图1. 大规模计算和Web技术的集成
Web上的计算 -- 2007年以并行处理方式实现Petaop和Exaop性能的新方法
January 1, 1997
Geoffrey C. Fox
gcf@npac.syr.edu
Wojtek Furmanski
furm@npac.syr.edu
http://www.npac.syr.edu
Northeast Parallel Architectures Center
111 College Place
Syracuse University
Syracuse, New York 13244-4100
Phone: (315)443-2163 Fax: (315)443-4741
2007年,中央并行处理器将可望达到Petaop(1015次操作/秒)的性能,而国家信息基础设施或Web将带给我们分布式的Exaop(1018次操作/秒)性能.这种趋势(提供诱人的编程环境)将为高性能仿真领域提供一些新的机遇.
我们很关注2007年,因为那时候国家信息基础设施(NII)之上将出现很多个数字多媒体信息系统.我们假设(定义)那时的软件环境是从现在的Web技术发展而来的,同时假设流行的ATM/ISDN/ADSL/卫星/...等通信网络就是发展中的Internet.同时2007年也是并行处理领域中一个值得重视的时间,因为政府所认可的此研究领域的"未来"目前指的就是这个年限(http://www.aero.hq.nasa.gov/hpcc/petaflops/peta.html, http://www.npac.syr.edu/users/gcf/hpcc96petaflops).那个时候将出现好几种新的体系结构与现有的主流方法相竞争的局面,并行超级计算机预期将达到0.1到10Petaops的性能.
最近,Sandia国家实验室的研究人员声称(http://www.intel.com/pressroom/archive/releases/cn121796.htm)在能源部的一台机器上运行ASCI(http://www.llnl.gov/asci/)程序获得了超过1 Teraop(1012次操作/秒)的速度.这台机器高效地连接了10,000个Intel PC的CPU,其中每个CPU的性能都超过100 Megaflops.再有,由高速以太网连接的16个PC处理器执行宇宙物理学程序时也实现了超过1Gigaflops的性能([Taubes:96], http://www.cacr.caltech.edu/research/beowulf/).这些例子表明,商用CPU和网络及Web或Internet作为计算资源将可能起到很重要的作用.如今,连接到Web上的众多计算机比Sandia实验室的可利用资源要多得多,估计可能有100,000个主机和数以百万计的客户计算机. 最终我们希望全球范围的、数以百万计的PC类设备连接起来以构成一个公共的信息网络.
简而言之,Web是一个松散连接的数以千万计的计算机的集合;中央的并行超级计算机提供了高性能CPU之间的客户化网络.当然,MPP的客户化网络比起当前或将来全球范围的网络具有潜在的高频带和低延迟特性,即便MPP是建立在商用PC机的CPU和ATM网络上也是如此.在本文中,我们从计算方法的角度来对比一下Web和MPP, 来看看在进行大规模计算中,这两种方法是如何协作来解决不同应用问题的(http://www.npac.syr.edu/users/gcf/sc96tutorial, http://www.npac.syr.edu/users/gcf/hpcc96web, http://www.npac.syr.edu/users/gcf/javaforcsefall96).
当前,Web上有很多并行机,但是它们与通过网络来访问共享服务器的客户机之间有着很大的独立性.最大规模的并行计算机其处理器的数目与Web上计算机的数目相比差很多个数量级 - 如Sandia中计算机处理器数为10,000个,而Web上的计算机至少有几百万个.并行计算机有什么特殊之处呢?答案是,并行处理系统中的处理器之间是紧耦合协作来解决一个大型问题的,这种协作从技术的角度来看是很困难的.在本文中,我们希望Web的软件和硬件在解决这类协作计算上起一个重要的作用.这里在"协作"和"非协作"计算之间没有一个很清晰的分界线.事实上,如果我们有一个基于Web的Intranet,那么众多雇员就可以以Web上客户的方式来访问中央数据库,这样公司的老板就可以通过这种形式使得他们的公司获得最大限度的成功,而且中央(或分布式的)数据库实际上可以用一些复杂的并行控制和并行锁的管理来实现这种协作.如当一个华尔街的经纪人在他们的并行计算机上进行Monte Carlo仿真时,大部分工作都是独立的,仅在处理全局平均值时需要协作,这时就要用到一个公共的输入数据.
在讨论Web上的计算时,我们需要独立地考虑硬件、软件和应用领域.上述的讨论也可表明,如今Web可用来解决尖端的"某种程度上协作"的问题,而大规模并行计算机经常用来解决"大规模非协作"(从技术的角度来看就是难以并行的问题)的算法如Monte Carlo仿真. 在本文的后面我们将讨论不同的应用问题类及与它们相适应的硬件与软件问题.
提到硬件问题,World Wide Web比起专用的并行计算机具有低带宽和高延迟的特点,在地理上分布的网络中延迟是不可避免的.然而在由ATM/快速以太网连接起来的PC机和工作站所构成的Intranet中,足以获取和专用并行机相对抗的性能([Taubes:96], http://www.cacr.caltech.edu/research/beowulf/ http://cesdis.gsfc.nasa.gov/linux-web/beowulf/beowulf.html http://www.epcc.ed.ac.uk/epcc-tec/documents/techwatch-harnessing/).现在Web的某些性能缺限正反映了此领域尚处在一个发展的初级阶段,未来Web将在性能上得以进一步地增强,并且将产生一些专用的软件和硬件.
最后,软件也是一个含糊不清的领域,但与硬件相比却有一些不同之处.就象以下要阐述的那样,可以利用"Web技术"将众多的系统软件集成起来组成一个强大的系统进行并行计算[Fox:95a,95d,96a].Web服务器将替代经常在并行计算机中用以控制各节点的守护进程(daemon);而Java语言的杰出表现也足以向仿真领域的Fortran和C++提出挑战;Java、VRML和Web客户机可以构造包括可视化在内的良好用户界面.这里,我们希望软件产业将精力多放到这个巨大的市场(Web)上,用它来为相对较小的并行计算领域提供必要的基础设施,而后者可以集中开发那些专家经验仍起重要作用的领域.支持所谓的"分布式共享存储"的并行编译器就是一个很好的例子,它支持常规的编程环境,可以在单一的共享存储模型中进行复杂的协作处理.在Web环境中实现一个这样的编译器将会对这个世界产生重大影响,也是为某些小领域的专门经验和需求提供增值服务的一个例子.
这样,在研究"Web上的计算"时,我们总是将并行和分布式计算、专用和通用网络互连、Intranet和Internet的概念合并起来,其目的就是利用一组各具特色的由网络连接起来的计算机资源来协作求解一个问题.如在上面所举的例子中,我们将看到带有特定用户特色和优化连接的硬件设计、软件系统和应用领域,而且还可能有进一步合并的趋势.例如,Web可通过融入协作(同步)和良好的并行算法来充分发挥其资源的能力去求解一个问题.并行计算团体可以继承杰出的分布式计算软件的成果,并充分利用多种非富的计算平台.
如今,大规模超级计算机(内部总是包括各种并行性)可以提供接近于1012次操作/秒的性能 - 通过104个高性能个人机或工作站的高效合作.
我们将跟踪所谓的政府Petaflops性能研究(http://www.aero.hq.nasa.gov/hpcc/petaflops/peta.html),并展望未来10年半导体工业的进展. 2007年高性能CPU芯片估计将可达到约32 Giga(fl)ops的速度,这将通过某种形式的内部并行性来得到.基本计算单元将有1 GHz的时钟频率和32路的芯片内部并行性,计算机内存也期望达到约2 Gigabyte的容量(http://www.npac.syr.edu/users/gcf/petastuff/petasoftwp).在表1中,我们列举了一些建立在常规和外来技术上的并行处理器,如超导体材料的处理器或一些新颖的结构如"内存中的处理器(processor in memory)" - 即在一个芯片中CPU与内存是交错排列的. 我们对比了它与两种基于Web的并行系统 - 企业Intranet或由家庭PC机(或其他数字设备)组成的Web.
表 1: 2007年超级计算机结构
中央并行处理器(Giga = 109, Tera = 1012, Peta = 1015,
Exa = 1018)
A: 常规的分布共享存储的Silicon结构
B: 内存中的处理器(PIM)设计
C: 超导体设计方案
D: 分布式Web计算机 -- 大公司的IntraNet
E: World Wide Web
到2007年,大公司的Intranet或一些超级计算机将可能达到几百Teraops的性能,这些超级计算机的新颖体系结构可以将性能提高一个数量级,而Web至少可以将这种潜在的性能再提高三个数量级.当然, 超级计算机和Web性能上的1,000倍的差异在一定程度上反映了社会的投资程度,一台超级计算机的价格约在2千万美元到1亿美元之间,而计算机产业/娱乐产业每年对Web的投资将比这多几千倍.
为了使并行计算机有效地工作,各个不同的处理器之间必须彼此进行通信,寻求一合适的解决方案,这也是计算机体系结构研究中一个热点,我们可以将其以一种简单的形式放到Web计算机上加以解决.第一,所需要的通信频宽与处理的应用问题密切相关,对于上面所谈到的一些难以并行的应用来说可能很低,而对于并行流体动力学计算问题来说则可能会很高.在后一种情况中,每个字所需的通信时间tcomm 与典型的计算时间tcalc是密切相关的,tcomm≤tcalc×(节点内存/64M字节)1/2.注:一个字为64比特,并且当今的典型内存大小为64 Megabytes.
"50"代表着每条通信消息所对应的典型操作数,内存比例的平方根表示随着内存容量的增加,对并行处理所需要的频宽将相应地减少.这从直觉上来看也是合理的,因为两个实体之间的通信有一种"边缘"效应,而平方根则来自于一个区域的自然的二维边界 -- 我们通常采用2维结构表示地理上分布的计算机之间的几何形状(详见http://www.npac.syr.edu/copywrite/pcw/里的第三章).
在表1的D)项中,企业内IntraNet中的每台计算机需要4 Gigabits/秒的通信频宽,在高性能ATM支持下实现此目标是比较现实的.
并行机的另外一个有趣特性是将机器一分为二时的交叉部分带宽或总体通信性能.由于需要将Web变成一个"真正并行的计算机",所以我们必须对全国内的通信频宽作一估计.利用一个简单的几何参数,我们可以得到整个中心地区总的频宽如下:4 Gigabit/秒×(200×106 - 机器数)1/2.
简而言之,2007年利用Intranet和专用并行机对"协作式"问题求解时可能获得Petaop的性能.而整个Web蕴含着更大的潜力,只不过是它仅适应于那些耦合非常弱的应用问题,因为网络的性能对一些应用问题来说还是远远不够的.
为了进一步理解大规模仿真领域中Web所起的作用,有必要将问题中不同类别的并行性划分成4类([Fox:96b]).
典型的元级问题其并行性是中等粒度的,它们不同于上面第2类中的例子 - 各个单元粒度较大并且具有更多的自包含性,它们可以适应于不同的计算机结构.而(2)中所提到的中等粒度的功能并行性需要低延迟和高带宽的通信来保证 - 典型的处理是在共享存储的计算机上实现.元级问题可以在分布式(Web)环境中很自然地实现 - 并不经常要求很低的延迟,同时所要求的网络通信带宽可以在一个较大的范围内变动.
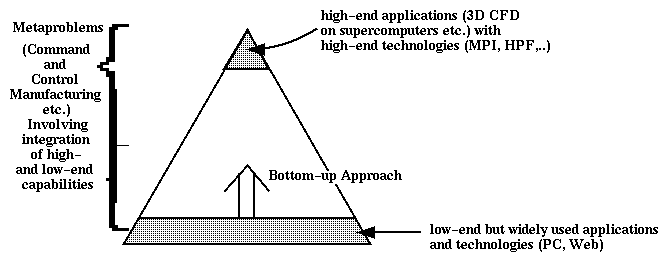
我们一直在考虑可能的软件模型,以适应于第III部分提及的不同的并行和分布式计算机.如图1所示,我们可以将计算需求看成是一个金字塔结构,其底层是广泛应用的廉价系统,在顶层则是少数高性能计算机系统.从我们上面分析可以看出,面向客户的产品 - PC机、视频游戏机、个人数字助理、数字桌面设备等具有更强大的计算能力.由于社会对面向用户的产品所进行的投资占主要的份额,所以为金字塔底层系统所设计的软件要比上层系统好得多.PC机的市场主宰着高质量的用户软件的发展,而对并行处理领域来说则很难从中受益.毫无疑问PC机上运行的是串行计算模型,而当前Web软件的目标是提供非富的分布式计算模型.对我们来说最清楚不过的是以MPP软件作为Web软件的基本框架,就象在第II部分中讨论的那样,我们可以将并行处理看成是一个带有很强同步限制的特殊分布式处理模型.我们认为这将促使计算Web的产生,就象下几部分描述的一样.
这种方法有一个特殊的优势,可以利用运行着同步/运算增强型Web软件的Web客户机和服务器来构造计算Web,或者将运算增强型Web软件放在专用的MPP系统(它的低延迟和高通信带宽可以进行严格的并行计算)上以提供一个诱人的用户环境.
下面,我们讨论Web硬件和三个不同计算部分的软件所起的作用,如图2所示.
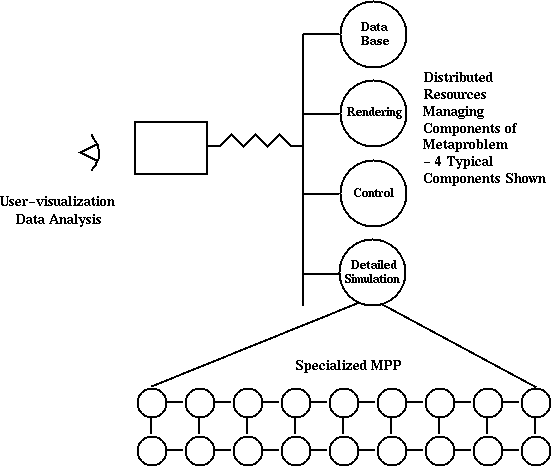
在以下三个部分中,我们讨论的问题将涉及到三个部分 -- 用户图形界面,元级问题/软件集成中的数据流和核心计算.
我们可以将高性能计算环境抽象成4个层次,见图3及下面的说明(http://www.npac.syr.edu/users/gcf/petastuff/petasoftwp).
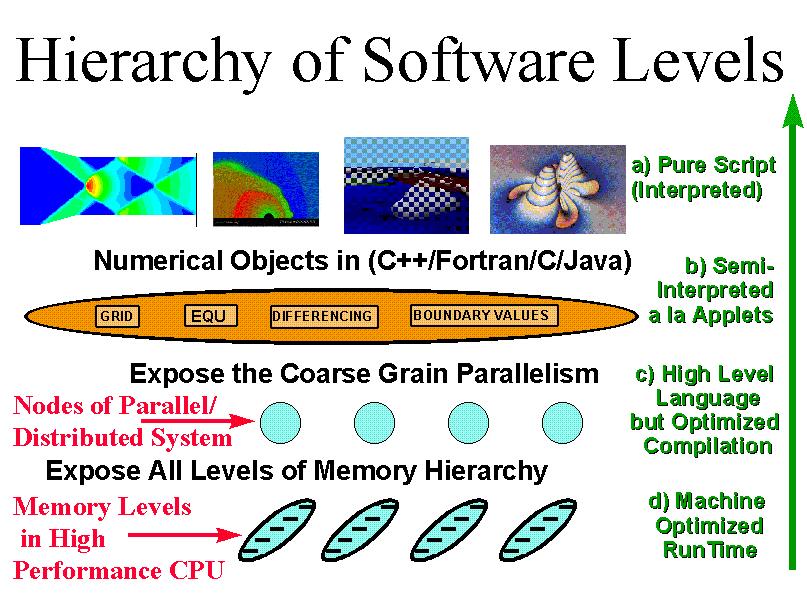
这是一个典型的图形界面,允许在元级计算机或单独的组成部分层次上对其进行操作.
一定性能价格条件下的可移植的灵活编程 - 这在Java的applet方式中可以体现出来
提供一种高性能的、与机器相关尽可能少的高级语言
应用程序员甚至编制(高层次)工具的开发者都很少涉及这个层次.很明显,在非常特殊编程环境下,它可以使用户获得接近机器峰值的性能.
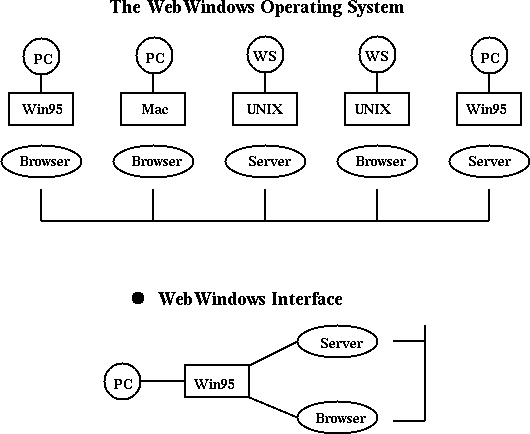
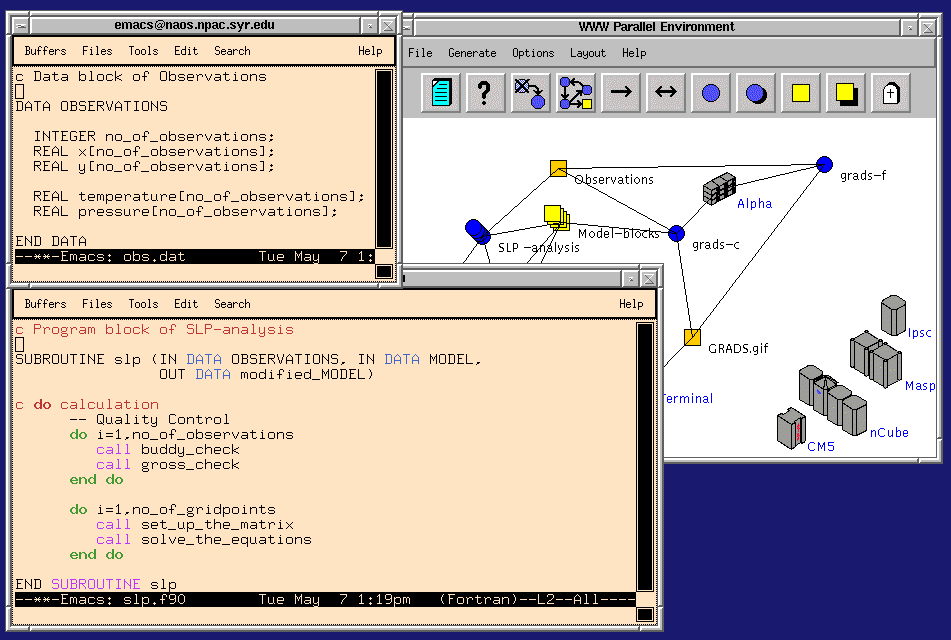
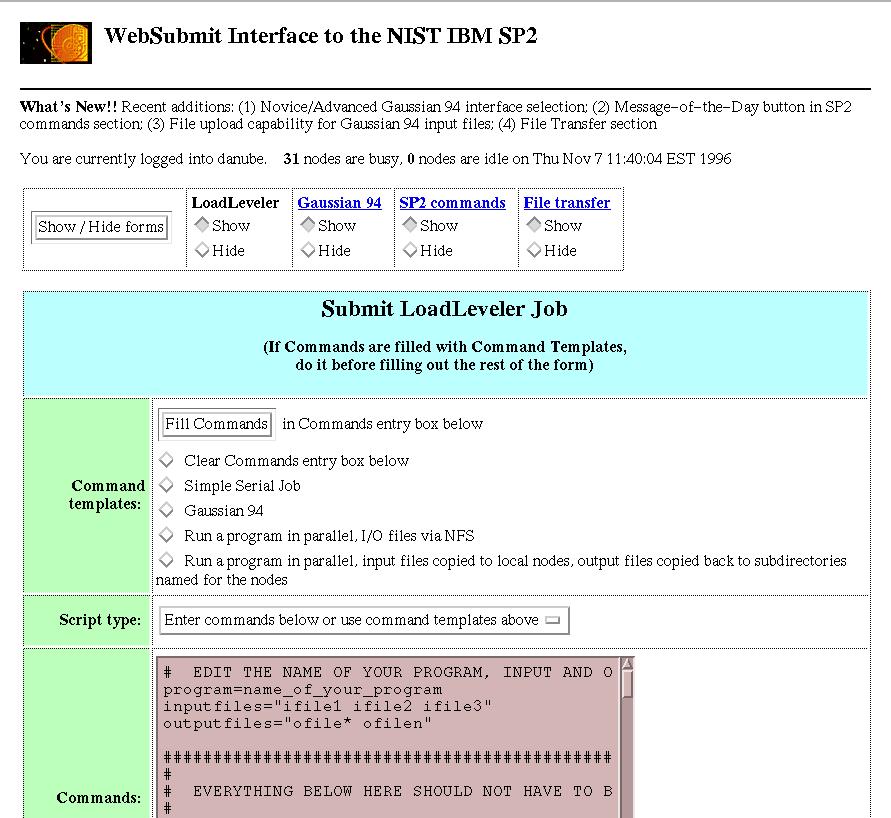
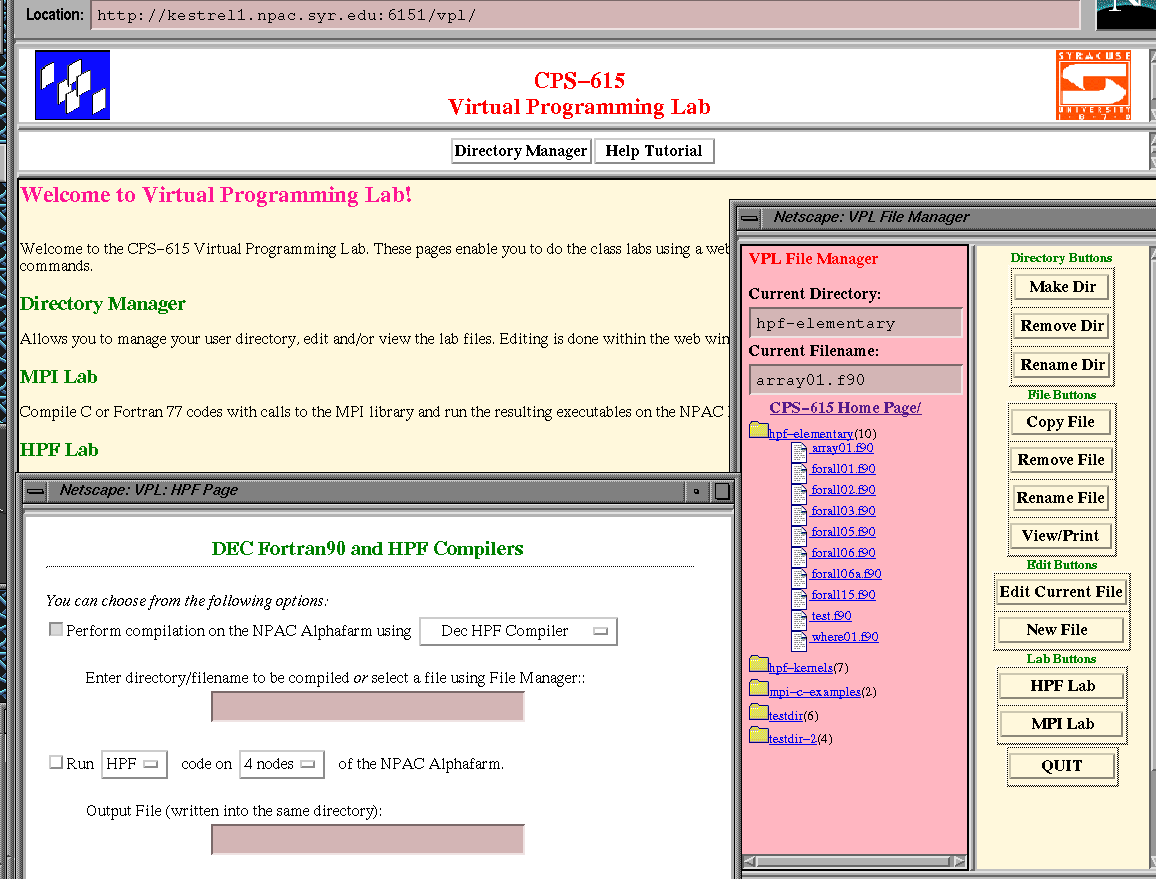
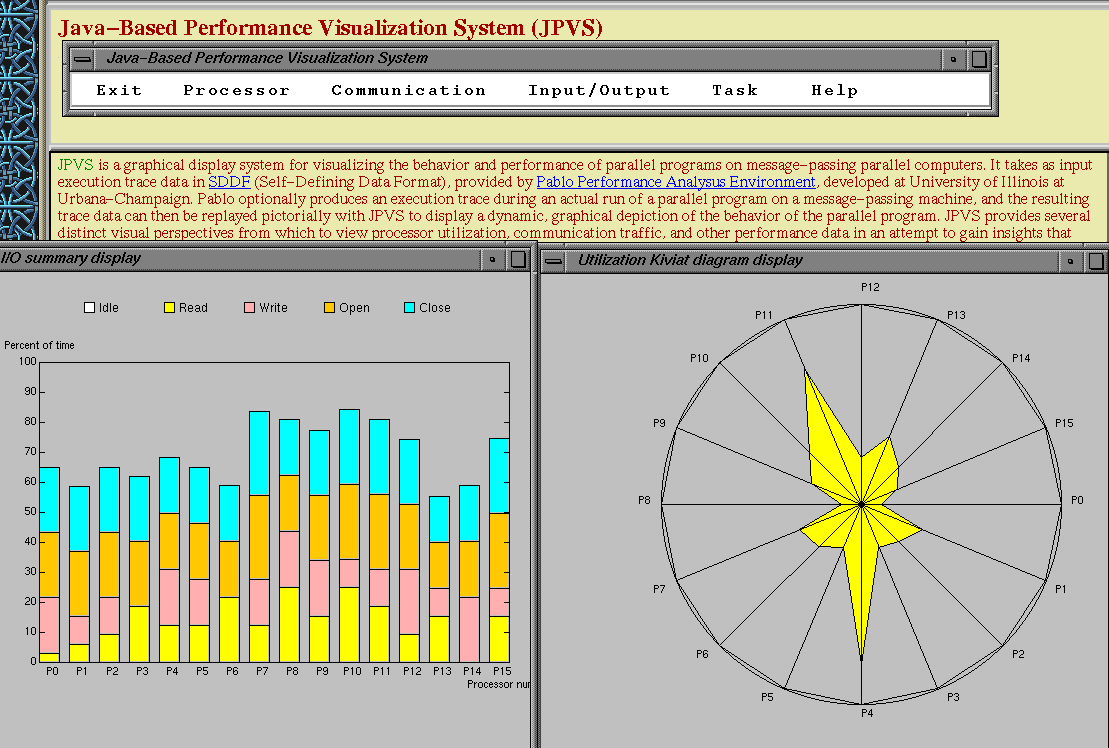
c)层和d)层包括与计算问题本身关系最为密切的部分,它可以在某些合适的服务器上实现,但是本部分中讨论的a)层和b)层则可能要在用户的机器/环境下执行.我们认为当前软件产业的趋势([Fox:95d,96c])是从基于PC Windows、Macintosh、UNIX的环境向基于WebWindows的环境发展,如建立在Web服务器和Web客户机接口之上的软件.在图4中,不论是面对一台独立的计算机编写程序还是面向整个环球网编程都应当是一样的.从这种意义上讲,是否在用户接口处采用Web技术并不重要 - 高性能计算虽然很困难,但它并没有对用户接口加入过多的限制,因为它运行在"常规"的客户端,可以很自然地利用客户端最好的技术.图5-9举了一些这方面的例子:
我们期望对这种类型接口的开发将继续下去并形成一种标准.另外根据图3)中的层次b)可以看出,Java(和VRML)将起重要的作用.也就是说,在建立客户端数据分析系统方面,Java是一种非常吸引人的语言,这在计算和可视化方面都有体现 - 尤其是在二者连接时,Java具有独特的能力.因此我们希望开发一组高质量的Java applet(或编译型的plug-in模块)来支持这种分析工作.一般用户能在图3的层次a)上使用这些applet,但要对其进行专门的修改以使其具有特定功能.Cornell大学已经开发了一个这样的实例(http://www.msc.cornell.edu/~houle/cracks),它将Java用于科学可视化领域,各个applet对断裂力学课程进行讲授.图10中描述了一个这样的综合环境,它用传统的编程语言给Java加了一层包装,可以运行在串行、并行或分布式的计算机上.Java的这种应用很容易被扩展,因为它不需要对已经存在的代码做太大的改动,并且在不改变用户已经熟悉的编程模式条件下进一步为其提供增值服务.我们将它看成是Web上的一颗"种子",必将进一步促使Java应用的更广泛流行,就如第VIII部分中所阐述的那样.
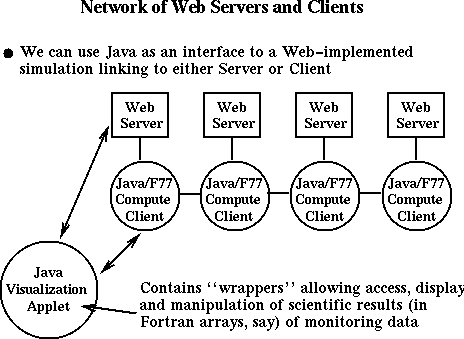
图10
正象我们已经讨论过的那样,利用Web硬件和软件实现元级问题的控制是很自然的想法(http://www.npac.syr.edu/projects/webbasedhpcc).尽管在本文的第V部分中我们仅描述了为此而设计的数据流模型,但人们可以将这种思想应用到任何应用中(由多个相互连接的子部分构成,各个子部分又由相对较大的计算模块组成),即将Web看成为一个计算引擎(compute engine).事实上,可以把我们最近完成的130位RSA因数分解工作也归为这一类(http://www.npac.syr.edu/users/gcf/crpcrsamay96),它将筛选操作分布到一组不同的客户机上(从NPAC的IBM SP2到英国的386型膝上机),并在一组服务器的控制下进行求解.作为一系列Web服务器的CGI Perl脚本的FAFNER它已经被实现(图 11取材于Jim Cowie,它是一个位于http://www.npac.syr.edu/projects/factoring/status.html的协作系统).它们创建守护进程来控制每个客户机上的计算,并将结果返回到服务器,服务器收集这些结果后再进行最终的寻找因子处理.在它以后的更有趣的实例(155位十进制或512位二进制数的因数分解)需要1个月的teraop计算量(10,000台Pentium Pro PC机要运行1个月),它将成为基于Web的计算方面的一个很实在的例子.在许多银行系统中都采用512位二进制数的因数分解作为安全体制的基础,他们可能没有认识到现代的计算可以破译这个密码.
从完成因数分解的经验([Fox:95a])中我们能抽象出两种类型的计算任务.第一种是资源管理问题 - 识别Web上的计算机资源;分配给它们合适的任务;需要时让它们为用户服务等.ARMS(Figure 12)就是一个位于Cornell理论中心由Lifka开发的复杂Web系统. 在这个领域内知名的分布式计算系统还包括LSF、DQS、Codine和Condor(见http://rhse.cs.rice.edu/NHSEreview/96-1.html).
第二种是一个给定任务中的实际同步问题 - 资源管理,在另一方面,就是将一组任务分布到一组机器上,而不卷入到详细的并行计算算法和同步问题中.这里我们看一个基本概念:在各节点间提供消息支持,最终在World Wide Web生成一个并行虚拟机.
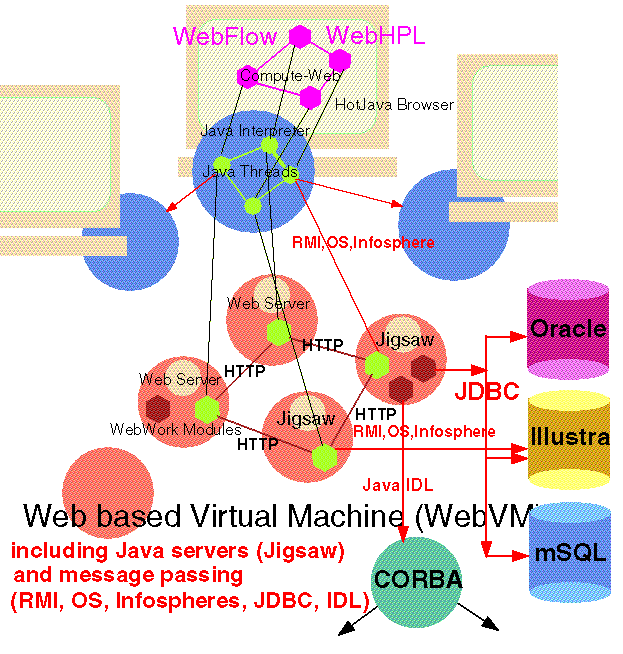
在图13中低层支持称作为WebVM,它必须实现并行系统的某些功能,如在消息系统中利用Web技术(HTTP或用Java直接进行服务器-服务器/客户的连接)实现MPI的功能.尽管目前功能最强的实现方式是象FAFNER那样,由少数几个Web服务器控制多个Web客户机所组成的mesh结构(http://www.cs.ucsb.edu/~schauser/papers/96-superweb.ps, http://www.javaworld.com/javaworld/jw-01-1997/jw-01-dampp.html),我们还是认为最可能的、最精巧的模型是由Web服务器组成的mesh结构.根据WebWindows(图4)的思想,我们期望连接到Web上的所有机器都可具备服务器或相当于服务器的处理能力.注意自然的Web模型是服务器-服务器模式,而不是服务器-客户模式,事实上这是传统NII上实现民主的梦想 - 即每个人都有能力发布或共享信息.
在WebVM的上面,可能建立更高层次的系统,如第II部分中的分布共享存储模型(图13中称作WebHPL)或更容易的显式消息传递系统,如数据流模型.支持图形界面的WebFlow(图13和14,[Fox:95a,95d], http://www.npac.syr.edu/projects/webspace/doc/webflow/dual96.html, http://www.npac.syr.edu/projects/webspace/doc/sc96/handout/handout.ps)描述了元级问题中各个组成部分的连接情况,按照这个框架可以很自然地设计出领域内特定的问题求解环境.
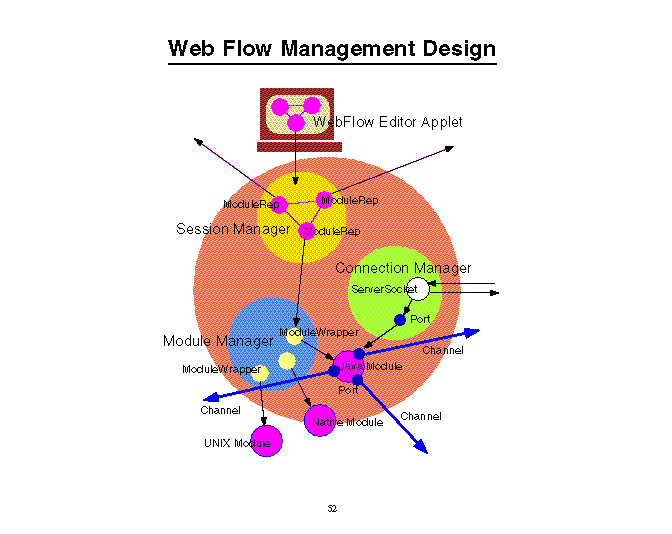
在图3的表示中,系统应在层次a)上对脚本化的"小语言"(为每个应用而设计)提供支持,它可以动态地、灵活地连接元级问题的各个组成部分.图14中提出了一个Java服务器的实现方案,它用servlet(由JavaSoft的Jeeves服务器支持)实现.
目前这些还处在一个混乱时期,如表2中所示,在日益涌现的Web技术领域中有很多主要厂商对此进行大力开发,因此也相应地带来许多计算机-Web的实现策略,特别是发展到功能强大的、位于服务器端的CGI技术,它将Java客户机和服务器系统动态地集成起来.尽管现在还不是"最终解决"的时候,但其经验和灵活性可以检验并影响未来Web计算机的关键构成部分.
表2: WebVM的组成部分:实现选择
| Habanero | Jigsaw | Infospheres | JavaSoft | Netscape | |
|---|---|---|---|---|---|
| Module | collaboratized applet |
Resource | dapplet | Java Bean | LiveWire app, server |
| Port/Channel | Java socket | any HTTP carrier |
portlet | RMI | custom? |
| Message | Marshalled Event or Action |
Pickled Resource |
any object bytesteam |
Serialized Object |
JavaScript |
| Compute-Web | Star topology | 2-node | any topology | ||
| Runtime | Collaboratory server |
Java HTTP server |
dapplet manager? |
Jeeves (Java server) |
community or enterprise system |
| User Interface |
AWT | Forms | Visual Authoring? |
HotJava | Navigator |
| Coordination | instantaneous broadcast |
client-server | asynchronous multi-server |
CORBA | multi-server |
| Persistency | Resource Store | flat file? | JDBC | Live Wire -> DB | |
| Publication | javadoc |
注意Web鼓励这样的新型计算模型 - 问题一方提出他们的需求,Web计算机引擎发布其计算能力,然后将这些问题与计算机资源再进行合理的匹配.
可移动代码(mobile code)和由动态agent构成的计算环境的潜在能力与此领域相关并包含在动态WebFlow模型中,执行代码的可移动性是在主流计算研究实验室的Java语言中提出的,目前它主要应用于从服务器端移到客户端的applet中.但随着Web上的计算从客户-服务器向服务器-服务器的转移,我们将看到一个新的家族 -- Java agent的出现,它在Web上漫游,派生从属agent,播发并收集指定信息然后返回给用户.一旦产业界在一些领域如数据发掘(datamining)、精密消息传递、购物和银行业务等应用了Web agent技术,计算科学团体将可以在重要的Web agent技术之上建立新一代的精密计算环境.几年前在我们早期的hypercube研究中,开发了一个与一系列大规模并行计算问题相关的精密协作数据流优化算法,类似的这种方法可以很自然地应用到Web计算中.这里基本的Internet协议或更高层的基于agent的精密消息传递可以看成是与我们的"crystal router"算法相类似的,但我们还开发了集合数据流策略,用它来处理一些计算问题 - 如FFT和层次树或其他网络拓扑结构.我们现在正在着手于一个类似问题,将自适应的CFD和其他PDE问题映射到WebVM结构上.当在这种环境中不可能实现确定性同步时,智能终端节点或将自动地搜索它们的计算服务主机,而且整个计算网格将持续地适应不断变化的计算资源.Java的可移植能力使得在Java Web服务器的mesh结构中可以实现新颖的全球范围的分布式计算,各个独立的主机可以简单地将它们CPU时间片的一部分贡献出来,而协作和松散同步则由自适应的Webflow算法来处理.我们早期在Web上开发的130位RSA因数分解就是一个这样的例子.我们还可以想起很多这方面的问题,如计算科学非常关注的环境保护、气象预报、经济增长分析等 - 人们正在致力于此项研究以使"全球范围的计算模式"成为现实.
最近,针对这个问题我们在Syracuse大学举办了一个讨论会(http://www.npac.syr.edu/projects/javaforcse),它主要包括上两部分内容,那时我们认为Java在用户界面、包装、元级问题控制方面无疑是很吸引人的.这里我们考虑它作为一种科学和工程的程序设计语言可以起到的作用 - 替代目前的主要语言Fortran 77、Fortran 90和C++.
比起其他语言,Java语言最重要的优势在于它将被范围非常广的用户学习并且使用.Java已经被很多初级学校指定为程序设计教程,而且将来一定会吸引中等或高等学校来采用这门课程.Java是一种非常社会化的语言,因为人们可以很自然地得到其他人使用Java经验的Web页面,这对一门介绍性的课程来说是很有帮助的.很明显,Web是唯一的向孩子们介绍计算机的真正手段,它所使用的典型语言是Java、JavaScript和Perl.我们认为对于一个不懂Java语言的刚进入大学的新生来说,要想轻易地接受Fortran语言是比较难的.C++作为一个更复杂的系统构造语言取得了很大的进步,尽管它的应用很广泛,但作为仿真语言C++还有很多缺限,尤其是C++很难在串行和并行代码中都实现很高的性能,我们期望在Java中不会出现这些问题.
现在让我们来讨论一下性能问题,这对Java来说是很关键的.如在图3中所描述的那样,在一个多层次的科学程序设计环境中,在对可用性和性能进行折衷考虑的条件下,适度地选择纯粹的脚本化环境、applet环境和纯粹的编译型环境.在讨论会中,很难解释为什么本地的Java编译器 - 与当前可移植的JavaVM解释器或JIT(Just in Time)编译器是根本对立的,得不到与C或Fortran编译器相当的性能.一个主要的原因是Java语言中对例外事件的丰富支持导致编译器很难对其进行优化处理.当对性能要求很高时,用户书写代码应当尽量避免复杂的例外事件处理.
Java语言的一个重要特征是没有指针,很明显这可以更好地对串行和并行代码进行优化处理.乐观地看,我们说Java具有C++的面向对象和Fortran语言高性能的双重特征.
另外一个有趣的事情是所期望的Java解释器(使用just in time技术)和Java bytecode上的编译器(虚拟机)性能.我们发现PC JIT编译器处理后的代码执行速度与C编译器生成的代码相比可能要慢4-10倍(见图15和http://www.npac.syr.edu/users/gcf/edperf.html),共同的期望是对于可移植的applet程序来说,其性能与其他编译器所产生的代码相比差距不超过2倍.正如上面所说的那样,对编程方式作一些限制后,我们期望Java语言或VM编译器能达到与最好的Fortran和C编译器相抗衡的水平.我们还期望建立一组可下载的高性能"本征类(native class)"库,以提高不同领域用户建立的科学库的性能.
图3中的框架有一个有趣的省略 - 层次a)中的一个纯粹的解释型Java,它对教学来说非常有帮助,JavaScript是解释型的,我们可以将它看成是为文档处理(document handling)而设计的"小语言" -- 不是通常的类似于Java的解释环境.
最后讨论一下Java中的并行性,这里我们重新返回到部分IV中的四种并行性.
概括的讲,与C++和Fortran语言(尤其是作为大规模仿真和建模语言)相比,Java具有很明显的优势,而没有非常明显的缺限.很显然,我们不应当也不能将已有的所有代码改成Java程序,然而我们能用Java语言来构造包装程序及用户界面.随着编译器性能的不断提高,我们期望Java能越来越多地吸引用户编写新的应用程序,这样广大的计算工作者们才能在他们各种工作中采用这项日益壮大的Web技术.
[Fox:95a] Fox, Geoffrey C., Furmanski, Wojtek, Chen, Marina, Rebbi, Claudio, and Cowie, James H., ``WebWork: Integrated Programming Environment Tools for National and Grand Challenges,'' Syracuse University Technical Report SCCS-715, June, 1995.
[Fox:95d] Fox, Geoffrey C., and Furmanski, Wojtek, ``The Use of the National Information Infrastructure and High Performance Computers in Industry,'' in Proceedings of the Second International Conference on Massively Parallel Processing using Optical Interconnections, IEEE Computer Society Press, Los Alamitos, CA, 298-312. Syracuse University Technical Report SCCS-732, October 1995.
[Fox:95f] Fox, Geoffrey C., ``High Performance Distributed Computing,'' Syracuse University Technical Report SCCS-750, December 1995. To appear in Encyclopedia of Computer Science and Technology.
[Fox:96b] Fox, Geoffrey C., ``An Application Perspective on High-Performance Computing and Communications,'' Syracuse University Technical Report SCCS-757, April 1996.
[Fox:96a] Fox, Geoffrey C., ``A Tale of Two Applications on the NII,'' Syracuse University Technical Report SCCS-756. In the proceedings of the 1996 Sixth Annual IEEE Dual-Use Technologies and Applications Conference, June 1996.
[Fox:96c] Fox, Geoffrey C., and Wojtek, Furmanski, ``SNAP, Crackle, WebWindows!'', published as RCI Maagement White Paper Number 29, Syracuse University Technical Report SCCS-758, April 1996.
[Taubes:96] Taubes, Gary, ``Do-It-Yourself Supercomputers,'' Science, 274:5294, 1840, December 13, 1996.
Copyright 牋NPACT
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}