The CollapsedRange subclass in Figure 3.1 stands for a range that is not distributed--all elements of the range are mapped to a single process. The code
Procs1 q = new Procs1(3) ;
on(p) {
Range x = new CollapsedRange(N) ;
Range y = new BlockRange(N, q.dim(0)) ;
float [[,]] a = new float [[x, y]] ;
...
}
creates an array in which the second dimension is distributed over
processes in q, with the first dimension collapsed. The
situation is visualized for the case N = 8
in Figure 3.11. This is our first example of a
one-dimensional process ``grid''.
Collapsed dimensions are often useful in algorithms where the pattern of access to elements is irregular in some but not all array dimensions. In the example above a process can access any element along the x dimension without communication, providing a fixed y location is mapped to the process concerned.
Unfortunately the language defined so far doesn't provide a good way to exploit this locality. If we want to assign the value in a[6,1] to a[2,1] we have to do something convoluted like
Procs1 q = new Procs1(3) ;
on(p) {
Range x = new CollapsedRange(N) ;
Range y = new BlockRange(N, q.dim(0)) ;
float [[,]] a = new float [[x, y]] ;
...
at(j = y [1]) {
float local ;
at(i = x [6])
local = a [i, j] ;
at(i = x [2])
a [i, j] = local ;
}
}
Because of the restriction that subscripts must be bound locations, the
value of a[6,1] must first be read to a local variable in an
at construct, then the value of the local variable must be copied to
a[2,1] in another. This is very tedious, and probably quite
inefficient.
To avoid this common problem, the HPJava model of distributed arrays is extended with the idea of sequential dimensions. If the type signature of a distributed array has an asterix in a particular dimension, that dimension will implicitly have a collapsed range, and the dimension can be subscripted with integer expressions just like a sequential array. The example becomes
Procs1 q = new Procs1(3) ;
on(p) {
Range y = new BlockRange(N, q.dim(0)) ;
float [[*,]] a = new float [[N, y]] ;
...
at(j = y [1])
a [6, j] = a [1, j] ;
}
The outer at construct is retained to deal with the distributed dimension,
but there is no need for bound locations in the sequential dimension.
The array constructor is passed integer extent expressions for
sequential dimensions. A CollapsedRange object will be created
for the array, but the programmer generally need not be aware of its
existence.
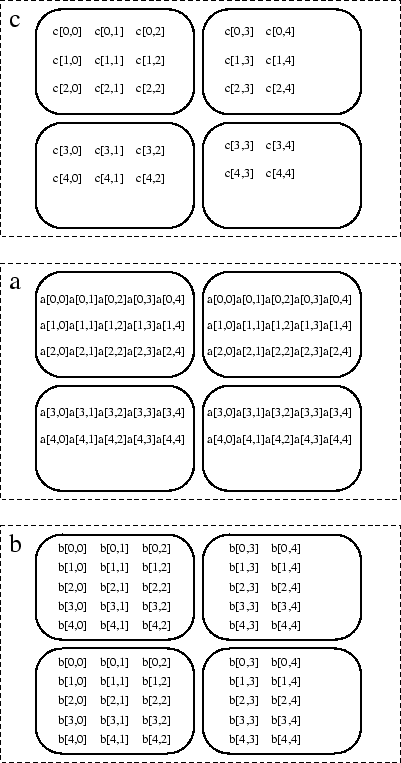
Figure 3.12 is an example of a parallel matrix multiplication in which the first input array, a, and result array, c, are distributed by rows--each processor is allocated a consecutive set of complete rows. The first dimension of these array is distributed, breaking up the columns, while the second dimension is collapsed, leaving individual rows intact. The second input array, b, is distributed by columns.
Array types with sequential dimensions are technically subtypes of corresponding array types without sequential dimension. All operations generally applicable to distributed arrays are also applicable to arrays with sequential dimensions. The asterisk in the type signature adds the option of subscripting the associated with integer espressions. It does not remove any option allowed for distributed arrays in general.
Allowing collapsed array dimensions means that an array can be distributed over a process grid having smaller rank than the array itself. Conversely it is also allowed to distribute an array over a process grid with larger rank.
Procs2 p = new Procs2(P, P) ;
on(p) {
Range x = new BlockRange(N, p.dim(0)) ;
float [[]] b = new float [[x]] ;
...
}
The array b has a dimension distributed over the first dimension
of p, but none distributed over the second. The interpretation
is that b is replicated over the second process dimension.
Independent copies of the whole array are created at each coordinate
where replication occurs. Usually programs maintain identical
values for the elements in each copy (although there is nothing in the
language definition itself to mandate this).
Replication and collapsing can both occur in a single array, for example
Procs2 p = new Procs2(P, P) ;
on(p) {
float [[*]] c = new float [[N]] ;
...
}
The range of c is sequential, and the array is replicated over
both dimensions of p. This makes it very similar to an ordinary
Java array declared in all processes by
float [] d = new float [N] ;
c and d are not identical, though. The array c
can be passed to library functions that expect distributed arrays
as arguments, whereas d cannot.
[Introduce the distribution group and the on clause for the distributed array constructors here?]
A simpler and potentially more efficient implementation of matrix multiplication can be given if the operand arrays have carefully chosen replicated/collapsed distributions. The program is given in Figure 3.13. As illustrated in Figure 3.14, the rows of a are replicated in the process dimension associated with y. Similarly the columns of b are replicated in the dimension associated with x. Hence all arguments for the inner scalar product are already in place for the computation--no communication is needed.
Clearly we would be very lucky to come across three arrays with such a special distribution format relative to one another ( alignment relation). There is an important function in the Adlib library called remap, which takes a pair of arrays as arguments. These must have the same shape and type, but they can have unrelated distribution formats. The elements of the source array are copied to the destination array. In particular, if the destination array has a replicated mapping, the values in the source array are broadcast appropriately. Figure 3.15 shows how we can use remap to adapt the program in Figure 3.13 to create a general purpose matrix multiplication routine. Besides the remap function, this example introduces the two inquiry functions grp and rng which are defined for any distributed array.


![\begin{figure}
\small\begin{verbatim}Procs2 p = new Procs2(P, P) ;
on(p) {
...
...i, k] * b [k, j] ;c [i, j] = sum ;
}
}\end{verbatim}\normalsize\end{figure}](img33.gif)
![\begin{figure}
\small\begin{verbatim}void matmul(float [[,]] c, float [[,]] a...
..., k] * tb [k, j] ;c [i, j] = sum ;
}
}\end{verbatim}\normalsize\end{figure}](img35.gif)