The best enterprises have both a compelling need pulling them forward and an innovative technological solution pushing them on. In high-performance computing, we have the need for increased computational power in many applications and the inevitable long-term solution is massive parallelism. In the short term, the relation between pull and push may seem unclear as novel algorithms and software are needed to support parallel computing. However, eventually parallelism will be present in all computers---including those in your children's video game, your personal computer or workstation, and the central supercomputer
The technological driving force is VLSI, or very large scale integration---the same technology that has created the personal computer and workstation market over the last decade. In 1980, the Intel 8086 used 50,000 transistors while in 1992 the latest Digital alpha RISC chip contains 1,680,000 transistors---a factor of 30 increase. The dramatic improvement in chip density comes together with an increase in clock speed and improved design so that the alpha delivers over a factor of 1,000 better performance on scientific problems than the 8086--8087 chip pair of the early 1980's.
The increasing density of transistors on a chip follows directly from
a decreasing feature size which is now 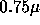 for the alpha.
Feature size will continue to decrease, and by the year 2000, chips
with 50,000,000 transistors are expected to be available. What can we
do with all these transistors?
for the alpha.
Feature size will continue to decrease, and by the year 2000, chips
with 50,000,000 transistors are expected to be available. What can we
do with all these transistors?
With around a million transistors on a chip, designers were able to
move full mainframe functionality to about 2 cm of a chip. This
enabled the personal computing and workstation revolutions. The next
factors of 10 increase in transistor density must go into some form of
parallelism by replicating several CPU's on a single chip.
of a chip. This
enabled the personal computing and workstation revolutions. The next
factors of 10 increase in transistor density must go into some form of
parallelism by replicating several CPU's on a single chip.
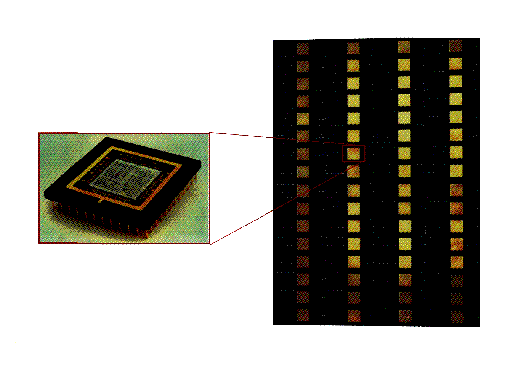
Figure 1: The nCUBE-2 Node and Its Integration into a Board. Up to 128
of these boards can be combined into a single supercomputer.
By the year 2000, parallelism is thus inevitable in all computers. Today, we see it in the larger machines, as we replicate many chips and many printed circuit boards to build systems as arrays of nodes; each unit of which is some variant of the microprocessor. This is illustrated in Figure 1, which shows a nCUBE parallel supercomputer with 64 identical nodes on each board---each node is a single chip CPU with additional memory chips. To be useful, these nodes must be linked in some way, and this is still a matter of much research and experimentation. Further, we can argue as to the most appropriate node to replicate; is it a ``small'' nodes as in the nCUBE of Figure 1, or is it more powerful ``fat'' nodes, such as those offered in CM-5 and Intel Touchstone where each node is a sophisticated multichip printed circuit board. However, these detailed issues should not obscure the basic point; parallelism allows one to build the world's fastest and most cost effective supercomputers. Figure 2 illustrates this as a function of time showing, already today, a factor of 10 advantage for parallel versus conventional supercomputers.
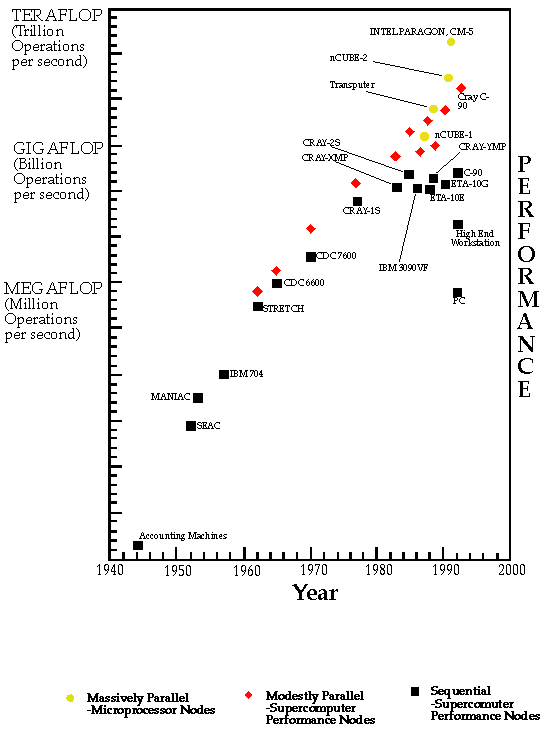
Figure 2: Performance of Parallel and Sequential Supercomputers
Parallelism may only be critical today for supercomputer vendors and users. By the year 2000, all supercomputers will have to address the hardware, algorithmic, and software issues implied by parallelism. The reward will be amazing performance and the opening up of new fields; the price will be a major rethinking and reimplementation of software, algorithms, and applications.