| 4.9 全局归约操作(Global Reduction Operations) |
本节的所有函数在组内所有成员范围内实现全局归约操作(比如求和,求极大值,逻辑与等).这个归约操作即可以是MPI定义的操作,也可以是用户自定义的操作.全局归约操作分成几种类型:如将归约结果返回给一个节点的归约操作、将结果返回给所有节点的全局归约操作和搜索(或称并行前置)操作.另外,归约-分散操作是将归约和分散操作的功能合并起来.
MPI_REDUCE(sendbuf,recvbuf,count,datatype,op,root,comm)
IN sendbuf 发送消息缓冲区的起始地址(可变)
OUT recvbuf 接收消息缓冲区中的地址(可变,仅对于根进程)
IN count 发送消息缓冲区中的数据个数(整型)
IN datatype 发送消息缓冲区的元素类型(句柄)
IN op 归约操作符(句柄)
IN root 根进程序列号(整型)
IN comm 通信子(句柄)
int MPI_Reduce(void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, int root,
MPI_Comm comm)
MPI_REDUCE(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, ROOT, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, ROOT, COMM, IERROR
MPI_REDUCE将组内每个进程输入缓冲区中的数据按op操作组合起来,并将其结果返回到序列号为root的进程的输出缓冲区中.输入缓冲区由参数sendbuf、count和datatype定义;输出缓冲区由参数recvbuf、count和datatype定义;两者的元素数目和类型都相同.所有组成员都用同样的参数count、datatype、op、root和comm来调用此例程,因此所有进程都提供长度相同、元素类型相同的输入和输出缓冲区.每个进程可能提供一个元素或一系列元素,组合操作针对每个元素进行.例如,如果操作是 MPI_MAX,发送缓冲区中包含两个浮点数(count=2并且datatype=MPI_FLOAT),结果recvbuf(1)存放着所有sendbuf(1)中的最大值,recvbuf(2)存放着所有sendbuf(2)中的最大值.
4.9.2节中列出了MPI提供的定义操作,并且列出了每种操作所允许的数据类型. 同时用户也可以定义自己的作用于几种数据类型的操作,即可以是基本的也可以是派生的.这点将在4.9.4中进一步解释.
操作op始终被认为是可结合的,并且所有MPI定义的操作被认为是可交换的.用户自定义的操作被认为是可结合的,但可以不是可交换的.常规的对归约结果的估价顺序由组内各进程的序列号所决定,但在实现中可以借助于结合性的优点,或者利用结合性和交换性来改变对结果的估价顺序.但这可能改变有些对结合性和交换性没有特殊限制的操作结果,比如浮点加法.
对实现者的建议:强烈推荐在实现MPI_REDUCE时,当用同样的参数、同样的顺序调用此函数时,必须得到相同的结果.注意这可能妨碍对处理机物理位置进行的优化(对实现者的建议结尾)
在MPI_REDUCE中datatype的类型必须和op相兼容.MPI中定义的操作仅能作用于4.9.2节和4.9.3节中列出的数据类型.用户自定义的操作可以作用于通常的或派生的数据类型,,这种情况下归约操作中引用的这种数据类型的参数可能包含几个基本值.这将在4.9.4节中进一步说明.
MPI中已经定义好的一些操作,它们是为函数MPI_REDUCE和一些其他的相关函数,如MPI_ALLREDUCE、MPI_REDUCE_SCATTER和MPI_SCAN而定义的.这些操作用来设定相应的op.
名字 含义
MPI_MAX 最大值
MPI_MIN 最小值
MPI_SUM 求和
MPI_PROD 求积
MPI_LAND 逻辑与
MPI_BAND 按位与
MPI_LOR 逻辑或
MPI_BOR 按位或
MPI_LXOR 逻辑异或
MPI_BXOR 按位异或
MPI_MAXLOC 最大值且相应位置
MPI_MINLOC 最小值且相应位置
MPI_MINLOC和MPI_MAXLOC这两个操作将在4.9.3节中分别讨论.下面列出MPI中定 义的其他有关于op和datatype参数的操作以及它们之间允许的组合.首先列出基本数据类型组:
C语言中的整型 MPI_INT MPI_LONG MPI_SHORT
MPI_UNSIGNED_SHORT MPI_UNSIGNED
MPI_UNSIGNED_LONG
Fortran语言中的整型 MPI_INTEGER
浮点数 MPI_FLOAT MPI_DOUBLE MPI_REAL
MPI_DOUBLE_PRECISION MPI_LONG_DOUBLE
逻辑型 MPI_LOGICAL
复数型 MPI_COMPLEX
字节型 MPI_BYTE
对每种操作允许的数据类型如下:
操作 允许的数据类型
MPI_MAX, MPI_MIN C整数,Fortran整数,浮点数
MPI_SUM, MPI_PROD C整数,Fortran整数,浮点数,复数
MPI_LAND, MPI_LOR, MPI_LXOR C整数,逻辑型
MPI_BAND, MPI_BOR, MPI_BXOR C整数,Fortran整数,字节型
例4.15 由一组进程分布式地计算两个向量的点积,然后将结果返回到0号节点.
SUBROUTINE PAR_BLAS1(m, a, b, c, comm)
REAL a(m), b(m) ! 数组的局部部分
REAL c ! 结果变量(在0号节点)
REAL sum
INTEGER m, comm, i, ierr
! 局部和
sum = 0.0
DO i = 1, m
sum = sum + a(i)*b(i)
END DO
! 全局和
CALL MPI_REDUCE(sum, c, 1, MPI_REAL, MPI_SUM, 0, comm, ierr)
RETURN
例4.16: 由一组进程分布式地计算一个向量和一个数组的乘积,然后将结果返回到0号节点.
SUBROUTINE PAR_BLAS2(m, n, a, b, c, comm)
REAL a(m), b(m,n) ! 数组的局部部分
REAL c(n) ! 结果
REAL sum(n)
INTEGER n, comm, i, j, ierr
! 局部和
DO j = 1, n
sum(j) = 0.0
DO i = 1, m
sum(j) = sum(j) + a(i)*b(i,j)
END DO
END DO
! 全局和
CALL MPI_REDUCE(sum, c, n, MPI_REAL, MPI_SUM, 0, comm, ierr)
! 将结果返回0号节点(并在其他节点作废料收集)
RETURN
MPI_MINLOC操作符用于计算全局最小值和这个最小值的索引号,MPI_MAXLOC操作 符用于计算全局最大值和这个最大值的索引号,这两个函数的一个用途是计算一个全局最小值(最大值)和这个值所在的进程序列号.
MPI_MAXLOC被定义为:

这里 w=max(u,v) 且
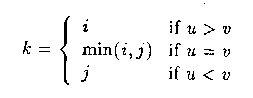
MPI_MINLOC被定义为:
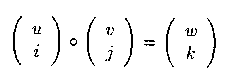
这里 w=min(u,v) 且

两个操作都是可结合、可交换的.如将MPI_MAXLOC应用于(u0,0),(u1,1),..,(un-1,n-1)这个序列上进行归约,那么(u,r)将被返回,这里u = maxiui且r是第一个全 局最大值所在的位置.这样如果组内的每个进程都提供一个值和它自身的序列号,那么op = MPI_MAXLOC的归约操作将返回其中的最大值和具有最大值的第一个进程的序列号.同 样MPI_MINLOC可以被用于返回最小值和它所在的位置.更一般地讲,MPI_MINLOC可以计算字典序的最小值,这里元素是按照值对中的第一个组分进行排序,而其索引号则由值对中的第二个组分进行求解.
这种归约操作作用于一个值对上,包括值和其索引号.在Fortran和C语言中,值对都要有相应的类型,这种参数的混合类型对Fortran语言来说是比较困难的.在Fortran中的解决方案是:值对中值的类型是相同的,都采用MPI中所提供的类型,并且索引号也必须具有和值相同的类型;在C语言中,这些值对可以有不同的类型且索引号必须是整型.
为了在归约操作中使用MPI_MINLOC和MPI_MAXLOC,必须提供表示这个值对(值及其索引号)参数的类型.MPI定义了七个这样的类型,MPI_MAXLOC和MPI_MINLOC 可以采 用下列的数据类型:
Fortran语言中:
名字 描述
MPI_2REAL 实型值对
MPI_2DOUBLE_PRECISION 双精度变量值对
MPI_2INTEGER 整型值对
C语言中:
名字 描述
MPI_FLOAT_INT 浮点型和整型
MPI_DOUBLE_INT 双精度和整型
MPI_LONG_INT 长整型和整型
MPI_2INT 整型值对
MPI_SHORT_INT 短整型和整型
MPI_LONG_DOUBLE_INT 长双精度浮点型和整型
类型MPI_2REAL可以理解成按下列方式的定义(见3.12节)
MPI_TYPE_CONTIGUOUS(2, MPI_REAL, MPI_2REAL)
MPI_2INTEGER、MPI_2DOUBLE_PRECISION和MPI_2INT的定义方式和MPI_2REAL 相仿,MPI_FLOAT_INT类型和下列指令等价:
type[0] = MPI_FLOAT
type[1] = MPI_INT
disp[0] = 0
disp[1] = sizeof(float)
block[0] = 1
block[1] = 1
MPI_TYPE_STRUCT(2, block, disp, type, MPI_FLOAT_INT)
MPI_LONG_INT和MPI_DOUBLE_INT的定义方式和MPI_FLOAT_INT相仿.
例4.17: 每个进程都有一30个双精度数的数组(以C语言为例),计算30个位置上的值并返回包含最大值的进程序列号.
/* 每个进程都有一30个双精度数组ain[30] */
double ain[30],aout[30];
int ind[30];
struct {
double val;
int rank;
} in[30], out[30];
int i, myrank, root;
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
for (i=0; i<30; ++i) {
in[i].val = ain[i];
in[i].rank = myrank;
}
MPI_Reduce(in, out, 30, MPI_DOUBLE_INT, MPI_MAXLOC, root, comm);
/* 此时结果归约到根进程 */
if (myrank == root) {
/* 读出其值 */
for (i=0; i<30; ++i) {
aout[i] = out[i].val;
ind[i] = out[i].rank;
}
}
例4.18: 和上例相同,只是用Fortran语言书写.
! 每个进程都有一30个双精度型的数组ain(30)
DOUBLE PRECISION ain(30), aout(30)
INTEGER ind(30);
DOUBLE PRECISION in(2,30), out(2,30)
INTEGER i, myrank, root, ierr;
MPI_COMM_RANK(MPI_COMM_WORLD, myrank);
DO I=1, 30
in(1,i) = ain(i)
in(2,i) = myrank ! myrank必须是一个双精度型
END DO
MPI_REDUCE(in, out, 30, MPI_2DOUBLE_PRECISION, MPI_MAXLOC, root,
comm, ierr);
! 此时结果归约到根进程
IF (myrank .EQ. root) THEN
! 读出其值
DO I = 1, 30
aout(i) = out(1,i)
ind(i) = out(2,i) ! rank被强制转换回整型
END DO
END IF
例4.19: 每个进程有一个非空数组,找出全局最小值、拥有此最小值的进程序列号及在此进程的位置.
#define LEN 1000
float val[LEN]; /* 局部数组 */
int count; /* 局部值 */
int myrank, minrank, minindex;
float minval;
struct {
float value;
int index;
} in, out;
/* 局部最小值及其索引号 */
in.value = val[0];
in.index = 0;
for (i=1; i < count; i++)
if (in.value > val[i]) {
in.value = val[i];
in.index = i;
}
/* 全局最小值及其索引号 */
MPI_Comm_rank(MPI_COMM_WORLD, &myrank);
in.index = myrank*LEN + in.index;
MPI_Reduce(in, out, 1, MPI_FLOAT_INT, MPI_MINLOC, root, comm);
/* 此时结果返回到根进程 */
if (myrank == root) {
/* 读出其值 */
minval = out.value;
minrank = out.index/LEN;
minindex = out.index%LEN;
}
原则: 对MPI_MINLOC和MPI_MAXLOC的定义提供了这样一种好处:它可以不经过任 何特殊处理完成两个操作,其过程和其他归约操作很相象.程序员可以按其愿望对MPI_MAXLOC和MPI_MINLOC 进行定义.其缺限是值和索引号必须交错放置,并且在 Fortran语言中值和索引号的类型必须一致.(原则结尾)
MPI_OP_CREATE(function, commute, op)
IN function 用户自定义的函数(函数)
IN commute 可交换则为true,否则为false
OUT op 操作(句柄)
int MPI_Op_create(MPI_User_function *function,int commute,MPI_Op *op)
MPI_OP_CREATE(FUNCTION, COMMUTE, OP, IERROR)
EXTERNAL FUNCTION
LOGICAL COMMUTE
INTEGER OP, IERROR
MPI_OP_CREATE将用户自定义的操作和op绑定在一起,可以用于函数MPI_REDUCE 、MPI_ALLREDUCE、MPI_REDUCE_SCATTER和MPI_SCAN中.用户自定义的操作被认为是可以结合的.如果commute=true,则此操作是可交换且可结合的;如果commute=false,则此操作的顺序是固定地按进程序列号升序方式进行,即从序列号为0的进程开始.
function是用户自定义的函数,必须具备四个参数: invec, inoutvec, len和datatype.
在ANSI C中这个函数的原型是:
typedef void MPI_User_function(void *invec, void *inoutvec,
int *len, MPI_Datatype *datatype);
在Fortran中对用户自定义的函数描述如下:
FUNCTION USER_FUNCTION(INVEC(*), INOUTVEC(*), LEN, TYPE)
<type> INVEC(LEN), INOUTVEC(LEN)
INTEGER LEN, TYPE
参数datatype用于控制传送给MPI_REDUCE的数据类型.用户的归约函数应当写成下列方式:当函数被激活时,让u[0],...,u[len-1]是通信缓冲区中len个由参数invec、len和datatype描述的元素;让v[0],...,v[ len- 1]是通信缓冲区中len个由参数inoutvec、len和datatype描述的元素;当函数返回时,让w[0],...,w[len-1]是通信缓冲区中len个由参数inoutvec、len和datatype描述的元素;此时w[i] = u[i]·v[i] ,i从0到len-1,这里·是function所定义的归约操作.
从非正式的角度来看,我们可以认为invec和inoutvec是函数中长度为len的数组,归约的结果重写了inoutvec的值.每次调用此函数都导致了对这len个元素逐个进行相应的操作,例如:函数将invec[i]·inoutvec[i]的结果返回到inoutvec[i]中,i从0 到count-1,这里·是由此函数执行的归约操作.
原则: 参数len可以使MPI_REDUCE不去调用输入缓冲区中的每个元素,也就是说,系统可以有选择地对输入进行处理.在C语言中,为了与Fortran语言兼容,此参数以引用的方式传送.
通过内部对数据类型参数datatype的值与已知的、全局句柄进行比较,就可能将一个用户自定义的操作作用于几种不同的数据类型.(原则结尾)
通常的数据类型可以传给用户自定义的参数,然而互不相邻的数据类型可能会导致低效率.
在用户自定义的函数中不能调用MPI中的通信函数.当函数出错时可能会调用MPI_ABORT.
对用户的建议:假设用户建立了一个可重载的自定义归约函数库:在每次调用时,根据操作数的类型,参数datatype用于选择正确的执行路径.用户自定义的归约操作不能对传送给它的数据类型进行"译码"操作,也不能自动识别数据类型句柄和它所代表的数据类型之间的对应关系.这种对应关系应当在建立数据类型时完成.在使用这个库时,必须先执行库初始化操作,初始化时将定义库中要使用的数据类型,并将其句柄存放到可以被用户代码和程序库代码能访问到的全局、静态变量中.
Fortran版本的MPI_REDUCE将用Fortran语言中调用方式来调用一个用户自定义的归约函数,并传给它一个Fortran中的数据类型;C版本的MPI_REDUCE以C语言的方式和C语言中这种数据类型句柄来调用此函数.应用混合型语言的用户须定义相应的归约函数(对用户的建议结尾)
对实现者的建议:下面给出MPI_REDUCE本质的但非高效的实现过程.
if (rank > 0) {
RECV(tempbuf, count, datatype, rank-1,...)
User_reduce(tempbuf, sendbuf, count, datatype)
}
if (rank < groupsize-1) {
SEND(sendbuf, count, datatype, rank+1,...)
}
/* 结果位于进程groupsize-1上,现在将其发送到根进程 */
if (rank == groupsize-1) {
SEND(sendbuf, count, datatype, root, ...)
}
if (rank == root) {
RECV(recvbuf, count, datatype, groupsize-1,...)
}
归约操作顺序地、依次地从进程0计算到进程groupsize-1.这样选择顺序的原因是为了照顾用户自定义的User_reduce函数中有些操作的顺序是不可交换的.更有效的实现方法是采用可结合性的特点或应用对数树形归约法.对于在MPI_OP_CREATE 中 commute为true的情况,还可以利用可交换性的特点,也就是说可以对缓冲区中的一部分数据进行归约操作,这样通信和计算就可以流水执行,即可以传送的数据块的长度len可以小于count.
MPI中定义好的操作可以作为用户自定义操作的一个库,但为获得更好的性能,MPI_REDUCE应根据具体情况特殊处理(对实现者的建议结尾)
MPI_OP_FREE(op)
IN op 操作(句柄)
int MPI_op_free(MPI_Op *op)
MPI_OP_FREE(OP, IERROR)
INTEGER OP, IERROR
如要将用户自定义的归约操作撤消,将op设置成MPI_OP_NULL.
应用用户自定义的归约操作的例子
例4.20 计算一个复数数组的积(用C语言编程)
typedef struct {
double real,imag;
} Complex;
/* 用户自定义的函数 */
void myProd(Complex *in, Complex *inout, int *len, MPI_Datatype *dptr)
{
int i;
Complex c;
for (i=0; i < *len; ++i) {
c.real = inout->real*in->real - inout->imag*in->imag;
c.imag = inout->real*in->imag + inout->imag*in->real;
*inout = c;
in++; inout++;
}
}
/* 然后调用它 */
/* 每个进程都有一个100个元素的复数数组 */
Complex a[100], answer[100];
MPI_Op myOp;
MPI_Datatype ctype;
/* 告之MPI复数结构是如何定义的 */
MPI_Type_contiguous(2, MPI_DOUBLE, &ctype);
MPI_Type_commit(&ctype);
/* 生成用户定义的复数乘积操作 */
MPI_Op_create(myProd, True, &myOp);
MPI_Reduce(a, answer, 100, ctype, myOp, root, comm);
/* 这时结果(为100个复数)就已经存放在根进程 */
MPI中还包括对每个归约操作的变形,即将结果返回到组内的所有进程.MPI要求组内所有参与的进程都归约同一个结果.
MPI_ALLREDUCE(sendbuf, recvbuf, count, datatype, op, comm)
IN sendbuf 发送消息缓冲区的起始地址(可变)
OUT recvbuf 接收消息缓冲区的起始地址(可变)
IN count 发送消息缓冲区中的数据个数(整型)
IN datatype 发送消息缓冲区中的数据类型(句柄)
IN op 操作(句柄)
IN comm 通信子(句柄)
int MPI_Allreduce(void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, MPI_Comm comm)
MPI_ALLREDUCE(SENDBUF, RECVBUF, COUNT, DATATYPE, OP, COMM, IERROR)
<type> SENDBUF(*), RECVBUF(*)
INTEGER COUNT, DATATYPE, OP, COMM, IERROR
除了将结果返回给组内的所有成员外,其他同MPI_REDUCE.
对实现者的建议: 全局归约操作(all-reduce)可以由归约操作reduce和广播操作(broadcast)来实现,但直接实现可以获得更好的性能.(对实现者的建议结尾)
例4.21: 在一组分布式的进程上计算一个向量和一个数组的乘积,并将结果返回到所有节点上(见例4.16).
SUBROUTINE PAR_BLAS2(m, n, a, b, c, comm)
REAL a(m), b(m,n) ! 局部数组
REAL c(n) ! 结果
REAL sum(n)
INTEGER n, comm, i, j, ierr
! 局部和
DO j = 1 , n
sum(j) = 0.0
DO i = 1, m
sum(j) = sum(j) + a(i)*b(i,j)
END DO
END DO
! 全局和
CALL MPI_ALLREDUCE(sum, c, n, MPI_REAL, MPI_SUM, 0, comm, ierr)
! 将结果返回给所有节点
RETURN
| Copyright: NPACT |