Advances in computing are driven by VLSI or very large scale integration, which technology has created the personal computer, workstation, and parallel computing markets over the last decade. In 1980, the Intel 8086 used 50,000 transistors while today's (1995) ``hot'' chips have some five million transistors------a factor of 100 increase. The dramatic improvement in chip density comes together with an increase in clock speed and improved design so that today's workstations and PCs (depending on the function) have a factor of 50---1,000 better performance than the early 8086 based PCs. This performance increase enables new applications. In particular, it allows real time multimedia decoding and display---this capability will be exploited in the next generation of video game controllers and set top boxes, and be key to implementing digital video delivery to the home.
The increasing density of transistors on a chip follows directly from a
decreasing feature size which is in 1995 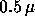 for the latest
Intel Pentium. Feature size will continue to decrease and by the year 2000,
chips with 50,000,000 transistors are expected to be available.
for the latest
Intel Pentium. Feature size will continue to decrease and by the year 2000,
chips with 50,000,000 transistors are expected to be available.
Communications advances have been driven by a set of physical transport technologies that can carry much larger volumes of data to a much wider range of places. Central is the use of optical fiber, which is now competitive in price with the staple twisted pair and coaxial cable used by the telephone and cable industries, respectively. The widespread deployment of optical fibers also builds on laser technology to generate the light, as well as the same VLSI advances that drive computing. The latter are critical to the high-performance digital switches needed to route signals between arbitrary source, and destination. Optics is not the only physical medium of importance---continuing and critical communications advances can be assumed for satellites and wireless used for linking to mobile (cellular) phones or more generally the future personal digital assistant (PDA).
One way of exploiting these technologies is seen in parallel
processing. VLSI is reducing the size of computers, and this directly
increases the performance because reduced size corresponds to
increased clock speed, which is approximately proportional to
 for feature size
for feature size  . Crudely, the cost of a
given number of transistors is proportional to silicon used or
. Crudely, the cost of a
given number of transistors is proportional to silicon used or
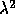 , and so the cost performance improves by
, and so the cost performance improves by
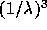 . This allows personal computers and workstations to
deliver today, for a few thousand dollars, the same performance that
required a supercomputer costing several million dollars just ten
years ago. However, we can exploit the technology advances in a
different way by increasing performance instead of (just) decreasing
cost. Here, as illustrated in Figure 1, we build
computers consisting of several of the basic VLSI building blocks.
Integrated parallel computers require high speed links between the
individual processors, called nodes. In Figure 1, these
links are etched on a printed circuit board, but in larger systems one
would also use cable or perhaps optical fiber to interconnect nodes.
As shown in Figure 2, parallel computers have become the
dominant supercomputer technology with current high and systems
capable of performance of up to 100 GigaFLOPS or
. This allows personal computers and workstations to
deliver today, for a few thousand dollars, the same performance that
required a supercomputer costing several million dollars just ten
years ago. However, we can exploit the technology advances in a
different way by increasing performance instead of (just) decreasing
cost. Here, as illustrated in Figure 1, we build
computers consisting of several of the basic VLSI building blocks.
Integrated parallel computers require high speed links between the
individual processors, called nodes. In Figure 1, these
links are etched on a printed circuit board, but in larger systems one
would also use cable or perhaps optical fiber to interconnect nodes.
As shown in Figure 2, parallel computers have become the
dominant supercomputer technology with current high and systems
capable of performance of up to 100 GigaFLOPS or 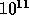 floating
point operations per second. One expects to routinely install parallel
machines capable of TeraFLOPS sustained performance by the year 2000.
floating
point operations per second. One expects to routinely install parallel
machines capable of TeraFLOPS sustained performance by the year 2000.
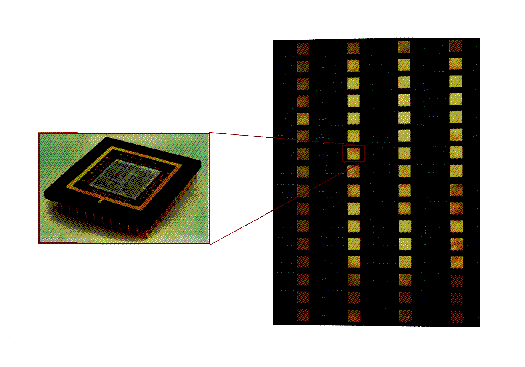
Figure 1: The nCUBE-2 Node and Its Integration into a Board. Up to 128
of these boards can be combined into a single supercomputer.
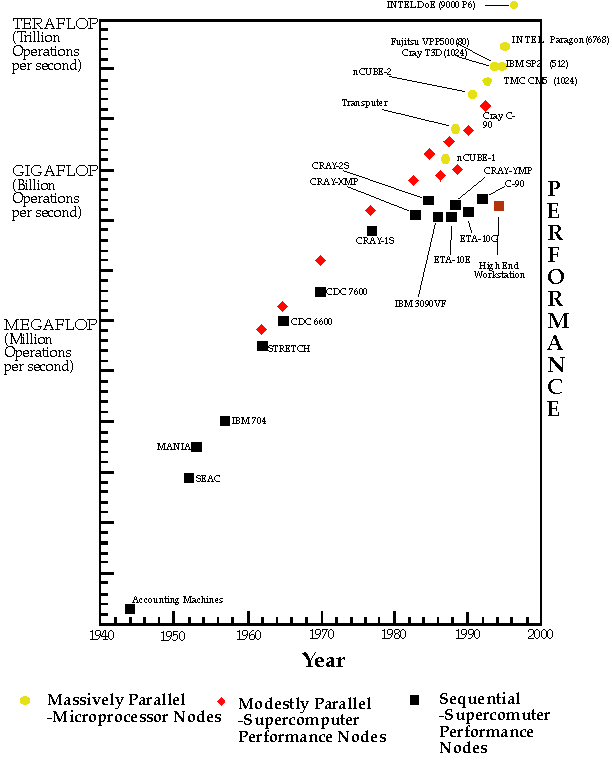
Figure 2: Performance of Parallel and Sequential Supercomputers
Often, one compares such highly coupled parallel machines with the
human brain, which achieves its remarkable capabilities by the linkage
of some  nodes---neurons in the case of the brain---to solve
individual complex problems, such as reasoning and pattern recognition.
These nodes have individually mediocre capabilities and slow cycle
time (about .001 seconds), but together they exhibit remarkable
capabilities. Parallel (silicon) computers use fewer faster
processors (current MPPs have at most a few thousand microprocessor
nodes), but the principle is the same.
nodes---neurons in the case of the brain---to solve
individual complex problems, such as reasoning and pattern recognition.
These nodes have individually mediocre capabilities and slow cycle
time (about .001 seconds), but together they exhibit remarkable
capabilities. Parallel (silicon) computers use fewer faster
processors (current MPPs have at most a few thousand microprocessor
nodes), but the principle is the same.
However, society exhibits another form of collective computing whereby it joins several brains together with perhaps 100,000 people linked in the design and production of a major new aircraft system. This collective computer is ``loosely-coupled''---the individual components (people) are often separated by large distances and with modest performance ``links'' (voice, memos, etc.).
Figure 3 shows HPDC at work in society with a bunch of mason's building a wall. This example is explained in detail in [Fox:88a], while Figure 4 shows the parallel neural computer that makes up each node of the HPDC system of Figure 3.

Figure 3: Concurrent Construction of a Wall using N=8 Bricklayers
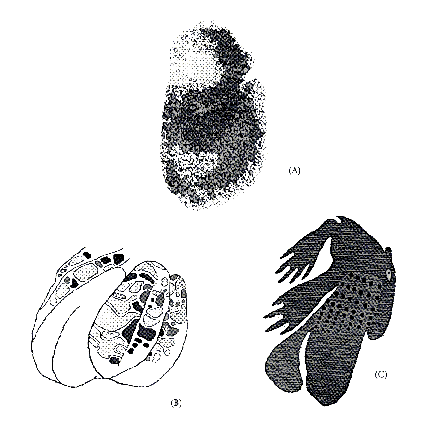
Figure 4: Three Parallel Computing Strategies Found in the Brain (of a
Rat). Each figure depicts brain activity corresponding to various
functions: (A) continuous map of a tactile inputs in somatosensory
cortex, (B) patchy map of tactile inputs to cerebellar cortex, and (C)
scattered mapping of olfactory cortex as represented by the
unstructured pattern of 2DG update in a single section of this cortex
[Nelson:90b].
We have the same two choices in the computer world. Parallel processing is gotten with a tightly coupled set of nodes as in Figure 1 or Figure 4. High Performance Distributed Computing, analogously to Figure 3, is gotten from a geographically distributed set of computers linked together with ``longer wires,'' but still coordinated (a software issue discussed later) to solve a ``single problem'' (see application discussion later). HPDC is also known as metacomputing, NOW's (Network of Workstations) and COW's (Clusters of Workstations), where each acronym has a slightly different focus in the broad HPDC area. Notice the network (the so called ``longer wires'' above) which links the individual nodes of an HPDC metacomputer can be of various forms---a few of the many choices are a local area network (LAN), such as ethernet or FDDI, a high-performance (supercomputer) interconnect, such as HIPPI or a wide area network WAN with ATM technology. The physical connectivity can be copper, optical fiber, and/or satellite. The geographic distribution can be a single room; the set of computers in the four NSF supercomputer centers linked by the vBNS; most grandiosely, the several hundred million computers linked by the Global Information Infrastructure (GII) in the year 2010.
HPDC is a very broad field---one can view client-server enterprise computing and parallel processing as special cases of it. As we describe later, it exploits and generalizes the software built for these other systems.
By definition, HPDC has no precise architecture or implementation at the hardware level---one can use whatever set of networks and computers is available to the problem at hand. Thus, in the remainder of the article, we focus first on applications and then some of the software models.
In the application arena, we go through three areas---aircraft design and manufacture, military command and control, and multimedia information systems. In each case, we contrast the role of parallel computing and HPDC---parallel computing is used for the application components that can be broken into modules (such as grid points for differential equation solvers or pixels for images), but these are linked closely in the algorithm used to manipulate them. Correspondingly, one needs the low latency and high internode communication bandwidth of parallel machines. HPDC is typically used for coarser grain decompositions (e.g., the different convolutions on a single image rather than the different blocks of pixels in an image). Correspondingly larger latencies, and lower bandwidths can be tolerated. HPDC and parallel computing often deal with similar issues of synchronization and parallel data decomposition, but with different tradeoffs and problem characteristics. Indeed, there is no sharp division between these two concepts, and clusters of workstations can be used for large scale parallel computing (as in CFD for engine simulation at Pratt and Whitney) while tightly coupled MPPs can be used to support multiple uncoupled users---a classic ``embarrassingly parallel'' HPDC application.