误,下溢,上溢的情况下,它与该值是相同的。
由于一个受保护归约变量的引用只能出现在归约语句中,因此,不必要定义这些变量在受保护时所可能具有的值。
在此讨论中, 术语处理器指的是一个单一的物理处理器或一组物理处理器, 这些处理器一起串行执行某个INDEPENDENT循环的一些或所有迭代。
我们给出一个简单的实现机制,该机制适合于可交换的归约操作。在一个INDEPENDENT循环的入口处,每个执行处理器都要分配一个私有累加变量,该变量同INDEPENDENT指令上归约子句的每个变量相联系,同时将它初始化为相应内部归约操作符的标志元素(identity element)。私有累加变量与归约变量具有相同的形状,类型和特性(kind)类型参数。
表3.1定义了对应于内部操作符的标志元素。
操作符 标志元素 ————————————————————— + 0 - 0 * 1 / 1 .AND. .TRUE. .OR. .FALSE. .EQV. .TURE. .NEQV. .FALSE.
表3.1 对应于内部归约操作符的标志元素
表3.2列出了可用于归约函数的内部函数以及它们的标志元素。
函数 标志元素 ————————————————————— IAND(I,J) NOT(0)(所有元素) IOR(I,J) 0 IEOR(I,J) 0 MIN(X,Y) 最大绝对值的正数, 该数与归约变量具有 相同的类型和种类参数 MAX(X,Y) 最大绝对值的负数, 该数与归约变量具有 相同的类型和种类参数
表3.2 对应于内部归约函数的标志元素
每个处理器执行循环迭代的一个子集;当它遇到一个归约语句时,它更新自己的累加变量。处理器可以以任意次序执行其循环迭代;进一步讲,它可以启动一个迭代,然后挂起该迭代上的工作,接着做其它迭代的一些或全部工作,随后再继续挂起迭代上的工作。但是私有累加变量的任何更新都是通过归约语句的执行发生的,并且归约语句是自动执行的。
归约变量最后的值是通过将私有累加变量与循环入口处归约变量的值使用归约操作符合并计算得到的。正如内部归约函数(SUM等)一样,此归约的次序也是依赖于语言处理器的。
考虑下面的例子:
REAL Z
Z=5
!HPF$ INDEPENDENT, REDUCTION(Z)
DO I=1, 10
Z=I+Z
ENDDO
Z的最终取值是5+(1+2+3+4+5+6+7+8+9+10)=60;HPF没有指定加发生的次序。
对于第二个例子,这里是由INDEPENDENT循环所做的的一个分散相加(ADD_SCATTER):
!HPF$ INDEPENDENT, REDUCTION(X)
DO I = 1,N
X(INDEX(I)) = X(INDEX(I)) - F(X)
ENDDO
实现本例的最可能的一种方式是在每个处理器上都建立累加数组XLOC的一个私有拷贝,该数组同X具有相同的类型和形状。每个迭代都将从其自身的XLOC(INDEX(I))中减去F(I)的值。为创建最后的结果,实现时必须将所有的私有累加数组与X的初始值合并起来。合并操作符与归约操作符相同,即相加,因此结果应为X的初始值与累加数组的和。实现时可选用一个稀疏数据结构以便仅存储本地累加器中被更新的元素。
对实现者的建议:在基于MPI的实现中,可使用函数MPI_REDUCE来完成这一任务。(对实现者的建议结束)
| Copyright: NPACT |