


Next: About this document
Concurrency: Practice and Experience
Published Abstracts for 1996
Exploiting Application Parallelism in Knowledge-based
Systems: An Experimental Method
J. W. H. Daniel and M. R. Moulding
A method is presented which aims to enhance the runtime performance of
real-time production systems by utilizing natural concurrency in the
application knowledge base. This exploiting application parallelism (EAP)
method includes an automated analysis of the knowledge base and the use of
this analysis information to partition and execute rules on a novel parallel
production system (PPS) architecture. Prototype analysis tools and a PPS
simulator have been developed for the Inference ART environment in order to
apply the method to a Naval data-fusion problem. The results of this
experimental investigation revealed that an average maximum of 12.06
rule-firings/cycle was possible but, due to serial bottlenecks inherent in
the data-fusion problem, up to only 2.14 rule-firings/cycle was achieved
overall. Limitations of the EAP method are discussed within the context of
the experimental results and an enhanced method is investigated.
Short Code: [Daniel:96a]
Reference: Vol. 8, No. 1, pp. 1-18 (C257)
Native and Generic Parallel Programming Environments
on a Transputer and a PowerPC Platform
A. G. Hoekstra, P. M. A. Sloot, F. van der Linden, M.
van Muiswinkel, J. J. J. Vesseur, and L. O. Hertzberger
Genericity of parallel programming environments, enabling
development of portable parallel programs, is expected to result in
performance penalties. Furthermore, programmability and tool support
of programming environments are important issues if a choice between
programming environments has to be made. In this paper we propose a
methodology to compare native and generic parallel programming
environments, taking into account such competing issues as portability
and performance. As a case study, this paper compares the
Iserver-Occam, Parix, Express, and PVM parallel programming
environments on a 512-node Parsytec GCel. Furthermore, we apply our
methodology to compare Parix and PVM on a new architecture, a 32-node
Parsytec PowerXplorer, which is based on the PowerPC chip. In our
approach we start with a representative application and isolate the
basic (environment)-dependent building blocks. These basic building
blocks, which depend on floating-point performance and communication
capabilities of the environments, are analyzed independently. We have
measured point-to-point communication times, global communication times
and floating-point performance. All information is combined into a
time complexity analysis, allowing the comparison of the environments
on different degrees of functionality. Together with demands for
portability of the code and development time (i.e., programmability),
an overall judgment of the environments is given.
Short Code: [Hoekstra:96a]
Reference: Vol. 8, No. 1, pp. 19--46 (C241)
Benchmarking the Computation and Communication
Performance of CM-5
Kivanc Dincer, Zeki Bozkus, Sanjay Ranka, and Geoffrey Fox
Thinking Machines' CM-5 machine is a distributed-memory,
message-passing computer. In this paper we devise a performance
benchmark for the base and vector units and the data communication
networks of the CM-5 machine. We model the communication
characteristics such as communication latency and bandwidths of
point-to-point and global communication primitives. We show, on a
simple Gaussian elimination code, that an accurate static performance
estimation of parallel algorithms is possible by using those basic
machine properties connected with computation, vectorization,
communication, and synchronization. Furthermore, we describe the
embedding of meshes or hypercubes on the CM-5 fat-tree topology and
illustrate the performance results of their basic communication
primitives.
Short Code: [Dincer:96a]
Reference: Vol. 8, No. 1, pp. 47--69 (C156)
Building a Global Clock for Observing Computations in Distributed
Memory Parallel Computers
Jean-Marc Jézéquel and Claude Jard
A common time reference (i.e., a global clock) is needed for observing
the behavior of a distributed algorithm on a distributed computing
system. This paper presents a pragmatic algorithm to build a global
time on any distributed system, which is optimal for homogeneous
distributed memory parallel computers (DMPC). In order to observe and
sort concurrent events in common DMPCs, we need a global clock with a
resolution finer than the message transfer time variance, which is
better than what deterministic and fault-tolerant algorithms can obtain.
Thus a statistical method is chosen as a building block to derive an
original algorithm valid for any topology. Its main originality over
related approaches is to cope with the problem of clock granularity in
computing frequency offsets between local clocks to achieve a
resolution comparable with the resolution of the physical clocks. This
algorithm is particularly well suited for debugging distributed
algorithms by means of trace recordings because after its acquisition
step, it does not induce message overhead: the perturbation induced on
the execution remains as small as possible. It has been implemented on
various DMPCs: Intel iPSC/2 hypercube and Paragon XP/S, Transputer-based
networks and Sun networks, so we can provide some data about its
behavior and performances on these DMPCs.
Short Code: [Jezequel:96a]
Reference: Vol. 8, No. 1, pp. 71--89 (C201)
Portable Parallelizing Fortran Compiler
A. Averbuch, R. Dekel, and E. Gabber
The Portable Parallelizing Fortran Compiler (PPFC) is an
additional component for the portable programming environment
developed in Tel-Aviv University for scientific code. This environment
supports portable and efficient programming of diverse MIMD
multiprocessors, both distributed- and shared-memory.
Till now this environment consisted of two tools: The Virtual
Machine for MultiProcessors (VMMP), and the Portable Parallelizing
Pascal Compiler (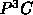 ). We added the PPFC which is an automatic
parallelizer compiler for the Fortran language. The compiler is fully
automatic (does not require additional declarations to assist
parallelization), which is characterized by loops operating on regular
data structures, and produces efficient and portable code for a variety
of multiprocessors from the same serial code.
). We added the PPFC which is an automatic
parallelizer compiler for the Fortran language. The compiler is fully
automatic (does not require additional declarations to assist
parallelization), which is characterized by loops operating on regular
data structures, and produces efficient and portable code for a variety
of multiprocessors from the same serial code.
The parallel implementation uses the VMMP which is a software package
that provides a coherent set of services for explicitly parallel
application programs running on diverse MIMD multiprocessors. VMMP is
intended to simplify parallel program writing and to promote portable
and efficient programming.
The PPFC parallelized 12 out of the 24 Livermore Loops. It
was also applied to parallelize all the 14 Fortran application
programs that were parallelized by the 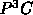 and achieved the same
speedups and efficiencies. In most examples, the PPFC
achieved high speedups and efficiencies on all target
multiprocessors.
and achieved the same
speedups and efficiencies. In most examples, the PPFC
achieved high speedups and efficiencies on all target
multiprocessors.
The PPFC emphasizes efficiency and code portability. Although
PPFC employs a relatively simple data flow analysis, it produces
efficient code for various widely used application programs.
Short Code: [Averbuch:96a]
Reference: Vol. 8, No. 2, pp. 91--123 (C214)
Reliable Parallel Software Construction using PARSE
Ian Gorton, Innes Jelly, Jonathan Gray, and Toong Shoon Chan
The PARSE design methodology provides a hierarchical, object-based
approach to the development of parallel software systems. A system
design is initially structured into a collection of concurrently
executing objects which communicate via message-passing. A graphical
notation known as the process graph is then used to capture the
structural and important dynamic properties of the system. Process
graph designs can then be semi-mechanically transformed into complete
Petri nets to give a detailed, executable and potentially verifiable
design specification. From a complete design, translation rules for
target programming languages are defined to enable the implementation
to proceed in a systematic manner. The paper describes the steps in
the PARSE methodology and the process graph notation, and illustrates
the application of PARSE from design specification to program code
using a network protocol example.
Short Code: [Gorton:96a]
Reference: Vol. 8, No. 2, pp. 125--146 (C234)
An Experiment to Measure the Usability of Parallel Programming
Systems
Duane Szafron and Jonathan Schaeffer
The growth of commercial and academic interest in parallel and
distributed computing during the past fifteen years has been
accompanied by a corresponding increase in the number of available
parallel programming systems (PPS). However, little work has been
done to evaluate their usability, or to develop criteria for such
evaluations. As a result, the usability of a typical PPS is based on
how easily a small set of trivially parallel algorithms can be
implemented by its authors.
This paper discusses the design and results of an experiment to
compare objectively the usability of two PPSs. Half of the students
in a graduate parallel and distributed computing course solved a
problem using the Enterprise PPS while the other half used a PVM-like
library of message-passing routines. The objective was to measure
usability. This experiment provided valuable feedback as to what
features of PPSs are useful and the benefits they provide during the
development of parallel programs. Although many usability experiments
have been conducted for sequential programming languages and
environments, they are rare in the parallel programming domain. Such
experiments are necessary to help narrow the gap between what parallel
programmers want, and what current PPSs provide.
Short Code: [Szafron:96a]
Reference: Vol. 8, No. 2, pp. 147--166 (C235)
Convergence of Concurrent Markov Chain Monte Carlo Algorithms
Maurits Malfait and Dirk Roose
We examine the parallel execution of a class of stochastic
algorithms called Markov Chain Monte-Carlo (MCMC) algorithms. We
focus on MCMC algorithms in the context of image processing, using
Markov Random Field models. Our parallelization approach is based on
several, concurrently running, instances of the same stochastic
algorithm that deal with the whole data set. First we show that the
speed-up of the parallel algorithm is limited because of the
statistical properties of the MCMC algorithm. We examine coupled MCMC
as a remedy for this problem. Secondly, we exploit the parallel
execution to monitor the convergence of the stochastic algorithms in
a statistically reliable manner. This new convergence measure for
MCMC algorithms performs well, and is an improvement on known
convergence measures. We also link our findings with recent work in
the statistical theory of MCMC.
Short Code: [Malfait:96a]
Reference: Vol. 8, No. 3, pp. 167--189 (C236)
Towards a Complete Framework for Parallel Implementation of
Logic Languages: The Data Parallel Implementation of SEL
Giancarlo Succi and Carl Uhrik
Although logic languages, due to their non-declarative nature, are
widely proclaimed to be conducive in theory to parallel
implementation, in fact there appears to be insufficient practical
evidence to stimulate further developments in this field. The paper
puts forward various complications which arise in assuming a solely
process parallel approach as a possible explanation for this
situation.
As an alternative, data parallelism is posited as an underutilized
forte of logic programming. This paper illustrates a data parallel
implementation of a particular language called SEL which is based on
sets. Thus, SEL (Set Equational Language) is introduced as an example
of logic language which lends itself to an efficient data parallel
implementation.
The strategy of this implementations assumes an abstract machine
called SAM (set-oriented abstract machine) which is based on the WAM
(Warren Abstract Machine). SAM serves as an intermediary between the
SEL language and the target machine for the implementation, the
Connection Machine. Finally, some preliminary benchmarks are
presented.
Short Code: [Succi:96a]
Reference: Vol. 8, No. 3, pp. 191--204 (C165)
Do-Loop-Surface: An Abstract Representation of Parallel Program
Performance
Oscar Naím, Tony Hey, and Ed Zaluska
Performance is a critical issue in current massively parallel
processors. However, delivery of adequate performance is not automatic
and performance evaluation tools are required in order to help the
programmer to understand the behavior of a parallel program.
In recent years, a wide variety of tools have been developed for this
purpose including tools for monitoring and evaluating performance and
visualization tools. However, these tools do not provide an abstract
representation of performance. Massively parallel processors can
generate a huge amount of performance data and sophisticated methods
for representing and displaying these data (e.g., visual and nural) are
required. Performance views are not scalable in general and do not
represent an abstraction of the performance data.
The Do-Loop-Surface display is proposed as an abstract representation
of the performance of a particular do-loop in a program. It has been
used to improve the performance of a Matrix Multiply parallel algorithm
as well as to understand the behavior of the following applications:
Matrix Transposition (TRANS1) and Fast Fourier Transform (FFT1) from
the Genesis Benchmarks, and the kernel of a fluid dynamics package
(FIRE). These experiments were performed on a CM-5, Meiko CS-1, and a
PARSYS Supernode. The examples demonstrate that the Do-Loop-Surface
display is a useful way to represent performance. It is implemented
using AVS (Application Visualization System), a standard data
visualization package.
Short Code: [Naim:96a]
Reference: Vol. 8, No. 3, pp. 205--234 (C246)
Dynamics simulation of Multibody Chains on a Transputer System
B. Pond and I. Sharf
This paper describes the implementation on a transputer system of a
novel parallel algorithm for dynamics simulation of a multibody chain.
The algorithm is formulated at a level of parallelism which is natural
for the problem but is essentially unavailable to other simulation
dynamics algorithms. The experimental results demonstrate that one can
improve efficiency of computation by exploiting this level of
parallelism. However, analysis of the performance shows that the
serial component of the resulting parallel algorithm grows to be a
large fraction of the total parallel execution time and therefore
limits the speedup that can be achieved with this approach.
Short Code: [Pond:96a]
Reference: Vol. 8, No. 3, pp. 235--249 (C230)
A Parallel Algorithm for the Integer Knapsack Problem
D. Morales, J. L. Roda, C. Rodriguez, F. Almeida, and F. Garcia
A sequential algorithm with complexity
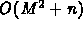 for the Integer Knapsack Problem is presented.
M is the capacity of the knapsack, and n the number
of objects. The algorithm admits an efficient parallelization on a
p-processor ring machine. The corresponding parallel algorithm
is
for the Integer Knapsack Problem is presented.
M is the capacity of the knapsack, and n the number
of objects. The algorithm admits an efficient parallelization on a
p-processor ring machine. The corresponding parallel algorithm
is 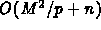 . The parallel algorithm
is compared with a version of the well-known Lee algorithm adapted to
the Integer Knapsack Problem. Computational results on both a local
area network and a transputer network are reported.
. The parallel algorithm
is compared with a version of the well-known Lee algorithm adapted to
the Integer Knapsack Problem. Computational results on both a local
area network and a transputer network are reported.
Short Code: [Morales:96a]
Reference: Vol. 8, No. 4, pp. 251--260 (C242)
On Estimating the Useful Work Distribution of Parallel
Programs under the P T:
A Static Performance Estimator
T:
A Static Performance Estimator
Thomas Fahringer
In order to improve a parallel program's performance it is critical to
evaluate how even the work contained in a program is distributed over
all processors dedicated to the computation. Traditional work
distribution analysis is commonly performed at the machine level. The
disadvantage of this method is that it cannot identify whether the
processors are performing useful or redundant (replicated) work. This
paper describes a novel method of statically estimating the
useful work distribution of distributed memory parallel programs at
the program level, which carefully distinguishes between useful and
redundant work.
The amount of work contained in a parallel program, which correlates
with the number of loop iterations to be executed by each processor,
is estimated by accurately modeling loop iteration spaces, array
access patterns and data distributions. A cost function defines the
useful work distribution of loops, procedures and the entire
program. Lower and upper bounds of the described parameter are
presented.
The computational complexity of the cost function is independent of
the program's problem size, statement execution and loop iteration
counts. As a consequence, estimating the work distribution based on
the described method is considerably faster than simulating or
actually compiling and executing the program.
Automatically estimating the useful work distribution is fully
implemented as part of the P T,
which is a static parameter based
performance prediction tool under the Vienna Fortran Compilation
System (VFCS). The Lawrence Livermore Loops are used as a test-case
to verify the approach.
T,
which is a static parameter based
performance prediction tool under the Vienna Fortran Compilation
System (VFCS). The Lawrence Livermore Loops are used as a test-case
to verify the approach.
Short Code: [Fahringer:96a]
Reference: Vol. 8, No. 4, pp. 261--282 (C265)
Fail-Safe Concurrency in the EcliPSe System
F. Knop, V. Rego, and V. Sunderam
Local or wide-area heterogeneous workstation clusters are relatively
cheap and highly effective, though inherently unstable operating
environments for long-running distributed computations. We found this
to be the case in early experiments with a prototype of the
EcliPSe system, a software toolkit for replicative applications on
heterogeneous workstation clusters. Hardware or network failures in
computations that executed for over a day were not uncommon. In this
work, a variety of features for the incorporation of failure resilience
in the EcliPSe system are described. Key characteristics of
this fault-tolerant system are ease of use, low state-saving cost,
system scalability, and good performance. We present results of some
experiments demonstrating low state-saving overheads and small system
recovery times, as a function of amount of state saved.
Short Code: [Knop:96a]
Reference: Vol. 8, No. 4, pp. 283--312 (C237)
MP: An Application Specific Concurrent Language
J. S. Reeve and M. C. Rogers
In this paper the authors present the definition and implementation of a
concurrent language MP (Message Passer), which is aimed at programming
embedded multi-microprocessor systems. The novel features of the
language include the ability to program and develop the entire
distributed system as a single unit, and the provision of simple
restricted concurrency constructs that make such systems modular and
deadlock free. MP programs are invariant with respect to the
characteristics of a particular target machine, for instance, the
number of processors, and their mutual connectivity. Programs written
in MP can be transformed to a restricted set of Communicating
Sequential Processes (CSP), in which particular specifications can be
shown to be satisfied.
The restricted model of concurrency does not prevent the language
being being to express all of the known course-grained parallel
programming paradigms. However, the structured nature of the code
makes the model particularly attractive in concurrent embedded
systems, where deadlock freedom and program correctness are prime
issues.
An MP program is a collection of objects which execute concurrently,
maintain their own local state and connect with other objects via
bound variables. Explicit communication between objects is totally
transparent to the application programmer.
A compiler for the language has been built and a multiprocessor
run-time environment has been established for any system with a C
compiler and the message-passing standard MPI library. Several
applications have been tested, ranging from a clocked digital circuit
simulation, to a simple event-driven process controller.
Short Code: [Reeve:96a]
Reference: Vol. 8, No. 4, pp. 313--333 (C245)
Performance Modelling of Three Parallel Sorting Algorithms on a
Pipelined Transputer Network
V. Lakshmi Narasimhan and J. Armstrong
The implementation of three parallel sorting algorithms, namely, binary
sort, odd-even transposition sort, and bitonic sort, on a network of
transputers is analyzed in this paper. The variation in the
performance of these algorithms as the number of processors and sort
size are changed is investigated. Experimental results show that when
up to eight transputers are used, connected as a linear pipeline
configuration, all three algorithms can achieve reasonable speedup
ratios. The bitonic sort, binary sort, and odd-even transposition sort
achieve speedup ratios of 5, 4.4 and 4, respectively when eight processors
are used to sort 100,000 integers. Analytical models are derived which
can be used to predict the performance of the three algorithms when a
linear pipeline configuration is used. The predicted performance of
the algorithms is compared with the experimental performance in order
to validate the model. When the models are used to predict the
performance using 16 transputers, it is found the speedup does not
significantly improve compared to the performance achieved with 8
transputers. This shows that interprocessor communication has a
significant effect on the algorithmic performance when a larger number
of processors are used. The conclusions reinforce the fact that the
binary and bitonic sorting algorithms are not well-suited to a linear
pipeline configuration and that they may perform better if a different
topology were used, for example a mesh or a cube connection scheme.
Further, the analytical technique used for performance modelling as
elaborated in the paper can be employed for other multiprocessor systems
as well.
Short Code: [Narasimhan:96a]
Reference: Vol. 8, No. 5, pp. 335--355 (C232)
Performance Analysis of Distributed Implementations of a Fractal
Image Compression Algorithm
D. J. Jackson, and G. S. Tinney
Fractal image compression provides an innovative approach to lossy
image encoding, with a potential for very high compression ratios.
Because of prohibitive compression times, however, the procedure has
proved feasible in only a limited range of commercial applications.
In the paper the authors demonstrate that, due to the independent nature of
fractal transform encoding of individual image segments, fractal image
compression performs well in a coarse-grain distributed processing
system. A sequential fractal compression algorithm is optimized and
parallelized to execute across distributed workstations and an SP2
parallel processor using the parallel virtual machine (PVM) software.
The system utilizes both static and dynamic load allocation to obtain
substantial compression time speedup over the original, sequential
encoding implementation. Considerations such as workload granularity
and compression time versus number of processors and RMS tolerance
values are also presented.
Short Code: [Jackson:96a]
Reference: Vol. 8, No. 5, pp. 357--380 (C253)
Parallel DSP Algorithms on TurboNet: An Experimental System with
Hybrid Message-Passing/Shared-Memory Architure
Xi Li, Sotirios G. Ziavras, and Constantine N. Manikopoulos
This paper presents several parallel DSP (Digital Signal Processing)
algorithms and their performance analysis, targeting a hybrid
message-passing and shared-memory architecture that has been built at
New Jersey Institute of Technology. The current version of our system
contains eight powerful TMS320C40 processors. The algorithms are
implemented on our system using message-passing only, shared-memory
only, and, if possible, a combination of both of these parallel
processing paradigms. Comparisons show that TurboNet's robust, hybrid
architecture results in significant performance gains because of the
flexibility it introduces.
Short Code: [Li:96b]
Reference: Vol. 8, No. 5, pp. 387--411 (C252)
The W-Network: A Low-cost Fault-tolerant Multistage
Interconnection Network for Fine-grain Multiprocessing
Kevin B. Theobald
Large-scale multiprocessors require an efficient interconnection
network to achieve good performance. This network, like the rest of
the system, should be fault-tolerant (able to continue
operating even when there are hardware failures). This paper presents
the W-Network, a low-cost fault-tolerant MIN which is
well-suited to a large multiprocessor running fine-grain parallel
programs. It tolerates all single faults without any increases in
latency or decreases in bandwidth following a fault, because it
behaves just like the fault-free network even when there is a single
fault. It requires only one extra port per chip, which makes it
practical for a VLSI implementation. In addition, extra ports can be
added for replacing faulty processors with spares.
Short Code: [Theobald:96a]
Reference: Vol. 8, No. 6, pp. 415--428 (HPCS-6)
High-performance Computing using a Reconfigurable Accelerator
Reiner W. Hartenstein, Jürgen Becker,e Rainer Kress, and Helmut
Reinig
This paper introduces the MoM-3 as a reconfigurable accelerator for
high performance computing at a moderate price. By using a new
machine paradigm to trigger the operations in the MoM-3, this
accelerator is especially suited to scientific algorithms, where the
hardware structure can be configured to match the structure of the
algorithm. The MoM-3 efficiently uses reconfigurable logic devices to
provide a fine-grain parallelism, and multiple address generators to
have the complete memory bandwidth free for data transfers (instead of
fetching address computing instructions). Speed-up factors up to 82,
compared to state-of-the-art workstations, are demonstrated by means
of an Ising spin system simulation example. Adding the MoM-3 as an
accelerator enables achievement of supercomputer performance from a
low-cost workstation.
Short Code: [Hartenstein:96a]
Reference: Vol. 8, No. 6, pp. 429--443 (HPCS-1)
Scanning Parameterized Polyhedron using Fourier-Motzkin
Elimination
Marc Le Fur
The paper presents two algorithms for computing a control structure
whose execution enumerates the integer vectors of a parameterized
polyhedron defined in a given context. Both algorithms reconsider the
successive projection method, based on Fourier-Motzkin pairwise
elimination, defined by Ancourt and Irigoin. The way redundant
constraints are removed in their algorithm is revisited in order to
improve the computation time for the enumeration code of higher order
polyhedrons as well as their execution time. The algorithms presented
here are at the root of the code generation in the HPF compiler
PANDORE developed at IRISA, France; a comparison of these algorithms
with the one defined by Ancourt and Irigoin is given in the class of
polyhedrons manipulated by the PANDORE compiler.
Short Code: [Fur:96a]
Reference: Vol. 8, No. 6, pp. 445--460 (HPCS-2)
A Family of Parallel QR Factorization Algorithms
Gerard G. L. Meyer, and Mike Pascale
Rapid computation of the QR factorization of a matrix is fundamental
to many scientific and engineering problems. The paper presents a
family of algorithms parameterized by the number of processors
available P, arithmetic grain aggregation parameters
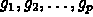 ,
and communication grain aggregation parameter h,
which compute the QR factorization of a matrix
,
and communication grain aggregation parameter h,
which compute the QR factorization of a matrix
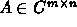 with minimal latency. The approach is particularly well suited for
dedicated distributed memory architectures such as linear arrays of
INMOS Transputers, Texas Instruments C40s or Analog Devices 21060s.
with minimal latency. The approach is particularly well suited for
dedicated distributed memory architectures such as linear arrays of
INMOS Transputers, Texas Instruments C40s or Analog Devices 21060s.
Short Code: [Meyer:96a]
Reference: Vol. 8, No. 6, pp. 461--473 (HPCS-5)
Visibility Analysis on a Massively Data-parallel Computer
Daniel Germain, Denis, Laurendeau, and Guy Vézina
Visibility analysis algorithms use digital elevation models (DEMs),
which represent terrain topography, to determine visibility at each
point on the terrain from a given location in space. This analysis
can be computationally very demanding, particularly when manipulating
high resolution DEMs accurately at interactive response rates.
Massively data-parallel computers offer high computing capabilities
and are very well-suited to handling and processing large regular
spatial data structures. In the paper, the authors present a new
scanline-based data-parallel algorithm for visibility analysis.
Results from an implementation onto a MasPar massively data-parallel
SIMD computer are also presented.
Short Code: [Germain:96a]
Reference: Vol. 8, No. 6, pp. 475--487 (HPCS-3)
Parallelizing a Powerful Monte Carlo Method for Electron Beam
Dose Calculations
W. Volken, P. Schwab, H. Neuenschwander, and P. G. Kropf
The Macro Monte Carlo (MMC) method has been developed to improve the
speed of traditional Monte Carlo calculations without significant loss
in accuracy. MMC runs about one order of magnitude faster for
clinically relevant irradiation situations. For routine use in a
clinical environment a further speedup is necessary. The MMC code was
therefore parallelized and implemented on PowerPC based Parsytec
PowerXplorer and GC Power Plus systems. The performance of the
parallel code is presented and compared to the sequential
implementations on standard hardware platforms. Almost linear speedup
is achieved for the parallel secitons of the code. Furthermore the
performance of the interprocessor communication based on a virtual
topology is demonstrated for the two different machine architectures.
Short Code: [Volken:96a]
Reference: Vol. 8, No. 6, pp. 489--498 (HPCS-4)
Effective Data Parallel Computation using the Psi Calculus
L. M. R. Mullin, and M. A. Jenkins
Large scale scientific computing necessitates finding a way to match
the high level understanding of how a problem can be solved with the
details of its computation in a processing environment organized as
networks of processors. Effective utilization of parallel
architectures can then be achieved by using formal methods to describe
both computations and computational organizations within these
networks. By returning to the mathematical treatment of a problem as
a high level numerical algorithm we can express it as an algorithmic
formalism that captures the inherent parallelism of the computation.
We then give a meta description of an architecture followed by the use
of transformational techniques to convert the high level description
into a program that utilizes the architecture effectively. The hope
is that one formalism can be used to describe both computations as
well as architectures and that a methodology for automatically
transforming computations can be developed. The formalism and
methodology presented in the paper is a first step toward the
ambitious goals described above. It uses a theory of arrays, the Psi
calculus, as the formalism, and two levels of conversions---one for
simplification and another for data mapping.
Short Code: [Mullin:96a]
Reference: Vol. 8, No. 7, pp. 499--515 (C218)
PB-BLAS: A Set of Parallel Block Basic Linear Algebra Subprograms
J. Choi, J. J. Dongarra, and D. W. Walker
We propose a new software package which would be very useful for
implementing dense linear algebra algorithms on block-partitioned
matrices. The routines are referred to as the block basic linear
algebra subprograms, and their use is restricted to computations in
which one or more of the matrices involved consists of a single row or
column of blocks, and in which no more than one of the matrices
consists of an unrestricted two-dimensional array of blocks. The
functionality of the block BLAS routines can also be provided by
Level 2 and 3 BLAS routines. However, for non-uniform memory access
machines the use of the block BLAS permit certain optimizations in
memory access to be taken advantage of. This is particularly true for
distributed memory machines, for which the block BLAS are referred to
as the parallel block basic linear algebra subprograms
(PB-BLAS). The PB-BLAS are the main focus of this paper, and for a
block-cyclic data distribution, a single row or column of blocks lies
in a single row or column of the processor template.
The PB-BLAS consist of calls to the sequential BLAS for local
computations, and calls to the BLACS for communication. The PB-BLAS
are the building blocks for implementing ScaLAPACK, the
distributed-memory version of LAPACK, and provide the same ease-of-use
and portability for ScaLAPACK that the BLAS provide for LAPACK.
The PB-BLAS consists of all Level 2 and 3 BLAS routines for dense
matrix omputations (not for banded matrix) and four auxiliary routines
for transposing and copying of a vector and/or a block vector. The
PB-BLAS are currently available for all numeric data types, i.e., single
and double precision, real and complex.
Short Code: [Choi:96a]
Reference: Vol. 8, No. 7, pp. 517--535 (C239)
SPEED: A Parallel Platform for Solving and Predicting the Performance
of PDEs on Distributed Systems
C.-C. Hui, M. Hamdi, and I. Ahmad
Distributed systems such as networks of workstations are becoming
an increasingly viable alternative to traditional supercomputer
systems for running complex scientific applications. A
large number of these applications require solving a set of partial
differential equations (PDEs). In this paper, we describe the
implementation and performance of SPEED (Scalable Partial Differential
Equation Environment on Distributed systems), a parallel platform which
provides an efficient solution for time-dependent PDEs. SPEED allows
the inclusion of a wide range of parameters and programming aids. PVM
is employed as the underlying message-passing system. The parallel
implementation has been performed using two algorithms. The first
algorithm is a two-phase scheme which uses conventional technique of
alternating phases of computation and communication. The second
algorithm employs a pre-computation technique that allows overlapping
of computation and communication. Both methods yield significant
speedups. The pre-computation technique reduces the communication time
between the workstations, but incurs additional overhead in buffer
management. Hence, if the saving in communication time is larger than
the overhead, the pre-computation technique outperforms the two-phase
algorithm. SPEED also provides a performance prediction methodology
that can accurately predict the performance of a given application on
the system before running the application. This methodology allows
the user to tune various parameters in order to identify system
bottlenecks and maximize the performance.
Short Code: [Hui:96a]
Reference: Vol. 8, No. 7, pp. 537--568 (C238)
Next: About this document
Theresa Canzian
Wed Sep 18 00:35:05 EDT 1996