In Fig. 1 we present a familiar plot showing the exponential increase in
supercomputer performance as a function of time.
A number of supercomputer manufacturers are aiming to deliver Teraflop
( ![]() floating point operations per second) performance by 1995.
The power of High Performance Computing (HPC) has been used in an
increasingly wide variety of applications in the physical
sciences. [1]
Fig. 2 shows the performance achieved as a function of time for a particular
application which requires supercomputer performance - the simulation of the
forces between quarks using quantum chromodynamics (QCD). [2, 3]
It is interesting to note that some of these supercomputers were built
primarily as dedicated machines for solving this particular problem.
floating point operations per second) performance by 1995.
The power of High Performance Computing (HPC) has been used in an
increasingly wide variety of applications in the physical
sciences. [1]
Fig. 2 shows the performance achieved as a function of time for a particular
application which requires supercomputer performance - the simulation of the
forces between quarks using quantum chromodynamics (QCD). [2, 3]
It is interesting to note that some of these supercomputers were built
primarily as dedicated machines for solving this particular problem.
Hardware trends imply that all computers, from PCs to supercomputers, will use some kind of parallel architecture by the end of the century. Until recently parallel computers were only marketed by small start-up companies (apart from Intel Supercomputer Systems Division), however recently Cray, Hewlett-Packard and Convex, IBM, and Digital have all announced massively parallel computing initiatives. Software for these systems is a major challenge, and could prevent or delay this hardware trend which suggests that parallelism will be a mainstream computer architecture. Reliable and efficient systems software, high level standardized parallel languages and compilers, parallel algorithms, and applications software all need to be available for the promise of parallel computing to be fully realized.
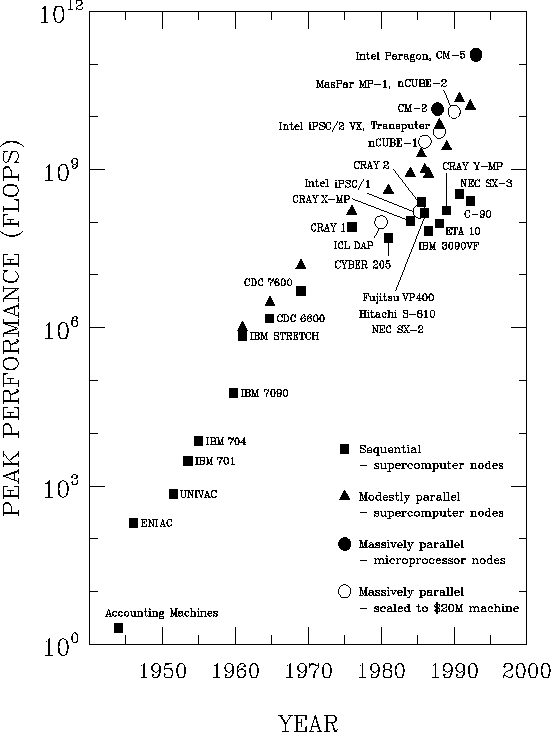
Figure 1: Peak performance in floating point operations per
second (flops) as a function of time for various supercomputers.
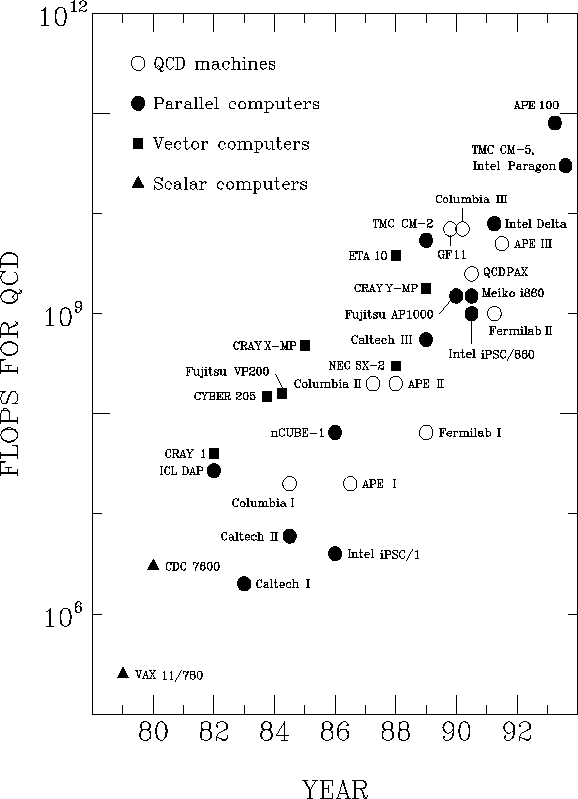
Figure 2:
Performance (in flops) of various supercomputers for QCD code,
as a function of the time when the code was first run. These are all
measured preformance figures, except for the APE 100, CM-5, and Paragon,
which are estimates.
Carver Mead of Caltech in an intriguing public lecture once surveyed the impact of a number of new technologies, and introduced the idea of ``headroom'' - how much better a new technology needs to be for it to replace an older, more entrenched technology. Once the new technology has enough headroom, there will be a fairly rapid crossover from the old technology, in a kind of phase transition. For parallel computing the headroom needs to be large (perhaps a factor of 10 to 100) to outweigh the substantial new software investment required. The headroom will be larger for commercial applications where codes are generally much larger, and have a longer lifetime, than codes for academic research. Machines such as the nCUBE and CM-2 were comparable in price/performance to conventional supercomputers, which was enough to show that ``parallel computing works'', [2, 4] but not enough to take over from conventional machines. It will be interesting to see whether the new batch of parallel computers, such as the CM-5, Intel Paragon, IBM SP-1, Maspar (DECmpp) MP-2, etc., have enough headroom.
Parallel computing implies not only different computer architectures, but different languages, new software, new libraries, and a different way of viewing problems. It will open up computation to new fields and new applications. To exploit this technology we need new educational initiatives in computer science and computational science. Education can act as the ``nucleus'' for the phase transition to the new technology of parallel computing, and accelerate the use of parallel computers in the real world.
Different problems will generally run most efficiently on different computer architectures, so a range of different architectures will be available for the some time to come, including vector supercomputers, SIMD and MIMD parallel computers, and networks of RISC workstations. The user would prefer not to have to deal with the details of the different hardware, software, languages and programming models for the different classes of machines. So the aim of supercomputer centers is transparent distributed computing, sometimes called ``metacomputing'' - to provide simple, transparent access to a group of machines of different architectures, connected by a high speed network to each other and the outside world, and to data storage and visualization facilities. Users should be presented with a single system image, so they do not need to deal with different systems software, languages, software tools and libraries on each different machine. They should also be able to run an application across different machines on the network.