Note the statement of work includes both the base budget and the activity to be funded through options. The latter includes the complex applications (data intensive and distributed) as well as PETASIM support for them.
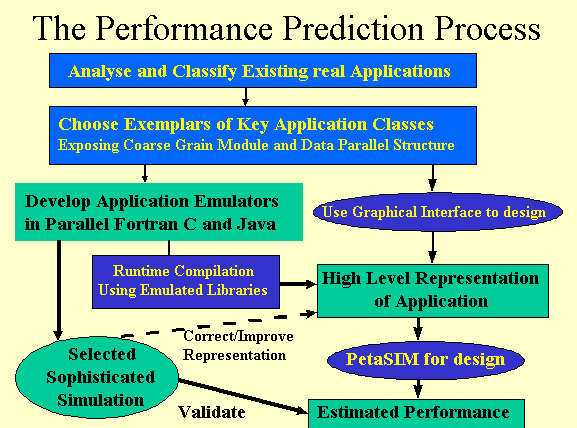
Our work is in the context of the enclosed figure and falls into two major areas
Application Analysis and Abstraction
Here the goal is to develop and use general techniques for abstracting applications in a way that their essential performance characteristics are captured. These techniques will be applied to a carefully chosen set of real applications which span the key characteristics we expect for compute and data intensive applications over the next ten years. Although not aimed at Petaflop computer systems, our approach will build in lessons from the several Petaflop studies and can be expected to be valuable in designing both relatively conventional and novel architecture hardware. We do not intend a detailed simulation but do include all aspects of a program's behavior including I/O and network needs as well as raw computation. For this reason, we expect our approach to be valuable in designing the system software as well as hardware on high performance computers.
Syracuse will use its experience and contacts with the application work in NSF, DoD DoE and Industry communities to select key applications and their performance critical characteristics. This will lead to a set of particular applications which Syracuse will tackle in the two methods proposed in this project. Firstly we will generate Application Emulators in both parallel Fortran and Java and secondly develop them in the HLAL (High Level Abstraction Language) to be developed by the Rutgers/UCSB team.
We will also take the parts of the PCRC (Parallel Compiler Runtime
Consortium) library and map them into HLAL so to compilation can
generate directly HLAL from the Application Emulators.
Milestones:
Year 1:
Work with Collaborators to establish procedure for application selection and abstraction
Clarify and validate process with two simple examples including Black Hole Grand Challenge (non adaptive) and PCRC examples. These will have both HLAL and emulator versions developed
Establish connections with appropriate DoD (modernization) and NSF teams as suggested by our application classification. Continue interactions with application community interested in Petaflop architectures.
Extend Web based Virtual Programming Laboratory (VPL) with its Java front-end to PABLO performance system as a framework for application evaluation in both emulation and abstraction mode.
Year 2:
Integrate PCRC emulated libraries into Syracuse and other HPF compilers
Develop other applications including one from DoD, one from NSF PACI as well as financial modeling (industry), adaptive Black Hole Grand Challenge and work with Maryland/John Hopkins on collaborative healthcare application. The latter will use our TANGOsim Java collaboration system
Year 3:
Complete and Extend Application work with DoD NSF and John Hopkins
Ongoing evaluation of HLAL for functionality and ease of use.
This part of activity is based on our PETASIM system designed from experience gotten from studies of requirements of architectures presented at the major Petaflop meetings in 1996. The groups there used error-prone "back of the envelope" computations to study the performance of very simple applications (the so-called PetaKernels) on the new architectures. Errors of a factor of a million were made even by experienced scientists. Thus we designed a high level simulator to support the design of both hardware and software of modern high performance systems. It includes the simple well known analytic methods (many introduced by Fox 15 years ago as a so-called tcomm-tcalc analysis) but supports the Critical is the support of the complex memory hierarchies in the hardware and the diversity of applications. As part of this proposal we will adapt PETASIM to use the Rutgers HLAL and adapt/certify it on the applications chosen by the group. We will of course look at target machines of interest today as well as those suggested for ten years out.
Year 1:
Adapt PETASIM to HLAL and test on simple applications such as PetaKernels
Develop Java front end to PETASIM which will including our existing Pablo Java visualization applets.
Use "real" applications (such as Black Hole code) on PETSIM
Year 2:
Extend PETASIM to adaptive and data intensive applications
Test PETASIM on rich set of target machines including current (NSF and ASCI centers) as Petaflop architectures.
Year 3:
Extend PETASIM to distributed (Web) applications.
Continue ongoing use and evaluation.
Abstract
We will provide a reasonably accurate simulator for the performance
of problems from a general field of synchronous or loosely synchronous
structure on hierarchical shared and distributed memory computers.
We will include the point designs and applications studied in
the 1996 PAWS and PetaSoft workshops. We will not implement the
general case initially and later describe a set of simplifications
which can be relaxed in further versions if the initial system
is successful.
Overall Approach We will provide a general framework in which the user specifies the computer and problem architectures. The computer and problem can be expressed at any level of granularity - typically the problem is divided into objects which fit into the lowest interesting level of the memory hierarchy which is exposed in the user specified computer model. The computer and problem can both be hierarchical but initially we will focus on "flat" problems with arbitrary hierarchy for the computer. Both distributed and shared memory architectures and their mixture can be modeled.
Synchronous, loosely synchronous ( and the typically easier embarrassingly parallel ) problems will be supported. These are divided into phases - in each phase all objects are computed - with synchronization (typically also communication or redistribution ) at the end of each phase. Problems must have a fixed distribution into objects during each phase but can be redistributed at phase boundaries. The basic idea here is to use a sophisticated spreadsheet. Each cell of the spreadsheet represents a memory unit of the computer. For each phase, the user provides a strategy which moves the problem objects through the cells. The simulator accumulates communication and computer costs. Some special cells (e.g. those corresponding to the lowest memory hierarchy exposed) have CPU's attached to them and objects are computed when they land on a CPU cell. The phase terminates when all objects have been computed. Note that a "real computer" would determine this cell stepping strategy from the software supplied by the user and the action of the hardware. The simulator will supply a helpful framework but the user is responsible for understanding both the problem and the machine well enough to supply this cell stepping. One could expect to gradually automate parts of this in future activities. Note that in general, there are many more memory cell than particle objects. Usually the number of particle objects is greater than or equal to the number of cells with CPU's. Note the special case of a distributed memory machine with no memory hierarchy at each node. Then the number of cells, CPU's and particle objects are all equal. The cell stepping strategy involves one step in which all objects are computed. We will provide both a C and Java version of the simulator. The visualization of the results will use a set of Java Applets based on extensions of NPAC's current Java interface to Illinois's Pablo performance monitoring system.
Note that you can use any level of fidelity that you like but the user is responsible for estimating the compute cost when an object arrives at a CPU cell. This could involve an estimate of the effect of lower memory levels in the hierarchy which are not modeled directly. Problems and computers are both specified as a set of units labeled by a hierarchy level and a position (labeled by a one or multidimensional index) within a given level. The user must specify the linkage between these units with an appropriate associated function (or simply a weight) which calculates the communication performance between units in the computer model and needed message traffic for the problem model. The initial system will only support "flat" problems but general hierarchies for computers will be implemented. A further initial simplification will be that only homogeneous systems will be supported. It is believed that these simplifications can be straightforwardly removed in future versions.