
Parallel Compiler Runtime Consortium
 PCRC Home Page
Partners
PCRC Home Page
Partners
 NPAC
Maryland
Indiana
Rochester
Texas, Austin
CSC
Rice
Florida
NPAC
Maryland
Indiana
Rochester
Texas, Austin
CSC
Rice
Florida
|
PCRC at NPAC
|
Kernel runtime
HPF compiler
HPJava/mpiJava
WebTop computing
Team
|
Documents
Software
NPAC Kernel Runtime Library
As part of the PCRC project we completed development of a high-level runtime library for data-parallel languages. The goal was to simplify translation of languages such as High Performance Fortran (HPF) by providing a coherent interface to the distributed array descriptors and collective operations needed for straightforward and efficient translation of parallel constructs like FORALL and array assignments. This goal was achieved: two experimental subset HPF translators used the library to manage their communications.The kernel of NPAC library is a C++ class library. It is most directly descended from the run-time library of an earlier research implementation of HPF with influences from the Fortran 90D run-time and the CHAOS/PARTI libraries. The kernel is currently implemented on top of MPI. The library design is solidly object-oriented, but efficiency is maintained as a primary goal.
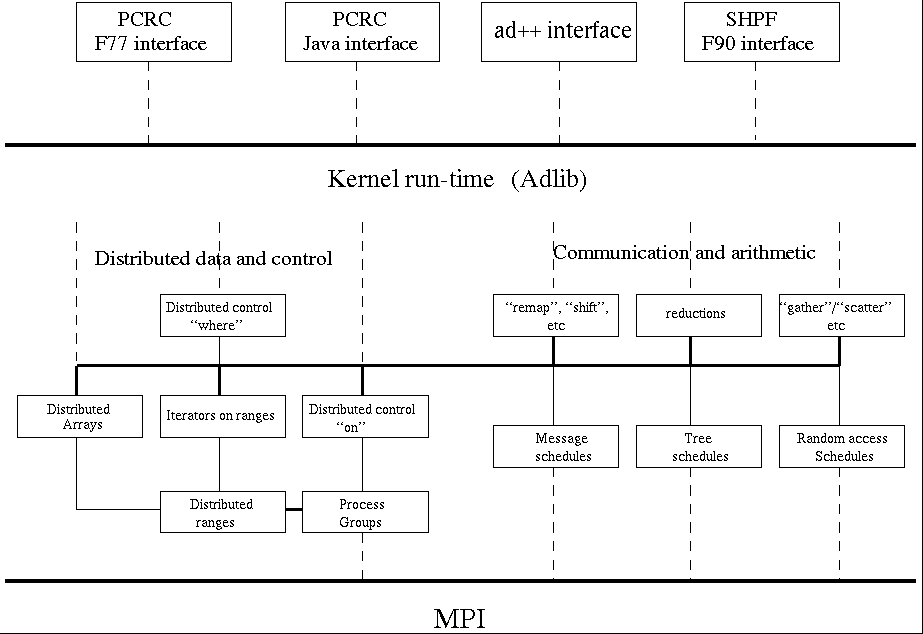
Architecture of NPAC runtime (click on thumbnail for full-size schematic).
The overall architecture of the library is illustrated in figure above. At the top level there are several compiler-specific interfaces to a common run-time kernel. Four interfaces are shown in the figure. They include two different Fortran interfaces (used by different HPF compilers), a user-level C++ interface called ad++, and a Java interface. The development of several top-level interfaces has produced a robust kernel interface, on which we anticipate other language- and compiler- specific interfaces can be constructed relatively straightforwardly.
The largest part of the kernel is concerned with global communication and arithmetic operations on distributed arrays. These are represented on the right-hand side of the figure above. Communication patterns supported include HPF/F90 intrinsics such as CSHIFT and TRANSPOSE, regular-section copy operations, which copy elements between shape-conforming array sections regardless of source and destination mapping, a function that updates ghost areas of a distributed array, and various gather and scatter operations allowing irregular patterns of access. The library also provides essentially all F90 arithmetic transformational functions on distributed arrays and various additional HPF library functions. combining scatter. A complete set of HPF standard library functions is under development.
The data movement schedules are dependent on the infra-structure on the left-hand side of the figure above. This provides the distributed array descriptor, and basic support for traversing distributed data (``distributed control''). Important substructures in the array descriptor are the range object, which describes the distribution of an array global index over a process dimension, and the group object, which describes the embedding of an array in the active processor set.
The kernel is fully functional and quite mature, two of the four interfaces illustrated are complete, and others are in progress. Results of preliminary benchmarks suggest that an HPF compiler based on the high-level NPAC runtime can be competetive with commercial compilers.
Bibliography
-
Bryan Carpenter, Guansong Zhang, and Yuhong Wen.
NPAC PCRC runtime kernel definition.
Technical Report CRPC-TR97726, Center for Research on Parallel
Computation, 1997.
Postscript PDF HTML -
Guansong Zhang, Bryan Carpenter, Geoffrey Fox, Xiaoming Li, Xinying Li, and
Yuhong Wen.
PCRC-based HPF compilation.
In 10th International Workshop on Languages and Compilers for
Parallel Computing, 1997.
Lecture Notes in Computer Science.
Postscript PDF HTML