
High Performance Commodity Computing (HPcc)
Geoffrey C. Fox, Wojtek Furmanski, Tomasz Haupt
Northeast Parallel Architectures Center at Syracuse University
Commodity Technologies
The Web is not just a document access system supported by the somewhat limited HTTP protocol. Rather we it is the distributed object technology which can build general multi-tiered enterprise intranet and internet applications.
We believe that industry and the loosely organized worldwide collection of (freeware) programmers is developing a remarkable new software environment of unprecedented quality and functionality. We call this DcciS - Distributed commodity computing and information System. We believe that this can benefit HPCC in several ways and allow the development of both more powerful parallel programming environments and new distributed metacomputing systems.
There are many driving forces and many aspects to DcciS but we suggest that the three critical technology areas are the web, distributed objects and databases. These are being linked and we see them subsumed in the next generation of "object-web" technologies, which is illustrated by the recent Netscape and Microsoft version 4 browsers. Databases are older technologies but their linkage to the web and distributed objects, is transforming their use and making them more widely applicable.
In each commodity technology area, we have impressive and rapidly improving software artifacts. However equally and perhaps more importantly, we have a set of open interfaces enabling distributed modular software development. These interfaces are at both low and high levels and the latter generate a very powerful software environment in which large preexisting components can be quickly integrated into new applications. We suggest that HPCC applications can also benefit in the same way from this new level of productivity. Thus it is essential to build HPCC environments in a way that naturally inherent all the commodity capabilities. This is the goal of NPAC's HPcc (High Performance commodity computing) activity.
We note the growing power and capability of commodity computing and communication technologies largely driven by commercial distributed information systems. CORBA, Microsoft's COM, Javabeans, and less sophisticated web and networks approaches build such systems.These can all be abstracted to a three-tier model with largely independent clients connected to a distributed network of severs. These host various services including object and relational databases and of course parallel and sequential computing. High performance can be obtained by combining concurrency at the middle server tier with optimized parallel back end services. The resultant system combines the needed performance for large-scale HPCC applications with the rich functionality of commodity systems. Further the architecture with distinct interface, server and specialized service implementation layers, naturally allows advances in each area to be easily incorporated. We show that this approach can be applied to both metacomputing and to provide improved parallel programming environments. We give several examples; web-based user interfaces; the use of Java as a scientific computing language; integration of interpreted and compiled environments; visual component based programming; distributed simulation; and the role of databases, CORBA and collaborative systems. We suggest that establishment of a set of frameworks, which will be the necessary standard interfaces between the users and HPcc Services.
Three Tier High Performance Commodity Computing
Fig. 1: Industry 3-tier view of enterprise Computing
We start with a common modern industry view of commodity computing with the three tiers shown in fig 1. Here we have customizable client and middle tier systems accessing "traditional" back end services such as relational and object databases. A set of standard interfaces allows a rich set of custom applications to be built with appropriate client and middleware software. As indicated on figure, both these two layers can use web technology such as Java and Javabeans, distributed objects with CORBA and standard interfaces such as JDBC (Java Database Connectivity). There are of course no rigid solutions and one can get "traditional" client server solutions by collapsing two of the layers together. For instance with database access, one gets a two tier solution by either incorporating custom code into the "thick" client or in analogy to Oracle's PL/SQL, compile the customized database access code for better performance and incorporate the compiled code with the back end server. The latter like the general 3-tier solution, supports "thin" clients such as the currently popular network computer.
Although a distributed object approach is attractive, most network services today are provided in a more ad-hoc fashion. In particular today's web uses a "distributed service" architecture with HTTP middle tier servers invoking via the CGI mechanism, C and Perl programs linking to databases, simulations or other custom services. There is a trend toward the use of Java servers with the servlet mechanism for the services. This is certainly object based but does not necessarily implement the standards compiled by CORBA, COM or Javabeans. However, this illustrates an important evolution as the web absorbs object technology with the evolution:
HTTP --> Java Sockets ...........-->IIOP or RMI
(Low Level network standard) (High level network standard)
Perl CGI Script --> Java Program --> Javabean distributed object.
As an example consider the evolution of networked databases. Originally these were client-servers with a proprietary network access protocol. Web linked databases produced a three tier distributed service model with an HTTP server using a CGI program (running Perl for instance) to access the database at the backend. Today we can build databases as distributed objects with a middle tier Javabean using JDBC to access the backend database.
Today we see a mixture of distributed service and distributed object architectures. CORBA, COM, Javabean, HTTP Server + CGI, Java Server and Servlets, Databases with specialized network accesses, and other services co-exist in a heterogeneous environment with common themes but disparate implementations. We believe that there will be significant convergence as a more uniform architecture is in everyone's best interest. We also believe that the resultant architecture will be integrated with the web so that the latter will exhibit distributed object architecture. Most of our remarks are valid for all these approaches to a distributed set of services. Our ideas are however easiest to understand if one assumes an underlying architecture which is a CORBA or Javabean distributed object model integrated with the web.
We wish to use this service/object evolving 3-tier commodity architecture as the basis of our HPcc environment. We need to naturally incorporate (essentially) all services of the commodity web and to use its protocols and standards wherever possible. We insist on adopting the architecture of commodity distribution systems as complex HPCC problems require the rich range of services offered by the broader community systems. Perhaps we could "port" commodity services to a custom HPCC system but this would require continued upkeep with each new upgrade of the commodity service. By adopting the architecture of the commodity systems, we make it easier to track their rapid evolution and expect it will give high functionality systems, which will naturally track the evolving Web/distributed object worlds. This requires us to enhance certain services to get higher performance and to incorporate new capabilities such as high-end visualization (e.g. CAVE's) or massively parallel systems where needed. This is the essential research challenge for HPcc for we must not only enhance performance where needed but do it in a way that is preserved as we evolve the basic commodity systems. We certainly have not demonstrated this clearly but we have a simple strategy that we will elaborate later. Thus we exploit the three-tier structure and keep HPCC enhancements in the third tier, which is inevitability, the home of specialized services in the object-web architecture. This strategy isolates HPCC issues from the control of interface issues in the middle layer. If successful we will build an HPcc environment that offers the evolving functionality of commodity systems without significant re-engineering as advances in hardware and software lead to new and better commodity products.

Figure 2:HPcc Illustrated with Interoperating Hybrid Server Architecture
HPcc, shown in fig 2, extends fig 1 in two natural ways. Firstly the middle tier is promoted to a distributed network of servers; in the "purest" model these are CORBA/COM/Javabean object-web servers but obviously any protocol compatible server is possible. This middle tier extension provides networked servers for many different capabilities (increasing functionality) but also multiple servers to increase performance on an given service. The use of high functionality but modest performance communication protocols and interfaces at the middle tier limits the performance levels that can be reached in this fashion. However this first step gives a scaling, if necessary parallel (in terms of multiple servers) HPcc implementation which includes all commodity services such as databases, object services, transaction processing and collaboratories. The next step is only applied to those services with insufficient performance. Naively we "just" replace an existing back end (third tier) implementation of a commodity service by its natural HPCC version. Sequential or socket based messaging distributed simulations are replaced by MPI (or equivalent) implementations on low latency high bandwidth dedicated parallel machines. These could be specialized architectures or "just" clusters of workstations. Note that with the right high performance software and network connectivity, workstations can be used at tier three just as the popular "LAN" consolidation" use of parallel machines like the IBM SP-2, corresponds to using these in the middle tier. Further a "middle tier" compute or database server could of course deliver its services using the same or different machine from the server. These caveats illustrate that like many concepts there will be times when the clean architecture of fig 2 will become confused. In particular the physical realization does not necessarily reflect the logical architecture shown in fig 2.
.
Supercomputing '97 Demonstrations
I. SciVis Scientific Visualization
Byeongseob Ki, Scott Klasky
 SciVis is a Java-based collaborative data analysis system. The main
purpose of this software package is to provide researchers with a customizable
data analysis system to aid research. One of the key features of our system
is that filters are user definable. We created API's for users to design
their own filters.
SciVis is a Java-based collaborative data analysis system. The main
purpose of this software package is to provide researchers with a customizable
data analysis system to aid research. One of the key features of our system
is that filters are user definable. We created API's for users to design
their own filters.
We use a client-server model for data visualization. The users can send
the data to the server anywhere the socket is supported so that our system
can be used as a front end to other applications, which produces the data
set. If one application produces a data set, it can write the output data
set to a socket, which is connected to our server. Our system will then
allow the user to analyze and visualize the data. Our system is flexible
and very usable and thus we feel that researchers can benefit from using
our software.
II. Integrated Environment for HPF Compiler and Interpreter
Erol Akarsu, Tomasz Haupt
![]() The integration of compiled and interpreted HPF gives us an opportunity
to design a powerful application development environment targeted to high
performance parallel and distributed systems. The environment includes a
debugger, data visualization and data analysis packages, and an HPF interpreter.
A capability to alternate between compiled and interpreted modes provides
the means for interaction with the code at real-time, while preserving an
acceptable performance. Thanks to interpreted interfaces, typical of Web
technologies, w can use our system as a software integration tool.
The integration of compiled and interpreted HPF gives us an opportunity
to design a powerful application development environment targeted to high
performance parallel and distributed systems. The environment includes a
debugger, data visualization and data analysis packages, and an HPF interpreter.
A capability to alternate between compiled and interpreted modes provides
the means for interaction with the code at real-time, while preserving an
acceptable performance. Thanks to interpreted interfaces, typical of Web
technologies, w can use our system as a software integration tool.
The fundamental feature of our system is that the user can interrupt execution of the compiled code at any point and get an interactive access to the data. For visualizations, the execution is resumed as soon as the data transfer is completed. For debugging, the interrupted code pauses and the server waits for the user's commands. In addition to a basic set of debugger commands such as displaying values of variables, the user can also set their values. In particular, values of distributed arrays can be modified by issuing HPF commands which are compiled in the fly and dynamically linked with the running application. In this sense, our system can be think of as an HPF interpreter. For more complex data transformations, the user can dynamically link precompiled functions (shared object in UNIX) for runtime data analysis or fast prototyping. Last but not least, the interactive access to the data allows for a runtime steering, and thanks to the interpreted interfaces, for dynamical software integration.
The control over the execution of an application and an interactive access
to the data is achieved by a source level instrumentation of the code. The
instrumentation is performed by a dedicated preprocessor without any user's
assistance. In addition, the original code is augmented with an HPF server,
implemented in C as an HPF LOCAL extrinsic procedure. Since the instrumentation
is made on the source code level (HPF, in the current version of our system)
it is platform independent, and can be done on a dedicated workstation that
hosts the preprocessor. The input source file (from the user), as well the
resulting instrumented one (to the target multiprocessor system) can be
sent using the standard HTTP protocol.

The architecture of the system is shown in Figure 1.The heart of it is the HPF server, which controls the execution of the HPF application and processes requests from clients. The server is a part of an instrumented HPF code. Consequently, it is active only after the HPF application is launched. The client that allows the user to connect with the server is implemented as a Java Applet.
The interaction between the running application and user's commands is
based on dynamical linking of UNIX shared objects with the application.
This way any precompiled stand alone or library routine with a conforming
interface can be called interactively or at the selected action points.
In order to execute a new code entered in a form of a HPF source it must
be first converted to a shared object. To this end we use the HPFfe to generate
a subroutine from a single HPF statement or a block of statements, and then
compile it using an HPF compiler, as shown in the figure below:

Since any "interpreted" code is in fact compiled, the efficiency
of the resulting code is
as good as that of the application itself. Nevertheless, time needed for
creation of the
shared object is prohibitively long to attempt to run the complete applications,
statement
after the statement, in the interpreted mode. On the other hand, the capability
of data
manipulations and visualization at any time during the execution of the
application without
recompiling and rerunning the whole application proves to be very time effective.
WebFlow (CORBA like) Integration
Wojtek Furmanski, Dimple Bhatia, Hasan Ozdemir, Girish Premchandran;
Tomasz Haupt
We are monitoring the emergent Web technologies pertaining to the domain
of world wide
scalable distributed computing and we are designing and prototyping a visual
graph based dataflow environment,WebFlow, using the mesh of Java Web Servers
as a control and coordination middleware, WebVM.
 Our goal is to provide a coarser grain packaging model and the associated
user-friendly authoring framework for distributed applications on the Web.
We believe that we should build on top of the established standards such
as HTTP, HTML and Java, and hence we adopt Java Web server as a base runtime
and coordination node of any distributed Web system. Dataflow model, already
proven effective by previous systems such as AVS, Khoros, etc. Hence and
others, seems to be a natural coordination framework to extend the current
node model in which HTTP/MIME data flows between Web client and server towards
multi-server systems. Hence, we propose a runtime environment given by a
mesh of Web Java servers to coordinate distributed computation represented
as a set of channel-connected coarse grain Java modules. Modules are thin
veneer Java interfaces so that any chunk of Java can be easily modularized
and connected to other modules via suitable communication ports, acting
as terminals of point-to-point dataflow channels. Modules run asynchronously,
are mobile i.e. can be instantiated on any WebVM server, and communicate
by exchanging Java objects along their dataflow channels.
Our goal is to provide a coarser grain packaging model and the associated
user-friendly authoring framework for distributed applications on the Web.
We believe that we should build on top of the established standards such
as HTTP, HTML and Java, and hence we adopt Java Web server as a base runtime
and coordination node of any distributed Web system. Dataflow model, already
proven effective by previous systems such as AVS, Khoros, etc. Hence and
others, seems to be a natural coordination framework to extend the current
node model in which HTTP/MIME data flows between Web client and server towards
multi-server systems. Hence, we propose a runtime environment given by a
mesh of Web Java servers to coordinate distributed computation represented
as a set of channel-connected coarse grain Java modules. Modules are thin
veneer Java interfaces so that any chunk of Java can be easily modularized
and connected to other modules via suitable communication ports, acting
as terminals of point-to-point dataflow channels. Modules run asynchronously,
are mobile i.e. can be instantiated on any WebVM server, and communicate
by exchanging Java objects along their dataflow channels.
The WebFlow prototype
Our prototype WebVM is given by a mesh of Java Servers, running servlets that manage and coordinate distributed computation. Atomic encapsulation units of WebVM computation are called modules and they communicate by sending objects along channels attached to module. Unlike management servlets which are usually persistent and application independent, modules are more transient and can be dynamically created, connected, scheduled, run, relocated and destroyed by servlets. WebFlow is a particular programming paradigm implemented over WebVM and given by a dataflow programming model (other models under experimentation include data parallel, collaboratory, and televirtual paradigms). WebFlow application is given by a computational graph, visually edited by end-users using Java applets. Modules are written by module developers, people who have only limited knowledge of the system on which the modules will run. They not need concern themselves with issues such as:
The WebFlow system hides these management and coordination functions
from the developers, allowing them to concentrate on the modules being developed.
WebFlow management is currently implemented in terms of the following three
servlets: Session Manager, Module Manager, and Connection Manager. These
servlets are URL addressable and can offer dynamic information about their
services and current state. Each of them can also communicate with each
other through sockets.

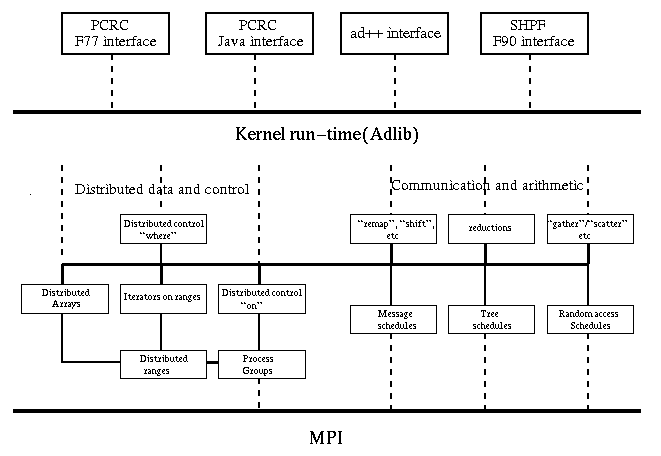
PCRC Backend for HPF and HPJava
Bryan Carpenter, Xiaoming Li, Xinying Li, Yuhong Wen, Guangsong Zhang
Sponsored by ARPA, PCRC(Parallel Compiler Runtime consortium) is an effort to establish a common base for parallel compiler development. This common base is a runtime library, which is supposed to be available to the compilers. It is linked to the generated "node program". Our philosophy in PCRC is to build a relatively high level runtime library. We believe this approach will greatly facilitate compiler construction and deliver comparable or better performance for typical applications. An important aspect of PCRC runtime is that it is supposed to be a common base for different compilers. this demands a flexible design and an implementation that adopts sound engineering practices.

Compiler Front End
The compiler construction framework, called the frontEnd system, is an extensible software package for constructing programming language processing tools. The system analyzes the input source language and converts it to a uniform intermediate representation (IR) which can later be manipulated by a set of functions provided in a C++ class library.
HPF Compilation

The HPF compiler is embedded in a compiler construction framework showed
in the figure. Currently it has already handled different HPF language features,
including data mapping directives, expressions and assignment, program execution
control,
input/output and procedures.
NPAC Run-time Library
The kernel of NPAC library is a C++ class library. It is most directly descended from the run-time library of an earlier research implementation of HPF, with influences from the Fortran 90D run-time and the CHAOS/PARTI libraries. The kernel is currently implemented on top of MPI. The library design is solidly object-oriented, but efficiency is maintained as primary goal. Inlining is used extensively, and dynamic memory allocation, unnecessary copying, tune procedure calls, virtual functions and other forms of indirection are avoided unless they have clear organizational or efficiency advantages.
Bridge to WebTop Computing

Glossary
CORBA (Common Object Request Broker Architecture)
An approach to distributed object development cross platform cross language by a broad industry group the OMG. CORBA specifies basic services (such as naming, trading, persistence) the protocol IIOP used by communicating ORBS, and is developing higher level facilities - object architectures for specialized domains such as banking.
COM (Common Object Model)
Microsoft's windows object model, which is being extended to distributed systems and multi-tiered architectures. ActiveX controls are an important class of COM objects.
HPcc (High Performance commodity computing)
NPAC project to develop a commodity computing based high performance computing software environment. Note that we have dropped "communications" referred to in the classic HPCC acronym. This is not because it is unimportant but rather because a commodity approach to high performance networking is already being adopted. Here we focus on high level services such as programming, data access and visualization that we abstract to the rather wishy-washy "computing" in the HPcc acronym.
HPCC (High Performance Computing and Communication)
Originally a formal federal initiative but even after this ended in 1996, this term is used to describe the field devoted to solving large-scale problems with powerful computers and networks.
HTTP (Hyper Text Transport Mechanism)
A stateless transport protocol allowing control information and data to be transmitted between web clients and servers.
IIOP (Internet Inter Orb Protocol)
A stateful protocol allowing CORBA ORB's to communicate with each other, both the request for a desired service and the returned result.
JDBC (Java Data Base Connection)
A set of interfaces (Java methods and constants) in the Java 1.1 enterprise framework, defining a uniform access to relational databases. JDBC calls from a client or server Java program link to a particular "driver" that converts these universal database access calls (establish a connection, SQL query, etc.) to particular syntax needed to access essentially any significant database.
Javabean
Part of the Java 1.1 enhancements defining design frameworks (particular naming conventions) and inter Javabean communication mechanisms for Java components with standard (Bean box) or customized visual interfaces (property editors). Enterprise Javabeans are Javabeans enhanced for server side operation with capabilities such as multi user support.
OMG (Object Management Group)
OMG is the organization of over 700 companies that is developing CORBA through a process of call for proposals and development of consensus standards.
ORB (Object Request Broker)
Used in both clients and services in CORBA to enable the remote access to objects. ORB's are available from many vendors and communicate with IIOP.
RMI (Remote Method Invocation)
A somewhat controversial part of Java 1.1 in the enterprise framework which specifies the remote access to Java objects with a generalization of the UNIX RPC (Remote Procedure Call).
Web Client
Originally web clients displayed HTML and related pages but now they support Java Applets that can be programmed to give web clients the necessary capabilities to support general enterprise computing. The support of signed applets in recent browsers has removed crude security restrictions, which handicapped previous use of applets.
Web Servers
Originally Web Servers supported HTTP requests for information - basically HTML pages but included the invocation of general server side programs using the very simple but arcane CGI - Common Gateway Interface. A new generation of Java servers have enhanced capabilities including server side Java program enhancements (Servlets) and support of stateful permanent communication channels.