We originally proposed the bottom-up approach to HPCC (Figure 1) in WebWork---a collaboration between NPAC, Boston University, and Cooperating Systems. We successfully demonstrated the concept in the use of compute enhanced Web servers, which were used to complete the factoring (http://www.npac.syr.edu/factoring.html) of the largest number (RSA130) ever tackled. Other prototypes [Furmanski:96a] include a Web interface to HPF, and a Java user interface for building compute networks and mapping general distributed software systems (http://www.npac.syr.edu/projects/webbasedhpcc/index.html).
We expect that all HPCC environments can and should be built with Web technologies. This will allow use of WebTop tools to provide a much better software engineering environment. A nice example of this is a class project of Kemal Ispirli, which showed how Java client applets can animate (in real-time) performance data fed from the Web servers controlling the compute Web. This illustrates the advantages of the Web approach, which links MPP computing to the powerful Web information capabilities. The other key feature of the WebWork approach is the use of a pervasive technology base. No longer does a relatively small HPCC community have to develop the full software environment. We can build on the distributed computing capabilities of the Web and ``just'' add the special synchronization, latency hiding, and coordination needs of parallel processing.
There are two particularly clear initial Web based computing projects. The first, MetaWeb generalizes the RSA130 application to full support of cluster computing with a Web technology base. MetaWeb is the natural basis for Web implementation of a distributed computing environment, as envisaged in current NSF resolicitation of their supercomputer centers.
We found in the factoring problem that a major problem with our CGI enhanced Web servers that supported RSA130 sieving was that they did not provide the standard support which one expects from clustered computing packages (http://www.npac.syr.edu/techreports/hypertext/ sccs-748/index.html). This includes load balancing, fault tolerance, process management, automatic minimization of job impact on user workstations, security, accounting etc., which we will incorporate into MetaWeb. Note two immediate examples of advantages of Web based approach. We automatically support all platforms including Windows, as well as UNIX (fully heterogeneous systems), and we naturally can use ``real'' databases (such as DB2/Oracle) as these have already been excellently linked to Web, as shown in Figure 7. Here, we expect to directly store all system and job information in the relational (object if you use databases such as Illustra) database. Initally, we expect to use CGI scripts linking to existing Perl or C modules. Eventually, one would expect to migrate to a full Java based system. A further important feature of our proposed system is the natural linkage of performance visualization. We intend to build on idea of Ispirli to link Pablo (http://www-pablo.cs.uiuc.edu, [Reed:93b]) to the Web compute servers so that one can both store the performance trace in the associated databases, and display them either offline or in real time using Java applets.
The RAS130, and other MetaWeb applications, are natural for current Web technology because they do not require high bandwidth or low-latency communication. Eventually, we should build a full parallel environment using Web technology, but note first another programming paradigm that is also insensitive to deficiencies in the current internet, and high Web software overheads. Thus, our second initial Web computing system is WebFlow, which supports coarse grain software integration in the dataflow model. The concept of coarse grain data-flow based computations is well known with Khoros and AVS (Advanced Visualization System by AVS, Inc.) being popular. Using a convenient graphical interface, the user may interactively select precompiled modules and establish data dependences between them, and in this way define order of execution of the modules. Each module encapsulates a code to perform a specific task and communicates with the world via ports which accept or return data of one of a set of predefined types.
Many researchers have shown that AVS can be used as a general tool for supporting the dataflow computing models, which describes the top layers of many applications, such as Multidisciplinary Optimization or domain decomposition, where large grain software systems are linked in the complete application. Support for heterogenity and task parallelism in AVS allowed for a series of very successful experiments at NPAC [Cheng:93a;93c;95c] to integrate independent pieces of code running on different platforms, including MPPs into a single applications, including financial modelling and computational chemistry and electromagnetism. In fact, we believe that the dataflow paradigm can be used widely, and implement ``task parallelism'' in most applications where a given dataflow module can, of course, be a parallel (say HPF) program. Systems such as Hence (http://www.netlib.org/hence/index.html) and Code (http://net.cs.utexas.edu/users/code/, [Browne:95b]) also demonstrated this concept. We are currently prototyping an adaptive mesh implementation in the dataflow paradigm.
The Web naturally supports dataflow for this is essentially the model by which distributed information is accessed in the Web client-server model. Furthermore, the already established Web based framework for electronic publication can be naturally extended to support Web publication of software modules within some standardized plug-and-play interface. Thus, it is natural to design WebFlow which integrates compute and information (database, VRML visualization) services in this paradigm. WebFlow builds on the capabilities of MetaWeb to manage and allocate individual processes linked to compute enhanced Web Servers. WebFlow then adds PVM capability for communication that we have already demonstrated on our prototype Web interface to HPF (http://nova.npac.syr.edu:3000/wwvm2/). Based on lessons learned from message pasing systems such as PVM, we are now designing and prototyping the WebVM protocol for object-oriented (MIME based) Web server-to-server communication. Such WebVM architecture (with several evolving implementation options, such as base HTTP+CGI, JavaVM or JavaOS) will enable linking MetaWeb nodes towards ``compute-webs,'' i.e., Web computational surfaces scalable from Intranets to the World-Wide Computer. The management of linked components will use a Java interface for initial network editing and dynamic display. Further, we will support a simple interpretative script that allows adaptive linkage of dataflow modules, which is needed in many applications such as the adaptive mesh refinement. The Web implementation of dataflow naturally allows full integration of VRML visualization where we would expect to use an object database to store the graphics objects produced by the applications. In the later stages, as collaborative (VRML 2.0) environments become developed, WebFlow becomes a way of implementing distributed virtual worlds as a Web implementation of the current military systems, such as DSI (Distributed Simulation Internet).
As shown in Figure 11 and Table 2, WebFlow not only provides a pervasive Web technology base for the dataflow programming paradigm, it can integrate the full range of information, compute, and other NII services with a common visual and scripted frontend. We expect such visual (and later on sensory) authoring tools to become soon increasingly popular for assembling and monitoring components of complex multi-language WebTop systems. Custom visual authoring tools will be offered for various domains and granularity levels. Fig 11 illustrates a future top level WebFlow tool for engineering large scale software systems in terms of coarse grain modules - WebToolkits. Emergent application domains include distributed medical information systems for telemedicine, military command and control, or enterprise information systems for large dynamic corporations.
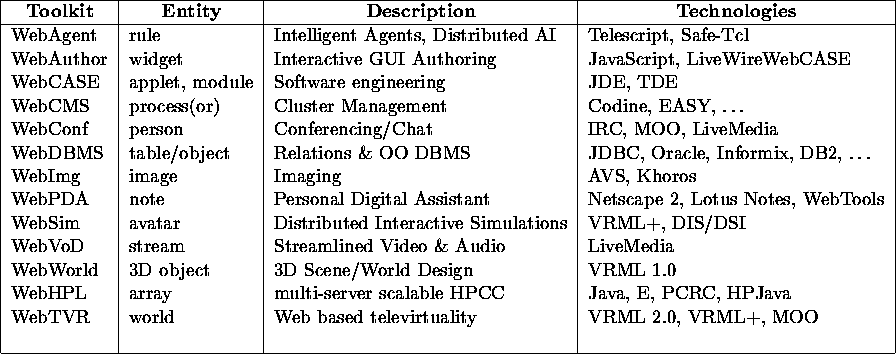
Table 2: Possible Components of a Future WebFlow Environment
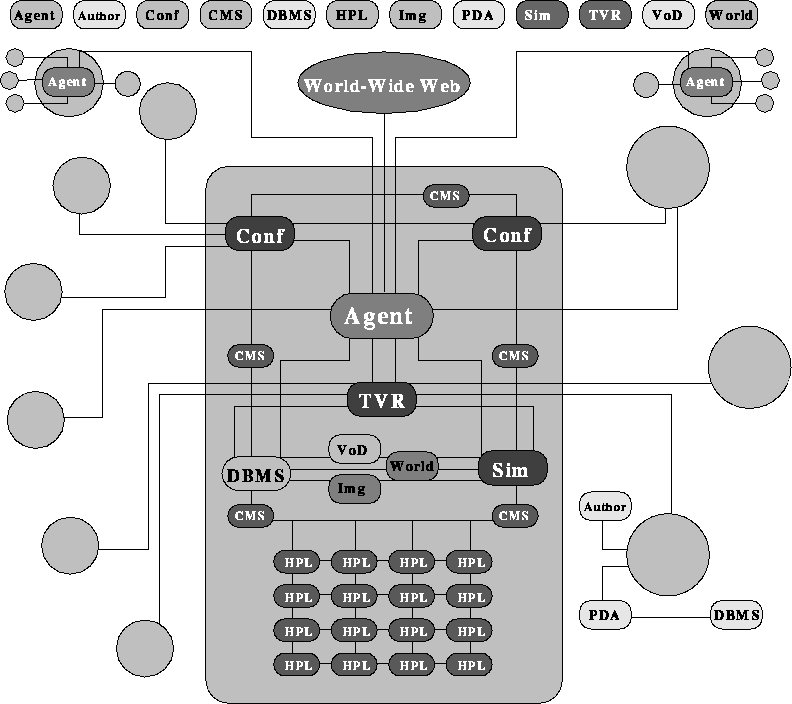
Figure: Example of using WebFlow for large scale software
integration. Modules correspond to WebToolkits collected in
Table 2.