| 4.1数组映射 |
在任何并行编程环境,编程者可以控制数据的布局和分配,这是很重要的。编译器技术不是足够高级的以至于不能完全自动地进行数据映射及同时产生可接受的性能。
对于数据映射的HPF模式在图1中解释。

图1:HPF数据映射模式
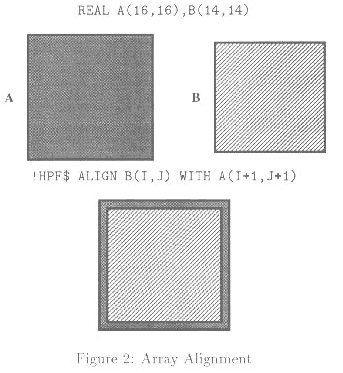
图2:数组对准
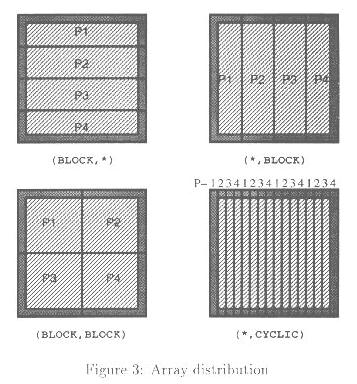
图3:数组分配
本质的思想是可以在两个数据对象之间定义有关的数据对准--典型地通过数组元素个关系。一组已对准的对象(数组)在抽象的线性处理器网格上分配。抽象处理器到物理处理器的映射是依赖于实现的。在图2中,数组A和B相互对准,以便A(I+1,J+1)和B(I,J)被对准。ALIGN指令指定对象间的对准。在图3中,我们表明数组A和B在四个(抽象)处理器上的深入分配。我们以一维表示垂直方向,二维表示水平方向。对于(BLOCK,*), 在各处理器上一维以block方式分配,二维的所有元素在每个处理器上都是局部的。对于(*,BLOCK)分配,情况相反。对于两维block分配(BLOCK,BLOCK), 数组A的每四分之一被分配到不同的处理器上。Cyclic分配也是可能的,最后一个例子表示在二维进行cyclic分配。这时,沿二维的每个元素按顺序被分配到不同的处理器。由一个指令定义分配,例如:
!HPF$ DISTRIBUTE A(*,BLOCK)
在Gaussian消去中,cyclic分配的例子是有用的。这种方法对数组的较小块进行操作。对较少的处理器,使用block分配在某些阶段是有用的。如果要求对一个维进行许多移位操作,那么cyclic分配这维是不合理的,因为这将包含处理器间的最大通讯。
虽然对ALIGN和DISTRIBUTE指令有更复杂的形式,但我们将不深入考虑这些。为了只定义一个对准而不分配一个数组,在一个抽象空间,模板,对准数组也是可能的。我们同样不深入考虑这个。有一个自动形式的对准和分配指令(REALIGN,REDISTRIBUTE),这样在一个程序执行期间,能改变数据的映射。
也可以指定一个处理器作为一个分配的目标。在下面的程序中,介绍了PROCUSSORS指令,并假设有六个处理器。
REAL A(16,16),B(14,14)
!HPF$ ALIGN B(I,J) WITH A(I+1,J+1)
!HPF$ PROCESSORS P(NUMBER_OF_PROCESSORS()/3,3)
!HPF$ DISTRIBUTE A(CYCLIC,BLOCK) ONTO P
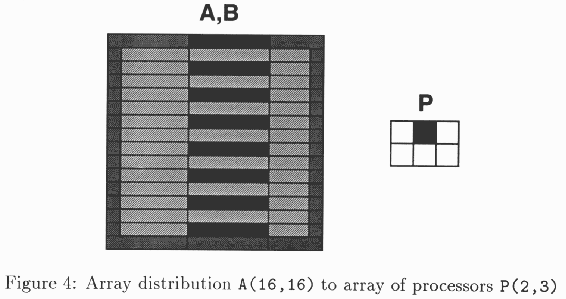
象前面一样数组A和数组B相互对准。然后,我们定义一个二维的抽象处理器网格Pij,其中i = 1,2; j = 1,2,3。NUMBER_OF_PROCESSORS是一个系统要求的函数,其返回实际可得到的处理器数。在这个例子中,数组A的元素是如下分配的:
A(1:15:2,:) |-> 处理器 P(1,1:3)
A(2:16:2,:) |-> 处理器 P(2,1:3)
图4表明A的哪一个元素被映射到不同的处理器。我们有垂直方向的第一维,并且在数组A和B中的阴影部分相应于到处理器P(1,2)的一个对准。就象以前注意到的从抽象处理器到实际处理器的映射是依赖于实现的。但是,能保证映射到一个抽象处理器上的元素将被映射到同一处理器上。在HPF中,也可以定义一个到标量处理器的映射,这对于不必分配的数据是有用的。实现可以指定这个数据到一个控制处理器(如果目标体系结构是一个SIMD的机器),其是在MIMD机器上的一种特别的处理器;或者在一个MIMD的机器上,把数据拷贝到所有的处理器上。
另一个观点是通过过程界限考虑数据的映射。典型的Fortran编译器一次只能编译一个程序单元,所以不能全局地确定分配。如果过量的再映射(remapping)不发生,那么编程者必须保证实参和行 参 分配之间的一致性。在HPF中,有一个语句(inherit)继承实参的分配。为给编译器足够的信息。也可以使用接口块(interface block),以便参数能被有效地再被分配到一个子程序中。
总之,HPF是描述数据到处理器映射的一种灵活的模型,并有丰富的指令支持这种模型。
| Copyright: NPACT |