Experiments in Distributed Computing
Abstract
"This work is aimed at (i) developing and extending SAGA the programming system (ii) application and development of \n\ndistributed programming models, and (iii) analysis data-intensive applications and methods."
Intellectual Merit
"The CI community does not currently have the ability to address ""distributedness"" explicitly. Part of the reason\n\nis the fragmented and silo approaches, that don't scale or are not extensible. SAGA provides\n\na standards based approach to distributed application development that is interoperable and extensible by definition.\n\nResearch on Futuregrid is primarily about establishing the advantages of a SAGA-based approach to distributed\n\napplications -- primarily data-intensive.\n\n"
Broader Impact
"Access to FG is being used to support educational -- graduate and undergraduate activities in an EPSCOR state. \n\nIt also forms the basis of multiple student and training projects."
Use of FutureGrid
"Both Research and Education\n\n\n\nFuturegrid is being used by my group as a critical testbed for (i) understanding and developing Distributed Programming Models, primarily data-intensive applications, (ii) extending/testing SAGA -- as a Distributed Programming Systems (iii) Stable endpoint deployments of OGF/Standards.\n\n\n\nIn Fall 2010, I am teaching a course on Scientific Computing. In particular the Module ""Distributed Scientific Computing"" will rely upon FutureGrid heavily to provide the class with access to (i) SAGA, (ii) Eucalyptus over multiple resources. "
Scale Of Use
More than the scale of a single machine, the ability to utilize as many multiple distributed resources is of great importance.
Publications
Results
Abstract:
There are multiple challenges in the effective design and implementations of scalable distributed applications and infrastructure: the spectrum of challenges range from managing the heterogeneity inherent in distributed systems on the one hand to the lack of well established programming models to support distributed applications. In addition there do not exist well defined set of base capabilities or unifying abstractions needed to reason about how, when and where to distribute applications. Against this backdrop, the range of distributed cyberinfrastructure (DCI) available to researchers is continually evolving. Thus, the process of designing and deploying large-scale DCI, as well as developing applications that can effectively utilize them, presents a critical and challenging agenda for domain researchers and CI developers alike. FutureGrid provides students and researchers with new possibilities to engage in science relating to the state-of-the-art in cloud and grid computing. As student members of the Research in Distributed Cyberinfrastructure and Applications (RADICAL) group, we have taken full advantage of the opportunities that FutureGrid provides.
The students of the RADICAL group have been using SAGA on FutureGrid to address a wide spectrum of challenges: from scalable runtime systems for distributed data-intensive applications (Pilot-MapReduce) to novel dynamic execution modes for traditional HPC applications (Cactus-Spawner) as well as enhanced sampling algorithms (Replica-Exchange). In addition to flexible and scalable applications, we have used FutureGrid to enhance and extend the capabilities of SAGA. In this submission we outline how are some of the ways we are using SAGA on FutureGrid resources to build scalable production runtime systems and software whilst pushing the envelope by pursuing exciting new programming models and possibilities in application
space.
The full report is available here
Addendum:
Summary: The design and development of distributed scientific applications presents a challenging research agenda at the intersection of cyberinfrastructure and computational science. It is no exaggeration that the US Academic community has lagged in its ability to design and implement novel distributed scientific applications, tools and run-time systems that are broadly-used, extensible, interoperable and simple to use/adapt/deploy. The reasons are many and resistant to oversimplification. But one critical reason has been the absence of infrastructure where abstractions, run-time systems and applications can be developed, tested and hardened at the scales and with a degree of distribution (and the concomitant heterogeneity, dynamism and faults) required to facilitate the transition from "toy solutions" to "production grade", i.e., the intermediate infrastructure.
For the SAGA project that is concerned with all of the above elements, FutureGrid has proven to be that *panacea*, the hitherto missing element preventing progress towards scalable distributed applications. In a nutshell, FG has provided a persistent, production-grade experimental infrastructure with the ability to perform controlled experiments, without violating production policies and disrupting production infrastructure priorities. These attributes coupled with excellent technical support -- the bedrock upon which all these capabilities depend, have resulted in the following specific advances in the short period of under a year:
1.Use of FG for Standards based development and interoperability tests:
Interoperability, whether service-level or application-level, is an important requirement of distributed infrastructure. The lack of interoperability (and its corollary -- applications being tied to specific infrastructure), is arguably one of the single most important barriers in the progress and development of novel distributed applications and programming models. However as much as interoperability is important, it is difficult to implement and provide. The reasons are varied, but some critical elements have been the ability to provide (i) Persistent testing infrastructure that can support a spectrum of middleware -- standards-based or otherwise (ii) Single/consistent security context for such tests.
We have used FutureGrid to alleviate both of these shortcomings. Specifically, we have used FG as the test-bed for standards-compliant middleware for extensive OGF standards based testing as part of the Grid Interoperability Now (GIN) and Production Grid Infrastructure (PGI) research group efforts. As part of these extended efforts, we have developed persistent and pervasive experiments, which includes ~10 different middleware and infrastructure types -- most of which are supported FG, including Genesis, Unicore, BES and AWS (i.e. Eucalyptus) and soon OCCI. The fact that the FG endpoints are permanent has allowed us to keep those experiments "alive", and enable us to extend static interoperability requirements to dynamic interoperability requirements. Being relieved of the need to maintain those endpoints has been a critical asset.
See the following URL for visual map on the status of the experiments:
http://cyder.cct.lsu.edu/saga-interop/mandelbrot/demo/today/last/
2. Use of FG for Analysing & Comparing Programming Models and Run-time tools for Computation and Data-Intensive Science
What existing distributed programming models will be applicable on Clouds? What new programming models and run-time abstractions will be required to enable the next-generation of data-intensive applications? We have used FG in our preliminary attempts to answer some of these questions.
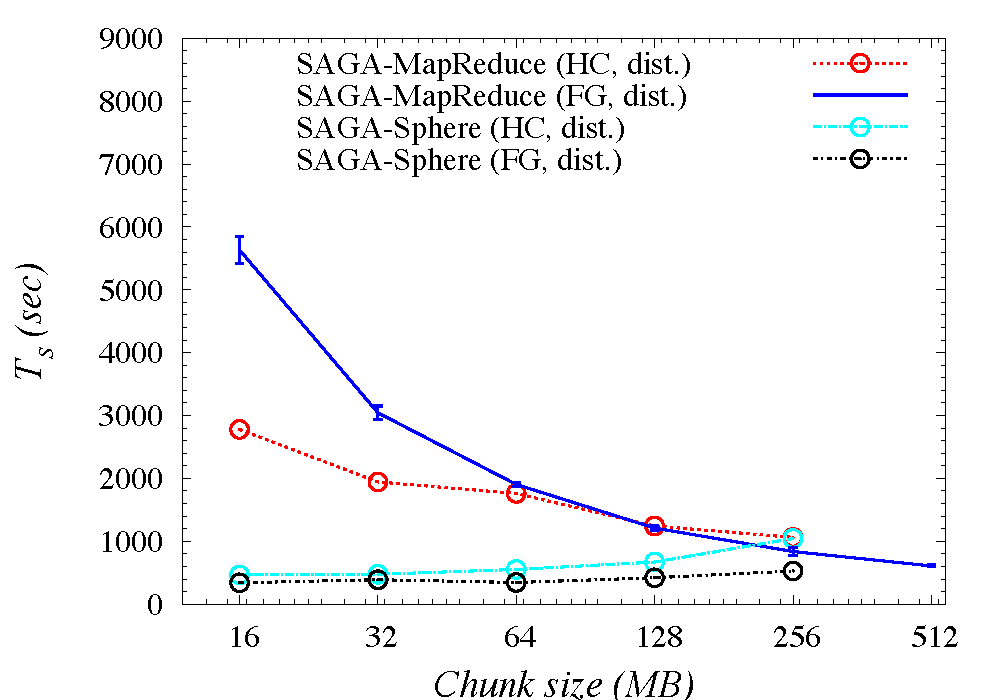
In Ref [http://www.cct.lsu.edu/~sjha/select_publications/2010_fgcs_mapreduce.pdf] published in Future Generation Computing Systems, we compare implementations of the word-count application to not only use multiple, heterogeneous infrastructure (Sector versus DFS), but also to use different programming models (Sphere versus MapReduce).
There is a fundamental need to support dynamic execution of tasks and data in extreme-scale systems. The design, development and experimentation of the abstractions to support this requirement isthus critical; FG has been used for this. In Ref [http://cct.lsu.edu/~sjha/select_publications/bigjob-cloudcom10.pdf
And http://www.cct.lsu.edu/~sjha/select_publications/interop_pilot_job.pdf] we (i) extended the Pilot-Job abstraction for Cloud environments, (ii) understand the basic roles of "system-level" abstractions. There is ongoing but mature work in developing run-time abstractions for data-intensive applications that can be used across the distributed infrastructure -- virtualized or otherwise. Although under development, these efforts rely on FG as a critical component for their testing, performance characterisation & deployment at scale and degrees of distribution that are not possible otherwise.
3. Use of FG for Developing Hybrid Cloud-Grid Scientific Applications and Tools (Autonomic Schedulers) [Work in Conjunction with Manish Parashar's group]
Policy-based (objective driven) Autonomic Scheduler provide a system-level approach to hybrid grid-cloud usage. FG has been used for the development and extension of such Autonomic Scheduling and application requirements. We have integrated the distributed and heterogeneous resources of FG as a pool of resources which can be allocated by the policy-based Autonomic Scheduler (Comet). The Autonomic Scheduler dynamically determines and allocates instances to meet specific objectives, such as lowest time-to-completion, lowest cost etc. We also used FG supplement objective driven pilot jobs on TeraGrid (ranger).
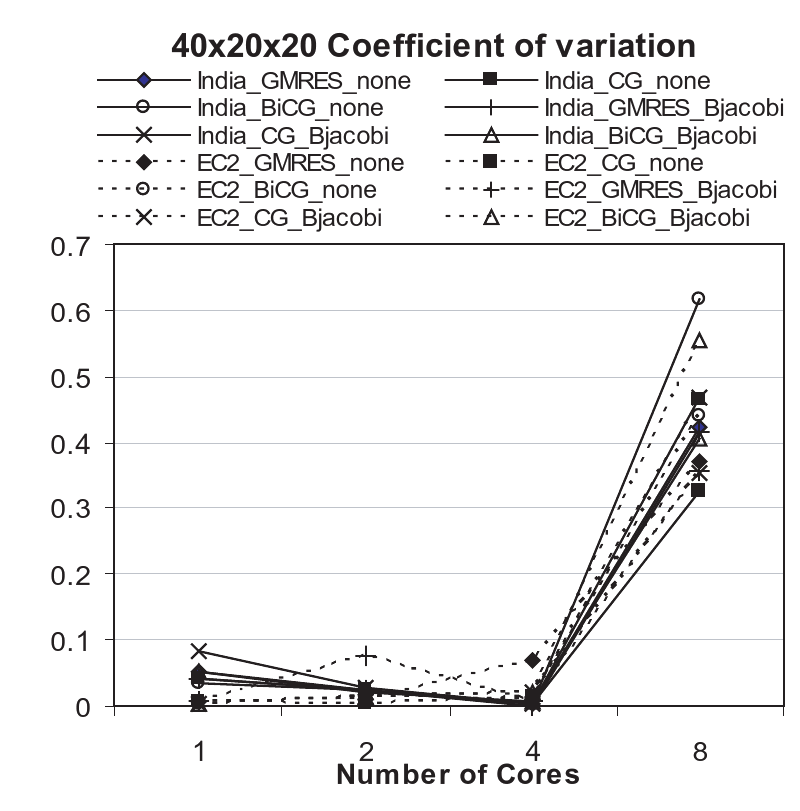
Additionally, during our investigations, we encountered inexplicable variations in our results. These has led to another strand of work that attempts to explore and characterize run-time fluctuations for a given application kernel representative representative of both a large number of MPI/parallel workloads and workflows. Fluctuation appears to be independent of the system load and a consequence of the complex interaction of the MPI library specifics and virtualization layer, as well as operating environment. Thus we have been investigating fluctuations in application performance, due to the cloud operational environment. An explicit aim is to correlate these fluctuation to details of the infrastructure. (See Fig: 40x20x20_coefVariation.pdf). As it is difficult to discern or reverse engineer the specific infrastructure details on EC2 or other commercial infrastructure, FG has provided us a controlled and well understood environment at infrastructure scales that are not possible at the individual PI/resource level.
Initial results from this work can be found at:
More info: - http://cct.lsu.edu/~sjha/select_publications/hybrid-autonomics-sciencecloud.pdf
See also: http://saga.cct.lsu.edu/publications