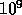 bytes) of memory and approximately six
GigaFLOPS (
bytes) of memory and approximately six
GigaFLOPS (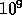 floating point operations per second) peak
performance. The Connection Machine CM-1, CM-2, and CM-200 from
Thinking Machines, and the AMT DAP are also SIMD distributed memory
machines.
floating point operations per second) peak
performance. The Connection Machine CM-1, CM-2, and CM-200 from
Thinking Machines, and the AMT DAP are also SIMD distributed memory
machines.
The field of parallel computing changes rapidly with, as in the
workstation market, vendors leapfrogging each other with new models.
Further, any given model is essentially obsolete after some three
years, with new machines having very different design and software
support. Here, we will discuss some of the machines that are
interesting in 1995. There are three broad classes of machines. The
first is the so-called SIMD, Single Instruction Multiple Data or
synchronous machine, where we have a coupled array of computers with
distributed memory and processing units, i.e., each processor unit is
associated with its own memory. On SIMD machines, each node executes
the same instruction stream. The MP-2 has up to 16K 32-bit processors
and one Gigabyte ( bytes) of memory and approximately six
GigaFLOPS ( floating point operations per second) peak
performance. The Connection Machine CM-1, CM-2, and CM-200 from
Thinking Machines, and the AMT DAP are also SIMD distributed memory
machines.
The MIMD distributed memory architecture is the second major importance architecture, and recent large MPPs (Massively Parallel Processors) have all been of this design where both memory and processing capability are physically distributed. An influential machine of this class is the CM-5 from Thinking Machines, shown in Figure 7, which was a radical departure from their previous SIMD architectures, and this symbolized a growing realization that MIMD architectures were the design of choice for general applications that required the key MIMD characteristic that each node can execute its own instruction stream. The largest CM-5 configuration has 1,024 nodes, 32 Gigabytes of memory, and on some applications, can realize 80 GigaFLOPS. However, the more recent 512-node IBM SP-2 installed at Cornell will outperform the larger number of nodes on the Los Alamos CM-5 system. This illustrates the importance of using the best available sequential node---in IBM's case a powerful RS6000 RISC chip. The CM-5 was handicapped by its custom VLSI on the node. Even if the hardware design was optimal (problematical for the custom CM-5 vector node), we are on a very short technology cycle, and we cannot build the necessary software (in this case compilers) to support idiosyncratic hardware. Any new custom architecture must recognize that its competition---current designs implemented with decreasing feature size---automatically double their performance every 18 months without architecture innovation. All current machines, except the nCUBE, have firmly centered their MIMD parallel systems on pervasive PC or workstation technology---IBM (RS6000), CRAY (Digital alpha), Meiko (Sun), SGI (MIPS) and Convex (HP). Intel just announced that they will deliver to DoE, a TeraFLOPS computer built around their new P6 processor, which has over 10 million transistors packaged in a two-chip (processor and CPU) module. This follows a successful set of machines built around the i860 chip set, which includes a major 1,840-node system at Sandia with the Intel ``Delta Touchstone'' shown in Figure 8 being particularly influential as the first large-scale production MPP supercomputer. Interestingly, DoE is targeting the Intel TeraFLOPS system at simulations of existing nuclear weapons whose continued performance and maintenance is unclear in a world where experimental testing is forbidden.

Figure 7: The CM-5 Produced by Thinking Machines

Figure 8: The ``Delta Touchstone'' Parallel Supercomputer Installed at
Caltech and Produced by Intel. This system uses a mesh architecture
linking 512 nodes, and was a prototype for the Paragon.
All the parallel machines discussed above are ``scalable'' and available in configurations that vary from small $100,000 systems to a full size supercomputer at approximately $30,000,000; the number of nodes and performance scales approximately linearly with the price. In fact, as all the machines use similar VLSI technology, albeit with designs that are optimized in different ways, they very crudely have similar price performance. This, as shown in Figure 2, is much better than that of conventional vector supercomputers, such as those from Cray, IBM, and Japanese vendors. These current Cray and Japanese vector supercomputers are also parallel with up to 16 processors in the very successful CRAY C-90. Their architecture is MIMD shared memory with a group of processors accessing a single global memory.
This shared memory MIMD design is the third major class of parallel architecture. In the vector supercomputer, one builds the fastest possible processor node. This minimizes the number of nodes in the final system (for given cost), but given that parallelism is inevitable and that most problems are not restricted in number of nodes that can be used effectively, an attractive choice is to use the most cost-effective nodes. These are precisely nodes used in the most successful distributed memory MIMD machines. This class of shared memory machine includes the Silicon Graphics (SGI) Power Challenge Systems, whose major sales at the low end of the market have led to a rapid growth in the importance of SGI as a key player in the high-performance computing arena. Correspondingly, the shared memory architecture is receiving increasing attention, which can be examined in a little more detail. Shared memory systems were always considered limited, as the technology such as the bus needed to implement it, would not scale, and indeed, such (bus based) systems are limited to at most 16--32 nodes. However, nodes have increased in power so much that a ``modest'' 32-node shared memory system costing around $2 million is a major supercomputer for most users. Shared-memory systems have always had the advantage that it is easier to implement attractive software environments. The net result is that many expect shared memory to continue to grow in importance and become a dominant feature of mainstream MPP systems. Burton Smith's new Tera shared-memory supercomputer implements this with a special pipelining algorithm so that all processors can access all memory locations in a uniform time. However, most expect a clustered or virtual shared memory architecture with NUMA---nonuniform memory access time. Here machines, such as the Convex Exemplar, new SGI systems, the Stanford experimental DASH, and the now defunct Kendall Square KSR-1,2 are built with a distributed memory, but special hardware and software makes the distributed memory ``act'' as though it is globally available to all processors.
Currently, the dominant parallel computer vendors are American with only modest competition from Europe, with systems built around the transputer chip from Inmos. Japanese manufacturers have so far made little contribution to this field, but as the technology matures, we can expect them to provide formidable competition.