Geoffrey Fox May 1,97
This document consists of material from the proposal (before size cuts were made) of direct relevance to PetaSIM combined with new material which is gradually elaborating a detailed PetaSIM specification. This specification essentially also starts to define HLAM as one cannot really separate the two. PetaSIM's claim to fame is that it simulates a description of a problem that is intermediate between "back of the envelope" and direct simulation of the real Fortran/C/Java code. HLAM is responsible for representing this intermediate specification level.
Section 2 is background from the proposal.
Section 3 is initial plan.
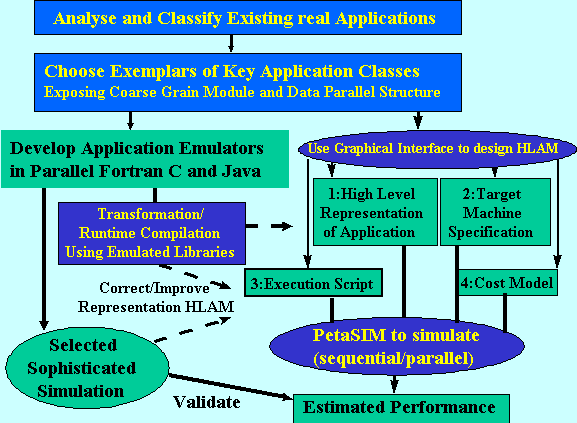
This project is built around the performance prediction process
sketched in figure 1. The distinctive feature of our approach
is the use of machine and problem abstractions which although
less accurate than detailed complete representations, can be expected
to be more robust and further quite appropriate for the rapid
prototyping needed in the design of new machines, software and
algorithms. The heart of this performance prediction process are
two technologies - HLAM and PETASIM. These originate in the work
of the Rutgers/UCSB and Syracuse respectively but will be generalized
and fully integrated in this project. Further the HLAM/PETASIM
performance prediction system will interface to the application
emulators developed at Maryland using a combination of static
and runtime compilation techniques from all 3 groups. We refer
generically by HLAM to the four key inputs to PETASIM which describe
respectively the target machine (sec. 2.1), application (sec.
2.2), script specifying execution of application on machine (sec
2.3) and finally the cost model for basic communication, I/O and
computation primitives (sec. 2.4). As indicated, we discuss these
in the following four sections with the major section 2.3 describing
PETASIM with basic concept and implementation.
2.1 Target Machine Specification
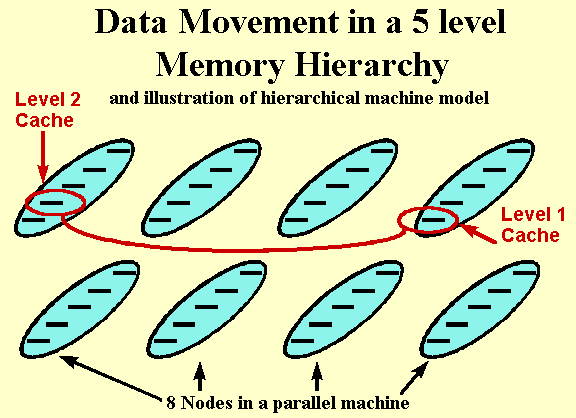
There is a close relationship between performance modeling and the description of applications needed to allow either the user or compiler to properly map an application onto parallel systems. In general, reliable performance estimates need the same level of machine description as is needed to specify parallel programs in a way that allows good performance to be obtained when executing on the target machine. This machine description can either be explicit (as in MPI) or implicit as in an automatic parallelizing compiler which must essentially use such a machine description to define its internal optimizations of data placement and movement. Thus to be effective in estimating performance on a target machine, PETASIM must input an architectural description at the same level needed by parallel programming environments. The PetaSoft meetings identified the need for such architectural descriptions as essential in defining future extensions to parallel languages whether they be message or data parallel. MPI and HPF view parallel systems implicitly treat parallel systems as a three level memory hierarchy (local processor memory, remote memory and disk). As shown in figure 3, this is inadequate for some current and nearly all future expected high performance systems. Thus an important product of our project will be such a machine description which we will target at both today's (distributed shared memory) machines and the future designs typified by those examined in the PetaFlop process. The latter looked at "extrapolated conventional", Superconducting and Processor in Memory designs and our proposed specification is appropriate for these three cases.[FoxFurm 97] As explained above, this machine description will be very helpful in developing future parallel programming environments. We expect experience from our project to drive new developments in this field as we will determine which features of problem and machine are performance critical as we will use (reliable) models of expected complex memory hierarchies and not to wait for new hardware to be available.
Our proposed machine description in HLAM will allow specification of number of memory hierarchies, their sizing and data movement (latency and bandwidth) times. A typical example is shown in figure 3 taken from the PetaSoft discussion. These primitive machine operations will include collective as well primitive operations and cover both data movement and data replication (as in messaging and cache operation).
2.2: HLAM -- Hierarchical Application Modeling Framework
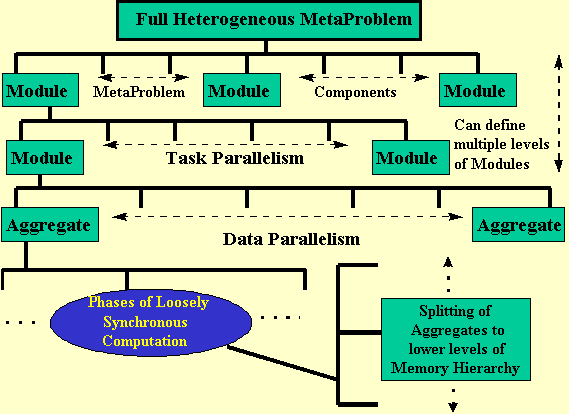
Critical to our project will be a high level application modeling framework HLAM which is based on existing Rutgers/UCSB research but will be substantially generalized in this project as well as being integrated into a powerful simulation system. We believe there are several advantages in using simplified application abstractions rather than the full application. Firstly it is expensive to simulate full applications - especially large problems on future high performance (PetaFlop) systems. Secondly use of well chosen abstraction can lead to better understanding of the key features that determine performance. Finally abstractions can be generic and easily represent a broader class of applications than any one full application. This is not to say detailed simulations of full applications are not of inestimable value - rather we argue that our high-level abstractions have intrinsic complementary value. HLAM is illustrated in Figure 2 which shows that we first hierarchically divide an application (sometimes called in this context as a metaproblem) into modules. A sophisticated parallel application may be composed of several coupled parallel programs. Parallel programs can themselves be viewed as being composed of a collection of parallel modules. These modules may be explicitly defined by a user, or the modules may be generated by a semi-automatic process such as an HPF compiler. Modules that represent distinct programs may execute on separate nodes of a networked metacomputer. An individual module may be sequential or data parallel. We might use a data parallel module to represent a multi-threaded task that runs on a SMP node. HLAM will include a wide range of applications including data-intensive applications (including I/O from remote sites) and migratory Web programs. Some key features of our proposed high level abstraction HLAM are:
We will provide a convenient Java user interface which will allow the user to specify all four inputs to HLAM (machine, problem, execution, cost). Further as explained later, various techniques such as static and runtime compilation and detailed simulation will "automate" parts of this specification process.
One initial focus will be to develop a hierarchical behavior representation
for MPI-based SPMD parallel code. Previous research on representing
the parallelism from sequential code will benefit our project.
For example, the control and data dependence can be modeled through
program dependence graphs.{PDG} Hierarchical task graphs{Polychronopoulos}
were developed for modeling functional parallelism and loop parallelism.
Such a graphical structure has also been studied in the SISAL
project for functional parallelism{SISAL}. For modeling MPI-based
parallel programs, we will abstract not only hierarchical control
structures, but also important multiprocessing events such as
message sending, receiving, reduction, global communication and
barriers. Thus the graphical structure of a MPI program will consist
of basic computation components, communication and I/O primitives,
and multi-level control over these components. A basic computation
is a code segment without involving I/O and multiprocessor communication.
Basic computation blocks are modeled in a coarse-grain level if
possible so that the performance impact of multi-level memory
hierarchy can be studied in a block level. Computation primitives
from software building blocks such BLAS and LAPACK math subroutines
can be used to abstract basic computation.
2.3.1: Introduction and Motivation
Central to this proposal is a performance simulator PETASIM which is aimed at supporting the (conceptual and detailed) design phases of parallel algorithms, systems software and hardware architecture. Originally this was designed as a result of the two week long workshops - PAWS and PetaSoft - aimed at understanding hardware and software architectures ten years from now when Petaflop (1015) scale computing can be expected. It was clear from these meetings that the community needed better aids for performance estimation as the 8 groups (and 8 different machine designs) present found it difficult to compare designs and in particular differed by a factor of million (PAWS report) in estimating performance of even a set of extremely simple algorithms - the PetaKernels -- on their new designs. The most sophisticated PetaKernel was a regular finite difference problem solved by simple Jacobi iteration which is of course well understood. These workshops emphasized the need for tools to allow one to describe complex memory hierarchies (present in all future and most current machine designs) and the mapping of problems onto them in a way that allows reliable (if high level) performance estimates in the initial design and rapid prototyping stages.
PETASIM is aimed at a middle ground - half way between detailed instruction level machine simulation and simple "back of the envelope" performance estimates. It takes care of the complexity - memory hierarchy, latencies, adaptivity and multiple program components which make even high level performance estimates hard. It uses a crucial simplification - dealing with data in the natural blocks (called aggregates in HLAM) suggested by memory systems - which both speeds up the performance simulation and in many cases will lead to greater insight as to the essential issues governing performance. We motivate and illustrate the design of PETASIM by the well known formulae for parallel performance of simple regular applications on nodes without significant memory hierarchy. Then (chapter 3 of PCW) one finds,
Speed Up = Number of Nodes/(1 + Overhead)
where the Overhead is proportional to (Grain Size)-g (tcomm / tcalc )
where in this case natural data block size is the Grain Size or number of data points in each node. The power g measures edge over area effects and is 1/d for a system of geometric dimension d. (tcomm / tcalc ) represents a ratio of communication to compute performance of the hardware. Such a formula shows the importance of identifying natural data block and how such high level analysis allows one to understand the relation of performance to memory sizing, I/O and compute capabilities of the hardware. PETASIM generalizes this "back of the envelope" estimate to more complex problems and machines. It also includes not just primitive messaging performance (node to node as used in above estimate) but also collective (such as multicast) mechanisms which are present in most applications but ignored in many simple analyses. Note that the simple performance estimate above is valid (with straightforward generalizations) on machines with the simple two level distributed memory hierarchy - namely memory is either on or off processor - which is essentially model built into the current generation of parallel programming systems as typified by HPF or MPI. As we described in section 2.1, it is essential to generalize this machine model whether we want to provide input to either parallel programming tools or to performance estimation systems. Thus we believe our experience with HLAM and PETASIM will be very valuable in helping designing the new generation of parallel programming environments needed for the increasing complex high performance systems coming online.
Fortunately we have good evidence that we can generalize this naïve analysis to more complex problems and machines for indeed the Rutgers/UCSB group has studied granularity issues {cluster,dsc} to identify the natural data block sizes and computation clusters based on computatation/communication ratios in more general hierarchical memories. They have developed preliminary performance prediction and optimization tools (PYRROS {PYRROS}, D-PYRROS {jjiao},RAPID {RAPID}) based on task graphs in which the impact of single-processor memory hierarchy is addressed in the intra-task level and the impact of inter-processor communication delay is identified in the inter-task level. These techniques have been shown effective for a number of adaptive and static applications {Iter-2,ship,Fernandez,SparseLU} and it will be naturally integrated into PETASIM as this Rutgers/UCSB technology is the basis of HLAM described in section 2.2.
As well as a machine description, PETASIM requires a problem description where we will use the HLAM described in sec 2.2 above. Note also that application emulators also use the same "aggregate" description of applications needed by PETASIM and these will be used as input. It is not clear yet if we will convert these directly to the HLAM or allow a separate API for this style of program description.
2.3.2: Operation of PETASIM
As described above PETASIM defines a general framework in which the user specifies the computer and problem architectures and the primitive costs of I/O, communication and computation. The computer and problem can in principle be expressed at any level of granularity - typically the problem is divided into aggregates which fit into the lowest interesting level of the memory hierarchy which is exposed in the user specified computer model. Note the user is responsible for deciding on the "lowest interesting level" and the same problem/machine mapping can be studied at different levels depending on what part of the memory is exposed for user(PETASIM) control and which (lower) parts are assumed under automatic (cache) machine control. The computer and problem can both be hierarchical and PETASIM will support both numeric and data intensive applications. Further both distributed and shared memory architectures and their mixture can be modeled.
We assume the HLAM model shown in figure 2 where we view an application as a metaproblem which is first divided into modules which are task parallel. Each module is either sequential or data parallel and further divided into aggregates defined by the memory structure of the target machine.
Synchronous, loosely synchronous ( and the typically easier embarrassingly parallel ) data parallel modules will be supported. As shown in figure 2, these are divided into phases - in each phase all aggregates are computed - with synchronization (typically also communication or redistribution ) at the end of each phase. Modules must have a fixed distribution into aggregates during each phase but can be redistributed at phase boundaries. Aggregates are the smallest units into which we divide problem and would typically be a block of grid points or particles depending on the problem. The basic idea in PETASIM is to use a sophisticated spreadsheet. Each cell of the spreadsheet represents a memory unit of the computer and they are generated from the hierarchical machine description described in sec 2.1. For each phase of the module simulation, the user provides a strategy -- called the execution script in figure 1 -- which moves the module aggregates through the cells. The simulator accumulates the corresponding communication and computer costs. Some special cells (e.g. those corresponding to the lowest memory hierarchy exposed) have CPU's attached to them and aggregates are computed when they land on a CPU cell. The phase terminates when all aggregates have been computed. Note that a "real computer" would determine this cell stepping strategy from the software supplied by the user and the action of the hardware. The simulator will supply a helpful framework but the user is responsible for understanding both the problem and the machine well enough to supply this cell stepping execution script. One could expect to gradually automate parts of this in future activities. Note that in general, there are many more memory cells than aggregate objects. Usually the number of module aggregates is greater than or equal to the number of cells with CPU's. Note the special case of a distributed memory machine with no memory hierarchy at each node. Then the number of cells, CPU's and module aggregates are all equal and the cell stepping strategy involves one step in which all objects are computed. In this case, PETASIM will reproduce results like the simple "back of the envelope" results quoted above.
We will provide both a C and Java version of the simulator whereas the user interface will be developed as a Java Applet. The visualization of the results will use a set of Java Applets based on extensions of NPAC's current Java interface to Illinois's Pablo performance monitoring system.[Dincer 97]
Note that you can use any level of fidelity that you like but the user is responsible for estimating communication costs and the compute cost when an aggregate arrives at a CPU cell. These would involve an estimate of the effect of lower memory levels in the hierarchy which are not modeled directly. As described above and illustrated in figures 2 and 3, modules and computers are both specified as a set of units labeled by a hierarchy level and a position (labeled by a one or multidimensional index) within a given level. The user must specify the linkage between these units with an appropriate associated function (or simply a weight) which calculates the communication performance between units in the computer model and needed message traffic for the problem model. Section 2.4 gives more details on the estimation of performance cost functions of the different components needed by PETASIM. The initial system will support "flat" problems but general hierarchies for problems and computers is essential and will be implemented in the second year of the project.
2.3.3: Parallel Execution of PETASIM
Typically PETASIM can be executed on a sequential machine as it
is aimed at relatively crude estimation. However if for instance
an accurate modeling of cache, requires a small aggregate size
(and correspondingly large number of aggregates), the performance
estimate may become very expensive computationally. Very adaptive
problems could lead to a similar situation. In this case, we may
need to use parallel simulation and so the operation of PETASIM
needs to be parallelized. PETASIM involves a combination of both
data parallel and event driven simulations. The latter, we know
is quite hard {Maisie, GIT} and we expect that it will be sufficient
to parallelize just the simulation of data parallel modules. Here
we can draw on the extensive experience of all the collaborating
institutions including that in dynamic irregular parallel computation
techniques which will be needed when estimating th e performance
of applications with these characteristics.
So such edge communication will be treated as a "zero size"
memory block which has communication cost associated with it.
The performance of system can be specified by
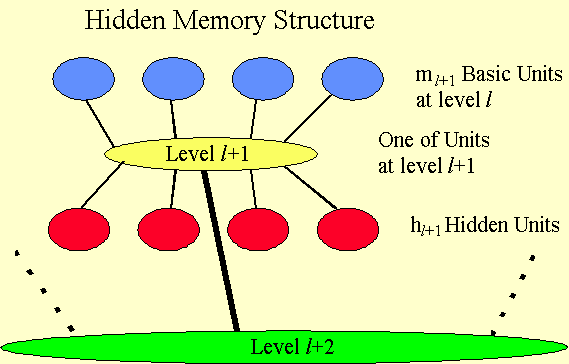
Fig 4: Illustration of Hidden Memory Structure
Memory movement can be direct or constrained to proceed through the hierarchy one level at a time. In latter case data can be replicated and saved on intermediate levels
We need here some options to control purging and saving of data
as it moves through the hierarchy. Possibilities include:
All computation is supposed to be in block-block form with both
A given type of block is called a data family and are labeled by a b ….
Each family is broken into units (with in simplest case number of units equal to number of CPU's) with Fa units in family a with each unit of size Ga.
A typical command is
References:
[PAWS report] "The Petaflops Systems Workshops", Proceedings of the 1996 Petaflops Architecture Workshop (PAWS), April 21-25,1996 and Proceedings of the 1996 Petaflops System Software Summer Study (PetaSoft), June 17-21, 1996, edited by Michael J. MacDonald (Performance Issues are described in Chapter 7).
[PCW] "Parallel Computing Works!", Geoffrey C. Fox, Roy D. Williams, and Paul C. Messina, Morgan Kaufmann, 1994.
[Dincer 97] "Using Java in the Virtual Programming Laboratory: A web-Based Parallel Programming Environment", Kivanc Dincer and Geoffrey Fox, to be published in special issue of Concurrency: Practice and Experience on Java for Science and Engineering Computation.
[FoxFurm 97] "Computing on the Web -- New Approaches to Parallel Processing -- Petaop and Exaop Performance in the Year 2007", Geoffrey Fox and Wojtek Furmanski, submitted to IEEE Internet Computing, http://www.npac.syr.edu/users/gcf/petastuff/petaweb/
[SimOS] M. Rosenblum, S. Herrod, E. Witchel, A. Gupta, "Complete
Computer System Simulation: The SimOS Approach", IEEE Parallel
and Distributed Technology: Sytems and Applications, 3(4), Winter
1995, pp 34-43.
[Proteus] E. Brewer, A. Colbrook, C. Dellarocas, W. Weihl, "Proteus:
A High-Performance Parallel Architecture Simulator", Performance
Evaluation Review, 20(1) Jun 1992, pp 247-8.
[Trojan] D. Park, R. Saavedra, "Trojan: A High-Performance
Simulator for Shared Memory Architectures", Proceedings of
the 29th Annual Simulation Symposium, April 1996, pp 44-53.
[Mint] J. Veenstra, R. Fowler, "MINT: A Front-end for Efficient
Simulation of Shared-Memory Multiprocessors", Proceedings
of International Workshop on Modelling, Analysis and Simulation
of Computer and Telecommunication Systems. Feb 1994, pp 201-7.
[Howsim] M. Uysal, A. Acharya, R. Bennett, J. Saltz, "A Customizable
Simulator for Workstation Networks", To appear in the International
Parallel Processing Symposium, April 1997.