Results for Project "432. 2014 Topics in Parallel Computation"
Heru Suhartanto
Universitas Indonesia, Faculty of Computer Science
Last Modified:
Results for Project "314. User-friendly tools to play with cloud platforms"
Massimo Canonico
University of Piemonte Orientale, Computer Science Department
Last Modified:
CloudTUI: A multi cloud platform Text User Interface
Author: Irene Lovotti
Institute: Department of Science and Innovation Technology (DiSIT) - University of Piemonte Orientale - ITALY
Supervisor: Massimo Canonico
Contact info: massimo.canonico@unipmn.it
CloudTUI is a Text-User-Interface that helps cloud users to manage three of the most famous cloud platforms: Eucalyptus, Nimbus and OpenStack. With CloudTUI you can easily create/delete/monitor instances and volumes.
We tried to make it as simple as possible: in order to use CloudTUI you just have to unpack the cloudTUI.tgz file and run "python cloudTUI.py".
The source code is available here, while screenshots are available here and, finally, a demo video is here.
video of cloudTUI:
CloudTUI-advanced (BETA)
Author: Andrea Lombardo
Institute: Department of Science and Innovation Technology (DiSIT) -
University of Piemonte Orientale - ITALY
Superadvisor: Massimo Canonico
Contact info: massimo.canonico@unipmn.it
CloudTUI-advanced is a tool that helps cloud users to manage workspaces in Nimbus. With this tool the user can easily
create/delete/monitor his workspaces and moreover, iti is possible to specify policy in order to decide when scale-up/scale-down the system. More details in "Scale-up and scale-down" paragraph. CloudTUI-advanced is written in python and uses boto libraries.
The source code is available here, while screenshots are availble here and, finally, a short demo video is here.
Please note that CloudTUI-advance is still in beta version. Some of the features could not work properly. We are working right now on fixing all bugs. Of course, we would be happy if you give a try to your software out and let us know what you think.
video of cloudTUI-advance:
For support or any comment: massimo.canonico@unipmn.it
Results for Project "130. Optimizing Scientific Workflows on Clouds"
Weiwei Chen
University of Southern California, Information Sciences Institute
Last Modified:
We have two on-going projects that have utilized resources provided by FutureGrid.
The first project aims to address the problem of scheduling large workflows onto multiple execution sites with storage constraints. Three heuristics are proposed to first partition the workflow into sub-workflows and then schedule to the optimal execution sites. In our experiments, we deployed multiple clusters with Eucalyptus and up to 32 virtual machines. Each execution site contains a Condor pool and a head node visible to the network. The performance with three real-world workflows shows that our approach is able to satisfy storage constraints and improve the overall runtime by up to 48% over a default whole-workflow scheduling. A paper [1] has been accepted based on this work.
The second project aims to identify the different overheads in workflow execution and to evaluate how optimization methods help reduce overheads and improve runtime performance. In this project, we present the workflow overhead analysis for our runs in FutureGrid deployed with Eucalyptus. We present the overhead distribution and conclude that the overheads satisfy an exponential or uniform distribution. We compared three metrics to calculate the cumulative sum of overhead considering the overlap between overheads. In addition, we indicated how experimental parameters impact the overhead and thereby the overall performance,. We then showed an integrated view over the overheads help us understand the performance of optimization methods better. A paper [2] based on this work has been accepted. In the future, we plan to evaluate the effectiveness of our approach with additional optimization methods. Additionally, our current work is based on static provisioning and we plan to analyze the performance along with dynamic provisioning.
Furthermore, we have developed a workflow simulator called WorkflowSim [5] based on the traces collected from experiments that were run on FutureGrid.
Reference:
[1] Partitioning and Scheduling Workflows across Multiple Sites with Storage Constraints, Weiwei Chen, Ewa Deelman, 9th International Conference on Parallel Processing and Applied Mathematics (PPAM 2011), Poland, Sep 2011
[2] Workflow Overhead Analysis and Optimizations, Weiwei Chen, Ewa Deelman, The 6th Workshop on Workflows in Support of Large-Scale Science, in conjunction with Supercomputing 2011, Seattle, Nov 2011
[3] FutureGrid - a reconfigurable testbed for Cloud, HPC and Grid Computing Geoffrey C. Fox, Gregor von Laszewski, Javier Diaz, Kate Keahey, Jose Fortes, Renato Figueiredo, Shava Smallen, Warren Smith, and Andrew Grimshaw, Chapter in "Contemporary High Performance Computing: From Petascale toward Exascale", editor Jeff Vetter, April 23, 2013 by Chapman and Hall/CRC
[4] Functional Representations of Scientific Workflows, Noe Lopez-Benitez, JSM Computer Science and Engineering 1(1): 1001
[5] WorkflowSim: A Toolkit for Simulating Scientific Workflows in Distributed Environments, Weiwei Chen, Ewa Deelman, The 8th IEEE International Conference on eScience 2012 (eScience 2012), Chicago, Oct 8-12, 2012
Results for Project "431. BIOINFORMATIC ANALYSIS OF VIRUS GENOMES AND PROTEIN MODELLING IN RATIONAL VACCINE DESIGN"
Michael Franklin
University of Pittsburgh, Molecular Biology and Ecology
Last Modified:
Results for Project "430. ICOM4036 Cuda Project"
Samuel Matos
University of Puerto Rico, Mayaguez Campus, Department of Electrical and Computer Engineering
Last Modified:
None Yet.
Results for Project "428. Cloud Infrastructure Utilization "
Rahul Limbole
Veermata Jijabai Technological Institute Mumbai, Computer Science Department
Last Modified:
Results for Project "429. Proto-Runtime on the Grid"
Sean Halle
CWI, Netherlands, Formal Methods Group
Last Modified:
Supplied as they become available: Stay tuned!
Results for Project "427. Apache Stratos deployment for MOOC"
Lakmal Warusawithana
WSO2 Inc, Engineering - Stratos
Last Modified:
Results for Project "426. Comparison of Architectures to Support Deep Learning Applications"
Scott McCaulay
Indiana University, UITS
Last Modified:
Results for Project "425. Improved next generation sequencing analytics"
Sarath Chandra Janga
IUPUI, Department of Biohealth Informatics, IUPUI School of Informatics and Computing
Last Modified:
Results for Project "424. Deep Learning with GPUs"
Mohammed Korayem
IU , Computer Science IU
Last Modified:
Results for Project "423. Investigating security issues in OpenStack "
Yangyi Chen
Indiana University Bloomington, School of Informatics and Computing
Last Modified:
Results for Project "422. Enabling Time-sensitive Applications on Virtualized Computing Systems"
Ming Zhao
Florida International University, School of Computing and Information Sciences
Last Modified:
Results for Project "421. Coordinated QoS-Driven Management of Cloud Computing and Storage Resources"
Ming Zhao
Florida International University, School of Computing and Information Sciences
Last Modified:
Results for Project "420. QoS-driven Storage Management for High-end Computing Systems"
Ming Zhao
Florida International University, School of Computing and Information Sciences
Last Modified:
Results for Project "415. Private Cloud Computing"
Ari Kurnianto
Yarsi University, Yarsi Universty
Last Modified:
Results for Project "419. Distributed Real-time Computation System"
Yukai Xiao
Indiana University Bloomington, computer science department
Last Modified:
Results for Project "416. External Secure OpenStack Deployment and Integration with FutureGrid"
Chad Huneycutt
Georgia Institute of Technology, School of Computer Science, College of Computing
Last Modified:
a) IU has developed documentation for securely deploying clouds with NGINX
Results for Project "418. Course: Cloud Computing Class - fourth edition"
Massimo Canonico
University of Piemonte Orientale, Computer Science Department
Last Modified:
Results for Project "417. Active and Janus Particles"
Ubaldo Cordova-Figueroa
University of Puerto Rico - Mayaguez, Department of Chemical Engineering
Last Modified:
Results for Project "414. Creating a Highly Configurable, Scalable Cloud Test Bed Using Nimbus and Phantom"
Patricia Teller
The University of Texas at El Paso, Computer Science
Last Modified:
Results for Project "413. Running SWAT model on the cloud"
Lan Zhao
Purdue University, ITaP Research Computing
Last Modified:
Results for Project "412. Short Course on Algorithmic Differentiation"
Jean Utke
Argonne National Laboratory, MCS
Last Modified:
Results for Project "411. ILS-Z604 Big Data Analytics for Web and Text - SP14 Group #2"
Trevor Edelblute
Indiana University, Department of Information & Library Science, School of Informatics & Computing
Last Modified:
Results for Project "227. V3VEE Project"
Peter Dinda
Northwestern University, EECS
Last Modified:
All V3VEE project papers, presentations, and the Palacios codebase are available from v3vee.org. The most relevant papers for this proposal are:
- L. Xia, Z. Cui, J. Lange, Y. Tang, P. Dinda, P. Bridges, VNET/P: Bridging the Cloud and High Performance Computing Through Fast Overlay Networking, Proceedings of the 21st ACM Symposium on High-performance Parallel and Distributed Computing (HPDC 2012), accepted, to appear. (also TR version) J. Lange, P. Dinda, K. Hale, L. Xia, An Introduction to the Palacios Virtual Machine Monitor---Version 1.3, Technical Report NWU-EECS-11-10, Department of Electrical Engineering and Computer Science, Northwestern University, November, 2011.
- J. Lange, K. Pedretti, P. Dinda, P. Bridges, C. Bae, P. Soltero, A. Merritt, Minimal Overhead Virtualization of a Large Scale Supercomputer, Proceedings of the 2011 ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments (VEE 2011), March, 2011.
- J. Lange, K. Pedretti, T. Hudson, P. Dinda, Z. Cui, L. Xia, P. Bridges, A. Gocke, S. Jaconette, M. Levenhagen, R. Brightwell, Palacios and Kitten: New High Performance Operating Systems for Scalable Virtualized and Native Supercomputing, Proceedings of the 24th IEEE International Parallel and Distributed Processing Symposium (IPDPS 2010), April, 2010.
Results for Project "167. FutureGrid User Support"
Gary Miksik
Indiana University, Digital Science Center, School of Informatics and Computing
Last Modified:
I am closing out this project, as it was only created to track support tasks, which are done in other venues, such as Jira and Excel.
Results for Project "344. Exploring map/reduce frameworks for users of traditional HPC"
Glenn K. Lockwood
University of California San Diego, San Diego Supercomputer Center
Last Modified:
Source code for these guides is also available on GitHub. Work is ongoing.
- Guide to Running Hadoop Clusters on Traditional HPC
- Guide to Writing Hadoop Jobs in Python with Hadoop Streaming
- Guide to Parsing Variant Call Format (VCF) Files with Hadoop Streaming
Results for Project "45. Experiments in Distributed Computing"
Shantenu Jha
Louisiana State University, Center for Computation & Technology
Last Modified:
Title: Building Scalable, Dynamic and Distributed Applications Using SAGA
Abstract:
There are multiple challenges in the effective design and implementations of scalable distributed applications and infrastructure: the spectrum of challenges range from managing the heterogeneity inherent in distributed systems on the one hand to the lack of well established programming models to support distributed applications. In addition there do not exist well defined set of base capabilities or unifying abstractions needed to reason about how, when and where to distribute applications. Against this backdrop, the range of distributed cyberinfrastructure (DCI) available to researchers is continually evolving. Thus, the process of designing and deploying large-scale DCI, as well as developing applications that can effectively utilize them, presents a critical and challenging agenda for domain researchers and CI developers alike. FutureGrid provides students and researchers with new possibilities to engage in science relating to the state-of-the-art in cloud and grid computing. As student members of the Research in Distributed Cyberinfrastructure and Applications (RADICAL) group, we have taken full advantage of the opportunities that FutureGrid provides.
The students of the RADICAL group have been using SAGA on FutureGrid to address a wide spectrum of challenges: from scalable runtime systems for distributed data-intensive applications (Pilot-MapReduce) to novel dynamic execution modes for traditional HPC applications (Cactus-Spawner) as well as enhanced sampling algorithms (Replica-Exchange). In addition to flexible and scalable applications, we have used FutureGrid to enhance and extend the capabilities of SAGA. In this submission we outline how are some of the ways we are using SAGA on FutureGrid resources to build scalable production runtime systems and software whilst pushing the envelope by pursuing exciting new programming models and possibilities in application
space.
The full report is available here
Addendum:
Summary: The design and development of distributed scientific applications presents a challenging research agenda at the intersection of cyberinfrastructure and computational science. It is no exaggeration that the US Academic community has lagged in its ability to design and implement novel distributed scientific applications, tools and run-time systems that are broadly-used, extensible, interoperable and simple to use/adapt/deploy. The reasons are many and resistant to oversimplification. But one critical reason has been the absence of infrastructure where abstractions, run-time systems and applications can be developed, tested and hardened at the scales and with a degree of distribution (and the concomitant heterogeneity, dynamism and faults) required to facilitate the transition from "toy solutions" to "production grade", i.e., the intermediate infrastructure.For the SAGA project that is concerned with all of the above elements, FutureGrid has proven to be that *panacea*, the hitherto missing element preventing progress towards scalable distributed applications. In a nutshell, FG has provided a persistent, production-grade experimental infrastructure with the ability to perform controlled experiments, without violating production policies and disrupting production infrastructure priorities. These attributes coupled with excellent technical support -- the bedrock upon which all these capabilities depend, have resulted in the following specific advances in the short period of under a year:
1.Use of FG for Standards based development and interoperability tests:
Interoperability, whether service-level or application-level, is an important requirement of distributed infrastructure. The lack of interoperability (and its corollary -- applications being tied to specific infrastructure), is arguably one of the single most important barriers in the progress and development of novel distributed applications and programming models. However as much as interoperability is important, it is difficult to implement and provide. The reasons are varied, but some critical elements have been the ability to provide (i) Persistent testing infrastructure that can support a spectrum of middleware -- standards-based or otherwise (ii) Single/consistent security context for such tests.
We have used FutureGrid to alleviate both of these shortcomings. Specifically, we have used FG as the test-bed for standards-compliant middleware for extensive OGF standards based testing as part of the Grid Interoperability Now (GIN) and Production Grid Infrastructure (PGI) research group efforts. As part of these extended efforts, we have developed persistent and pervasive experiments, which includes ~10 different middleware and infrastructure types -- most of which are supported FG, including Genesis, Unicore, BES and AWS (i.e. Eucalyptus) and soon OCCI. The fact that the FG endpoints are permanent has allowed us to keep those experiments "alive", and enable us to extend static interoperability requirements to dynamic interoperability requirements. Being relieved of the need to maintain those endpoints has been a critical asset.
See the following URL for visual map on the status of the experiments:
http://cyder.cct.lsu.edu/saga-interop/mandelbrot/demo/today/last/
2. Use of FG for Analysing & Comparing Programming Models and Run-time tools for Computation and Data-Intensive Science
What existing distributed programming models will be applicable on Clouds? What new programming models and run-time abstractions will be required to enable the next-generation of data-intensive applications? We have used FG in our preliminary attempts to answer some of these questions.
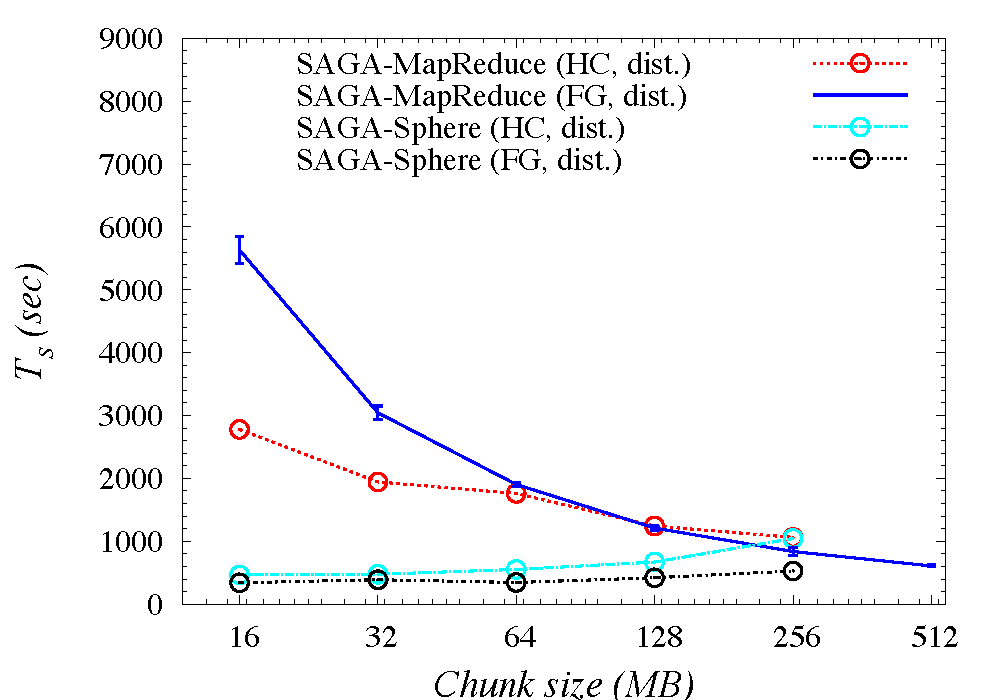
In Ref [http://www.cct.lsu.edu/~sjha/select_publications/2010_fgcs_mapreduce.pdf] published in Future Generation Computing Systems, we compare implementations of the word-count application to not only use multiple, heterogeneous infrastructure (Sector versus DFS), but also to use different programming models (Sphere versus MapReduce).
There is a fundamental need to support dynamic execution of tasks and data in extreme-scale systems. The design, development and experimentation of the abstractions to support this requirement isthus critical; FG has been used for this. In Ref [http://cct.lsu.edu/~sjha/select_publications/bigjob-cloudcom10.pdf
And http://www.cct.lsu.edu/~sjha/select_publications/interop_pilot_job.pdf] we (i) extended the Pilot-Job abstraction for Cloud environments, (ii) understand the basic roles of "system-level" abstractions. There is ongoing but mature work in developing run-time abstractions for data-intensive applications that can be used across the distributed infrastructure -- virtualized or otherwise. Although under development, these efforts rely on FG as a critical component for their testing, performance characterisation & deployment at scale and degrees of distribution that are not possible otherwise.
3. Use of FG for Developing Hybrid Cloud-Grid Scientific Applications and Tools (Autonomic Schedulers) [Work in Conjunction with Manish Parashar's group]
Policy-based (objective driven) Autonomic Scheduler provide a system-level approach to hybrid grid-cloud usage. FG has been used for the development and extension of such Autonomic Scheduling and application requirements. We have integrated the distributed and heterogeneous resources of FG as a pool of resources which can be allocated by the policy-based Autonomic Scheduler (Comet). The Autonomic Scheduler dynamically determines and allocates instances to meet specific objectives, such as lowest time-to-completion, lowest cost etc. We also used FG supplement objective driven pilot jobs on TeraGrid (ranger).
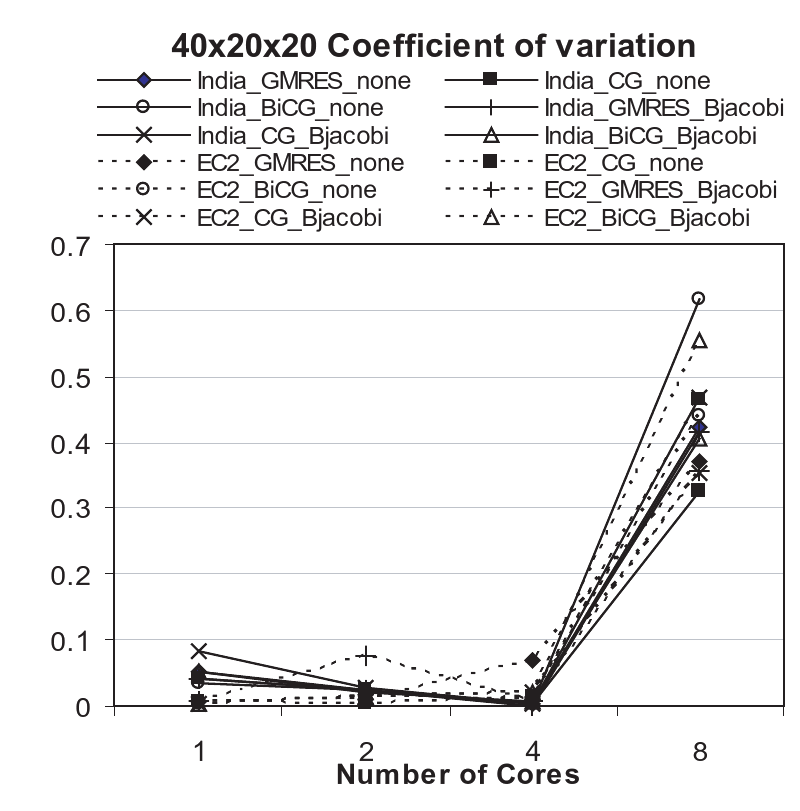
Additionally, during our investigations, we encountered inexplicable variations in our results. These has led to another strand of work that attempts to explore and characterize run-time fluctuations for a given application kernel representative representative of both a large number of MPI/parallel workloads and workflows. Fluctuation appears to be independent of the system load and a consequence of the complex interaction of the MPI library specifics and virtualization layer, as well as operating environment. Thus we have been investigating fluctuations in application performance, due to the cloud operational environment. An explicit aim is to correlate these fluctuation to details of the infrastructure. (See Fig: 40x20x20_coefVariation.pdf). As it is difficult to discern or reverse engineer the specific infrastructure details on EC2 or other commercial infrastructure, FG has provided us a controlled and well understood environment at infrastructure scales that are not possible at the individual PI/resource level.
Initial results from this work can be found at:
More info: - http://cct.lsu.edu/~sjha/select_publications/hybrid-autonomics-sciencecloud.pdf
See also: http://saga.cct.lsu.edu/publications
Results for Project "70. Big Data for Science Summer School July 26-30 2010"
Judy Qiu
Indiana University, School of Informatics and Computing
Last Modified:
The workshop was successfully delivered with good reviews. In this “Big Data for Science” workshop, over 200 students across 10 institutions (Arkansas High Performance Computing Center, University of Arkansas, Fayetteville; Electronic Visualization Laboratory, University of Illinois at Chicago; Indiana University, Bloomington; Institute for Digital Research and Education, University of California, Los Angeles; Michigan State University, East Lansing; Pennsylvania State University, University Park; University of Iowa, Iowa City; University of Minnesota Supercomputing Institute, Minneapolis; University of Notre Dame, Notre Dame, Indiana; and University of Texas at El Paso). Additionally 100 additional students attended via streaming video. Students in the workshop used FutureGrid in hands-on activities that covered, among others, Hadoop/MapReduce, Twister, Grid Appliance, and GroupVPN.
See http://salsahpc.indiana.edu/tutorial/index.html
Results for Project "172. Cloud-TM"
Paolo Romano
INESC ID, Lisbon, Distributed Systems Group
Last Modified:
2012
Sebastiano Peluso, Pedro Ruivo, Paolo Romano, Francesco Quaglia, and Luis RodriguesWhen Scalability Meets Consistency: Genuine Multiversion Update Serializable Partial Data Replication32nd International Conference on Distributed Computing Systems (ICDCS'12)
Diego Didona, Pierangelo Di Sanzo, Roberto Palmieri, Sebastiano Peluso, Francesco Quaglia and Paolo Romano,Automated Workload Characterization in Cloud-based Transactional Data Grids17th IEEE Workshop on Dependable Parallel, Distributed and Network-Centric Systems (DPDNS'12)
Paolo Romano,Elastic, scalable and self-tuning data replication in the Cloud-TM platform,Proceedings of 1st European Workshop on Dependable Cloud Computing (EWDCC'12)
Paolo Romano and M. Leonetti,Self-tuning Batching in Total Order Broadcast Protocols via Analytical Modelling and Reinforcement LearningIEEE International Conference on Computing, Networking and Communications, Network Algorithm & Performance Evaluation Symposium (ICNC'12), Jan. 2012
2011Self-optimizing transactional data grids for elastic cloud environments, P. Romano, CloudViews 2011Boosting STM Replication via Speculation, P. Romano, R. Palmeri, F. Quaglia, L. Rodrigues, 3rd Workshop on the Theory of Transactional MemoryData Access Pattern Analysis and Prediction for Object-Oriented Applications, S. Garbatov, J. Cachopo, INFOCOMP Journal of Computer Science, December 2011Software Cache Eviction Policy based on Stochastic Approach, S. Garbatov, J. Cachopo, The Sixth International Conference on Software Engineering Advances (ICSEA 2011), October 2011Optimal Functionality and Domain Data Clustering based on Latent Dirichlet Allocation, S. Garbatov, J. Cachopo, The Sixth International Conference on Software Engineering Advances (ICSEA 2011), October 2011Strict serializability is harmless: a new architecture for enterprise applications, S. Fernandes, J. Cachopo, Proceedings of the ACM international conference on Object oriented programming systems languages and applications companionTowards a simple programming model in Cloud Computing platforms, J. Martins, J. Pereira, S.M. Fernandes, J. Cachopo, First International Symposium on Network Cloud Computing and Applications (NCCA2011)On Preserving Domain Consistency for an Evolving Application, J. Neves, J. Cachopo, Terceiro Simpósio de Informática, September 2011Oludap, an AI approach to web gaming in the Cloud, V. Ziparo, Open World Forum 2011, September 2011Towards Autonomic Transactional Replication for Cloud Environments, M. Couceiro, P. Romano, L. Rodrigues, European Research Activities in Cloud ComputingSPECULA: um Protocolo de Replicação Preditiva para Memória Transaccional por Software Distribuída, J. Fernandes, P. Romano, L. Rodrigues, Simpósio de Informática, Universidade de Coimbra (INFORUM 2011)Replicação Parcial em Sistemas de Memória Transaccional, P. Ruivo, P. Romano, L., Rodrigues, Simpósio de Informática, Universidade de Coimbra (INFORUM 2011)Integrated Monitoring of Infrastructures and Applications in Cloud Environments, R. Palmieri, P. Di Sanzo, F. Quaglia, P. Romano, S. Peluso, D. Didona, Workshop on Cloud Computing: Projects and Initiatives (CCPI 2011)PolyCert: Polymorphic Self-Optimizing Replication for In-Memory Transactional Grids, M. Couceiro, P. Romano and L. Rodrigues, ACM/IFIP/USENIX 12th International Middleware Conference (Middleware 2011)Exploiting Total Order Multicast in Weakly Consistent Transactional Caches, P. Ruivo, M. Couceiro, P. Romano and L. Rodrigues, Proc. IEEE 17th Pacific Rim International Symposium on Dependable Computing (PRDC’11)Tutorial on Distributed Transactional Memories, M. Couceiro, P. Romano and L. Rodrigues, 2011 International Conference on High Performance Computing & Simulation July 2011Keynote Talk: Autonomic mechanisms for transactional replication in elastic cloud environments, P. Romano, 2nd Workshops on Software Services (WOSS), Timisoara, Romania, June 2011Self-tuning Batching in Total Order Broadcast Protocols via Analytical Modelling and Reinforcement Learning , P. Romano and M. Leonetti, ACM Performance Evaluation Review, to appear (also presented as a Poster at IFIP Performance 2011 Symposium)On the Analytical Modeling of Concurrency Control Algorithms for Software Transactional Memories: the Case of Commit-Time-Locking, P. Di Sanzo, B. Ciciani, F. Quaglia, R. Palmieri and Paolo Romano, Elsevier Performance Evaluation Journal (to appear)OSARE: Opportunistic Speculation in Actively REplicated Transactional Systems, R. Palmieri, F. Quaglia and Paolo Romano, The 30th IEEE Symposium on Reliable Distributed Systems (SRDS 2011), Madrid, Spain, to appear.A Generic Framework for Replicated Software Transactional Memories, N. Carvalho, P. Romano and L. Rodrigues, , Proceedings of the 9th IEEE International Symposium on Network Computing and Applications (NCA), Cambridge, Massachussets, USA, IEEE Computer Society Press, August 2011Autonomic mechanisms for transactional replication in elastic cloud environments (Keynote Talk), Workshop on Software Services: Cloud Computing and Applications based on Software Services, Paolo Romano, Timisoara, June 2011SCert: Speculative Certification in Replicated Software Transactional Memories. N. Carvalho, P. Romano and L. Rodrigues. Proceedings of the 4th Annual International Systems and Storage Conference (SYSTOR 2011), Haifa, Israel, June 2011.
2010Asynchronous Lease-based Replication of Software Transactional Memory. N. Carvalho, P. Romano and L. Rodrigues. Proceedings of the ACM/IFIP/USENIX 11th Middleware Conference (Middleware), Bangalore, India, ACM Press, November 2010.Analytical Modeling of Commit-Time-Locking Algorithms for Software Transactional Memories. P. Di Sanzo, B. Ciciani, F. Quaglia, R. Palmieri and P. Romano. Proceedings of the 35th International Computer Measurement Group Conference (CMG), Orlando, Florida, Computer Measurement Group, December 2010 (also presented in the 1st Workshop on "Informatica Quantitative" (InfQ), Pisa, July 2010)Do we really need parallel programming or should we strive for parallelizable programming instead? João Cachopo. SPLASH 2010 Workshop on Concurrency for the Application Programmer. October, 2010.A Machine Learning Approach to Performance Prediction of Total Order Broadcast Protocols. M. Couceiro, P. Romano and L. Rodrigues. Proceedings of the 4th IEEE International Conference on Self-Adaptive and Self-Organizing Systems (SASO), Budapest, Hungary, IEEE Computer Society Press, September 2010An Optimal Speculative Transactional Replication Protocol. P. Romano, R. Palmieri, F. Quaglia, N. Carvalho and L. Rodrigues. Proceedings of the 8th IEEE International Symposium on Parallel and Distributed Processing with Applications (ISPA), Taiwan, Taipei, IEEE Computer Society Press, September 2010.
Results for Project "336. Understanding Fluid Flow in Microchannels using a CometCloud-based Federated HPC infrastructure"
Javier Diaz Montes
Rutgers, The State University of New Jersey, Rutgers Discovery Informatics Institute (RDI2) / NSF Center for Cloud and Autonomic Computing (CAC)
Last Modified:
Website of the project, which includes a technical report: http://nsfcac.rutgers.edu/uff/
Javier Diaz-Montes, Manish Parashar, Ivan Rodero, Jaroslaw Zola, Baskar Ganapathysubramanian, Yu Xie; CometCloud: Using a Federated HPC-Cloud to Understand Fluid Flow in Microchannels, Hpc in the Cloud, May 2013.
Javier Diaz-Montes, Manish Parashar, Ivan Rodero, Jaroslaw Zola, Baskar Ganapathysubramanian, Yu Xie; Understanding Fluid Flow in Microchannel, Digital Manufacturer Report, May 2013.
Results for Project "84. Development of an Index File System to Support Geoscience Data with Hadoop"
Sonali Karwa
Indiana University, Pervasive Technology Institute
Last Modified:
My results are uploaded at this link : https://slashtmp.iu.edu/files/download?FILE=skarwa% 2F98132iCfiVK
The Password to download : futuregrid
Results for Project "322. Parallel Clustering on GPU's"
Gregor von Laszewski
Indiana University, Community Grids Laboratory
Last Modified:
Here are some performance results of Cmeans, GlobalReductions, and Runtime tool projects.
Figure 1: Speedup of MPI/OpenMP implmenetation of C-means on multiple GPUs.
Figure 1 shows the speedup of MPI/OpenMP/CUDA implementation of C-means for 7 million events using up to 18 GPU cards (9nodes with 2 cards each) on GPU cluster. The kernel speedup is cacluated by only measuring the GPU kernel overhead, while overall speedup is caculated by measuring GPU kernel, CPU overhead, and memcpy between device and host memory. As expected, the kernel speedup is higher than overall speedup which contains overhead in sequetnail component. In addition, as showed in Figure 1, there is big performance fluctuation for different number of GPU nodes due to the memory coalesced issue related with input granularity.

Figure 2: performance of Kmeans with different runtime technologies.
We evaluated performance of Kmeans application with GlobalReduction method and different runtime technologies including mpi, hadoop and mahout on four nodes on Delta cluster. The results indicate that mpi-cuda implementation can give a speedup of 14 over mpi-openmp for large data sets. And hadoop-cuda is 1.15x and 1.04x faster than hadoop-openmp and hadoop-java respectively. The hadoop-cuda didn’t have much performance improvement because it has to load data from disk to memory and then to gpu device memory during each iterations, while the mpi implementation can cache the static data in device memory during each iterations. The results also showed that the standard implementation mahout is 1.76x slower than our hadoop implementation. This is because our Hadoop implementation uses much coarse granularity task, and it can get performance improvement by leveraging the local reduction, while mahout implementation uses much finer granularity for each map task, which trigger larger communication overhead during shuffle stage. The results also indicate that panda-cuda implementation is 132.13 times faster than Mahout, but is 2.37 times slower than mpi-cuda implementation
Figure 3: Speedup Performance of Matrix Multiplication Jobs using Panda-1GPU-HostMap, Panda-1GPU-DeviceMap, Panda-1GPU-DeviceMap+24CPU, MAGAMA-1GPU, MAGMA-1GPU+24CPU, and CUDA-1GPU implementations on Delta machine.
Figure 3 shows the speedup performance of matrix multiplication jobs using Panda-1GPU-DeviceMap, Panda-1GPU-HostMap, Panda-24CPU, Panda-1GPU-DeviceMap+24CPU, MAGMA-1GPU, MAGMA-1GPU+24CPU, CUDA-1GPU, Mars-1GPU, and Phoenix-24CPU. The CUDA-1GPU implementation is around 1.52~1.94x faster than Panda-1GPU-DeviceMap for large matrices sizes. The Mars and Phoenix crashed when the matrices sizes larger than 5000 and 3000 respectively. For 3000x3000 matrix multiplication job, Panda-1GPU-DeviceMap achieves the speedup of 15.86x, and 7.68x over Phoenix and Mars respectively. Panda-1GPU-HostMap is only a little slower than CUDA-1GPU for large matrices. Panda 1GPU-DeviceMap+24CPU improve the performance by 5.1% over Panda-1GPU on average. The workload distribution among GPU and CPU is 90/10 as calculated by auto tuning utility. MAGMA-1GPU+24CPU increase the performance by 7.2% over MAGMA-1GPU, where the workload distribution among GPU and CPU is determined by its auto tuning utility


Results for Project "214. Mining Interactions between Network Community Structure and Information Diffusion"
Yong-Yeol Ahn
Indiana University, Bloomington, School of Informatics and Computing
Last Modified:
1. Lilian Weng, Filippo Menczer, Yong-Yeol Ahn, "Community structure and Spreading of Social Contagions" (Preprint, to be submitted to WWW'13)
Results for Project "87. I399 Bioinformatics and Cyberinfrastructure project - 1000 Genomes protein analysis"
Andrew Younge
Indiana University, Community Grids Laboratory
Last Modified:
The 1000 Genome Project is the first project of its kind to take a significantly large number of participants’ DNA information and broadcast it publicly to the world in order to provide a detailed source for sequencing genomes. It is a collaboration of numerous international research teams, with the end goal of finding the most variations in at least 1% of the population studied. They enlisted people from areas across the world in order to incorporate specific regions and cultural differences, and to ensure that they are not using a homogeneous population.
We used the Japanese and European data sets for our project because there seemed to be a clear contrast between cultural groups. There seemed to be enough difference in these two groups for the results to seem interesting and understandable in order to see if a larger project could stem from this one (future scientific research of protein discrepancies between other groups etc). There was also an issue of data size in relation to the time we had for this project. In order to sequence one person the time aspect of the project does not seem as drastic, but we used the sequenced genome of ninety European participants and one hundred and five Japanese participants (The more samples we have from each region the more accurate our analysis will be since we are trying to determine our results in reference to lineage in particular). If doing such comparison sequentially, this process would have taken years to compute just for this subset of data. As such, a distributed architecture was needed.
FutureGrid provided an ideal testing platform for building such an environment necessary for this large scale data analysis. Using the Eucalyptus cloud system available on India, a specialized virtual machine (VM) was constructed with a minimal ubuntu-based image along with the necessary Bioinformatics toolkits. From here, multiple VM instances, complete with this specialized environment, were instantiated en-masse. Each VM was able to collect the necessary sequence data from the 1000 Genome's data repository at the NCBI and EBI, then each input data was reformatted to fit the BioPerl tool's desired input. From here, each VM was able to run the tools, compute where each gentic mutation occurs between the two test groups, and send the resulting output files back to a central location.
Then, we took the list of mutation consequences from the output of the program and applied them towards the data provided by the Thousand Genomes Project. A portion of the data provided a list for every individual of the populations and the presence of those mutations within their genomes. By taking the count of negative mutations overall and dividing by the total number of mutations we could determine the percentage of mutations which were detrimental. In order to determine the significance, we decided as a group to use the statistical student’s T-test. The students T-test is a statistical measure used to compare the means of two samples. In other words, it is used to determine if two sets of data can be considered "different" in a real statistical way. In this case, we compared those of the European participants and the Japanese participants. P value is what you get as a result of a student's T test. After running the student’s t-test we got a result of p=3.08848x10^-0. If the p value is below .05, then the difference between japanese and european functional mutations is statistically significant. As the results show, it is a lot smaller which indicates that the Japanese have a significantly higher likelihood of having more functional protein mutations within their genetic makeup.
European Japanese Average 10.3% 11.4% Standard Deviation 1.02% 1.31% Minimum 6.91% 7.98% Maximum 12.4% 14.8%
There are several possible reasons to explain why the rate of functional mutations is higher in the Japanese population, all dealing with evolution and populations genetics. The first possibility is that there is less migration within the Japanese population. Japan is a relatively secluded island and historically has not subject to a lot of contact or interbreeding from different populations of the world. Breeding within a population over the course of time can lead to the accumulation of deleterious mutations. The second possibility is that without strong selection there would be less reason for those detrimental mutations to be removed from the gene pool. If people can still survive and reproduce even though they have the mutation, then it will persist in the population throughout their future generations. The third possibility is that these mutations have not yet been fixed within the Japanese population. Fixation is a concept within population genetics which refers to the tendency of mutations to be removed from the gene pool over time. There are several properties of a mutation which can lead to its fixation,, like population size and heritability. The process of fixation can take a very long time which can help to explain why these mutations present in the gene pool.
Analysis of only two populations opens to the door to comparing several different populations at the same time. The data are available for Europeans, East Asians, West Africans, and Americans. Taking one step beyond our plan would be to look at the diseases or protein disorders which commonly affect each sub-population. FutureGrid has provided us with the tools necessary to evaluate these complex problems within the 1000 Genome Project and paved the way for a new computational environment that would not be possible available.
The research group have also made an educational video describin the process and work involved in the project, available at http://www.youtube.com/watch?v=nV6UyJw6oZc&feature=youtu.be
Results for Project "313. HyFlowTM"
Roberto Palmieri
Virginia Tech, Department of Electrical and Computer Engineering
Last Modified:
This is the link of the project http://www.hyflow.org/hyflow and here there are all the papers and technical reports in the context of the project: http://www.hyflow.org/hyflow/wiki/Publications
Results for Project "226. GPU Experimentation using Delta"
Andrew Younge
University of Southern California / ISI (East), Information Sciences Institute
Last Modified:
Peliminar results are currently being gathered.
Results for Project "166. Parallel watershed and hdyrodynamic models"
Meghna Babbar-Sebens
Oregon State University, Civil and Construction Engineering
Last Modified:
Tempest cluster in Future grid was used to support the work in the following publications:
1. Babbar-Sebens, M., Barr, R.C., Tedesco, L.P., Anderson, M., 2013. Spatial identification and optimization of upland wetlands in agricultural watersheds. Ecological Engineering, 52, pp. 130– 142.
Results for Project "188. Optimizing Shared Resource Contention in HPC Clusters"
Sergey Blagodurov
Simon Fraser University, School of Computing Science
Last Modified:
Accepted publications:
Tyler Dwyer, Alexandra Fedorova, Sergey Blagodurov, Mark Roth, Fabien Gaud and Jian Pei,
A Practical Method for Estimating Performance Degradation on Multicore Processors and its
Application to HPC Workloads, in Supercomputing Conference (SC), 2012. Acceptance rate 21%.
MAS rank: 51/2872 (top 2%)
http://www.sfu.ca/~sba70/files/sc12.pdf
Presented posters:
Sergey Blagodurov, Alexandra Fedorova, Fabien Hermenier, Clavis-HPC: a Multi-Objective Virtualized Scheduling Framework for HPC Clusters, in OSDI 2012.
Public software releases:
Clavis-HPC: a multi-objective virtualized scheduling framework for HPC clusters.
http://hpc-sched.cs.sfu.ca/
The source code is available for download from github repository:
https://github.com/blagodurov/clavis-hpc
Documentation:
Below is the link to our project report for the FutureGrid Project Challenge. A shorter version of it will appear in HPCS 2012 proceedings as a Work-In-Progress paper:
http://www.sfu.ca/~sba70/files/report188.pdf
A very brief outline of the problem, the framework and some preliminary results:
http://www.sfu.ca/~sba70/files/ClusterScheduling.pdf
Results for Project "18. Privacy preserving gene read mapping using hybrid cloud"
Yangyi Chen
Indiana University Bloomington, School of Informatics and Computing
Last Modified:
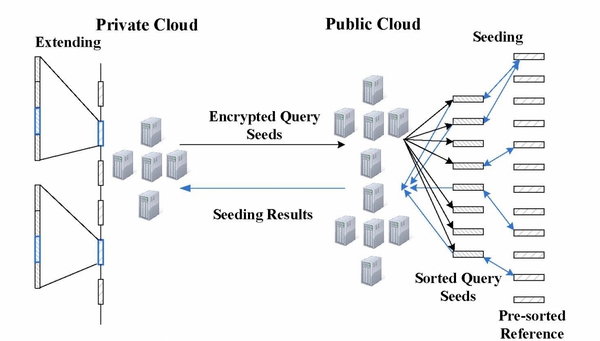
One of the most important analyses on human DNA sequences is read mapping, which aligns a large number of short DNA sequences (called reads) produced by sequencers to a reference human genome. The analysis involves intensive computation (calculating edit distances over millions upon billions of sequences) and therefore needs to be outsourced to low-cost commercial clouds. This asks for scalable privacy-preserving techniques to protect the sensitive information sequencing reads contain. Such a demand cannot be met by the existing techniques, which are either too heavyweight to sustain data-intensive computations or vulnerable to re-identification attacks. Our research, however, shows that simple solutions can be found by leveraging the special features of the mapping task, which only cares about small edit distances, and those of the cloud platform, which is designed to perform a large amount of simple, parallelizable computation. We implemented and evaluated such new techniques on a hybrid cloud platforms built on FutureGrid. In our experiments, we utilized specially-designed techniques based on the classic “seed-and-extend” method to achieve secure and scalable read mapping. The high-level design of our techniques is illustrated in the following figure: the public cloud on FutureGrid is delegated the computation over encrypted read datasets, while the private cloud directly works on the data. Our idea is to let the private cloud undertake a small amount of the workload to reduce the complexity of the computation that needs to be performed on the encrypted data, while still having the public cloud shoulder the major portion of a mapping task.
We constructed our hybrid environment over FutureGrid in the following two modes:
1. Virtual mode:
We used 20 nodes on FutureGrid as the public cloud and 1 node as the private cloud.
2. Real mode:
We used nodes on FutureGrid as the public cloud and the computing system within the School of Informatics and Computing as the private cloud. In order to get access to the all the nodes on public cloud, we copied a public SSH key shared by all the private cloud nodes to the authorized_keys files on each public cloud node.
Our experiments demonstrate that our techniques are both secure and scalable. We successfully mapped 10 million real human microbiome reads to the largest human chromosome over this hybrid cloud. The public cloud took about 15 minutes to do the seeding and the private cloud spent about 20 minutes on the extension. Over 96% of computation was securely outsourced to the public cloud.
Results for Project "1. Peer-to-peer overlay networks and applications in virtual networks and virtual clusters"
Renato Figueiredo
University of Florida, Electrical and Computer Engineering
Last Modified:
FutureGrid has been instrumental as a platform for experimental research in this project. FutureGrid allowed experiments on virtual networks based on the IP-over-P2P (IPOP) overlay and GroupVPN, the MatchTree P2P resource discovery system, and Grid appliances that would not otherwise have been feasible - with FutureGrid, graduate student researchers in this project were able to deploy in a systematic way wide-area overlays with virtual machine instances that self-organized as nodes of distributed virtual private clusters. In terms of impact, the results from the research activities in this project have been published or accepted for publication in major conferences and journals, including the High Performance Distributed and Parallel Computing (HPDC) conference, the TeraGrid/XSEDE conference, and the Future Generation Computer Systems (FGCS) journal. In addition, the experiments on FutureGrid helped in the evaluation of IPOP/GroupVPN, and led to improvements and refinements in the Grid appliance system, which have been used in other FutureGrid research and education projects, and helped solidify collaborations with international partners interested in using virtual networks (PRAGMA, Contrail) which are being pursued by UF investigators.
Results for Project "290. Open Source Cloud Computing"
Sharath S
Visvesvaraya Technological University, Computer science organization
Last Modified:
Results for Project "149. Metagenome analysis of benthic marine invertebrates"
Malcolm Zachariah
University of Utah, Department of Medicinal Chemistry, Schmidt Lab
Last Modified:
We have been able to successfully assemble the complete genome of a previously unknown endosymbiotic bacterium from metagenomic sequence data obtained from a marine invertebrate (even though the bacterium only accounted for ~0.6% of the data). The complete genome afforded many insights into the symbiotic relationship, which we have reported in a paper published in Proceedings of the National Academy of Sciences. The insights gained in this effort have allowed us to develop new methods in data processing and assembly which we are currently refining and will be the subject of future publications. We will continue to use Future Grid in these efforts to gain insight into other symbiotic systems. The scientific broad impact of this work is twofold. First, these symbiotic relationships are a key, yet poorly understood aspect of coral reef biodiversity. Second, these symbioses lead to the production of bioactive small molecules. By understanding the origin of compounds, we are developing new methods to tap biodiversity for potential application in medicine, agriculture, and other areas.
Results for Project "42. SAGA"
Shantenu Jha
Louisiana State University, Center for Computation & Technology
Last Modified:
Interoperable and Standards-based Distributed Cyberinfrastructure and Applications
Abstract:
Advances in many areas of science and scientific computing are predicated on rapid progress in fundamentalcomputer science and cyberinfrastructure, as well as their successful uptake by computational scientists. Thescope, scale and variety of distributed computing infrastructures (DCIs) currently available to Scientists andCS researchers is both an opportunity, and a challenge. DCI present an opportunity, as they can support theneeds of a vast range and number of science requirements and usage-modes. The design and implementationof DCI itself present a formidable intellectual challenge, not least because of the challenges in providinginteroperable tools and applications given the heterogeneity and diversity of DCIs.
Interoperability - standards based as well as otherwise, is an important necessary (though not sufficientcondition) system and application feature for the effective use of DCI and its scalability. This project reportpresents a selection of results from Project No. 42 (SAGA) which makes use of FutureGrid to developthe software components, runtime frameworks and to test and verify their usage, as well as initial e orts inincorporating these strands into Graduate curriculum. Specially, we discuss our work on P* - a model forpilot abstractions, and related implementations which demonstrate (amongst others) interoperability betweendifferent pilot-job frameworks. In addition to the practical benefits interoperable and extensible pilot-job framework, P* provides a fundamental shift in the state-of-the-art of tool development: for the first timethat we are aware, thanks to P* there now exists a theoretical and conceptual basis upon which to build thetools and runtime systems. We also discuss standards based approaches to software interoperability, and therelated development challenges { including SAGA as a standards based generic access layer to DCIs. Finally,we conclude by establishing how these strands have been brought together in a Graduate Classroom.
The full version of the report is available here.
Results for Project "280. Use of Eucalyptus,Open Nebula"
Sharath S
Visvesvaraya Technological University, Computer science organization
Last Modified:
Project shows management of Virtual macines.Vitual machines created contains user required softwares.
Results for Project "284. Class Assignment: Map Reduce Comparison"
Hang Li
University of Southern California, Electrical Engineering
Last Modified:
The students will most likely use Hotel and india
So far one student of the class has contacted us. All other students will join this project.
Results for Project "141. High Performance Spatial Data Warehouse over MapReduce"
Fusheng Wang
Emory University, Center for Comprehensive Informatics
Last Modified:
1. We have provided scalability testing on the futuregrid platform with 320 cores based on Hadoop. A technique report has been published:
http://confluence.cci.emory.edu:8090/confluence/download/attachments/4033450/CCI-TR-2012-5.pdf?version=1&modificationDate=1341865395000
We are also working on two papers based on the project.
2. We have developed an open source system Hadoop-GIS by extending Apache Hive project with spatial querying capabilities. The URL is:
http://web.cci.emory.edu/confluence/display/HadoopGIS
Results for Project "261. Investigation of Data Locality and Fairness in MapReduce"
Zhenhua Guo
Indiana University, Pervasive Technology Institute
Last Modified:
Our experiment results show that our proposed algorithms improve data locality and outperform the default Hadoop scheduling substantially. For example, the ratio of data-local tasks is increased by 12% - 14% and the cost of data movement is reduced by up to 90%.
The detailed results of this project have been presented in two papers: "Investigation of data locality and fairness in MapReduce" [bib]Guo:2012:IDL:2287016.2287022[/bib], and "Investigation of Data Locality in MapReduce" [bib]fg-261-05-2012-a[/bib].
Results for Project "71. Course: B649 Topics on Systems Graduate Cloud Computing Class"
Judy Qiu
Indiana University, School of Informatics and Computing
Last Modified:
See class web page http://salsahpc.indiana.edu/b649/
This class involved 27 Graduate students with a mix of Masters and PhD students and was offered fall 2010 as part of Indiana University Computer Science program. Many current FutureGrid experts went to this class which routinely used FutureGrid for student projects. Projects included
Hadoop
DryadLINQ/Dryad
Twister
Eucalyptus
Nimbus
Sector/Sphere
Virtual Appliances
Cloud Storage
Clustering by Deterministic Annealing (DAC)
Multi Dimensional Scaling (MDS)
Latent Dirichlet Allocation (LDA)
Results for Project "175. GridProphet, A workflow execution time prediction system for the Grid"
Thomas Fahringer
University of Innsbruck, Institute of Informatics
Last Modified:
Project brief:This project was initiated as part of a larger project titled “A provenance and performance prediction system for Grid systems”. The objective of the main project is to develop a grid performance prediction system, which can estimate the execution time of individual workflow tasks, single-entry-single-exit sub-workflows (e.g. loops), and entire workflows for scientific applications such that the prediction technology can be used to rank different workflow transformations or workflow versions with respect to their execution time behavior. The proposed system can be used for optimization of workflow applications, thus enabling scientists to better utilize computing resources and reach their scientific results in shorter time.
The objective of the utilization of Future Grid resources was to collect trace data for training the machine learning systems. The data collected using the Future Grid resources is used along with the data traces collected in the Austrian Grid and the Grid5000.
Experimental setup:
Grid-Appliance provided by Future Grid portal is used in varying configuration to setup the Virtual Grid required to serve the project objective.
Based on the project requirements trace collection was to be performed for the following applications.
- MeteoAG (Meteorology Domain)
- Wien2K (Material Science Domain)
- InvMod (Alpin River Modeling)
The goal was to record trace collection data for atleast 5000 workflow runs in total with varying background load and dynamic distribution of tasks on different sites in the virtual Grid.For this purpose the Grid-Appliance was customized in different aspects. Additional software packages were added required for the execution of the workflow execution system (ASKALON) and the workflows themselves. A database server was installed to collect the trace data during the experiments.
Trace Data:
A set of key features having noticeable importance during the execution of these workflows on the Grid infrastructure was identified. These selected features covered most of the factors associated to Grid workflow execution such as input to the application workflow, size of the input data, size of application executables, Network associated features like available bandwidth, bandwidth background load, time required to transfer the application data across computer nodes. Moreover both the dynamic and static environment associated parameters are also collected which include the information about the machine architecture, compute power, cache memory and disk space etc. A total number of 65 parameters are selected for use to get accurate predictions and for a rich machine learning based training of the prediction model.
Optimization of the Feature Vectors:
For use with the machine learning system the main feature vector is shortlisted to select a small number of parameters, so that the machine learning process can be carried out swiftly and accurately. Having a large number of input parameters results in very long training times and also introduces lots of noise in the data.
We recorded a large number of run-time parameters so as not to miss any important feature. But for the training of the model we needed to optimize the feature space so that the problems associated with the noise and long training durations can be avoided. Principal component analysis and Principal Feature selection algorithms are used for optimization of the feature space and an optimized feature vector is generated that have maximum influence on the execution of the tasks in distributed environments.
Utilization of Trace Data:
A neural network based machine learning system known as Multilayer Perceptron (MLP) is used. MLP is a Feedforward neural network system for training machine learning models and is used for pattern matching in non linear problem spaces. It maps the sets of inputs presented at the input layers of the network to outputs at the output layer. In contrast to the traditional neural networks MLP may have one or more hidden layers. An activation function determines the threshold value of the network at each node which acts a neuron for the neural network.
For our experiments the trace data collected from the Future Grid infrastructure was used along-with the data collected from other Grid infrastructures like that of Austrian Grid and the Grid5000.
The training results presented herewith are therefore not specific to Future Grid only.
Performance Prediction Results:
Based on our experiments and the machine learning system described above the following activity level predictions accuracy has been achieved.
Workflow: Wien2kTotal successful runs: 700One activity maximum prediction accuracy: 65.70%Two activities maximum prediction accuracy: 52.70%
Single workflow prediction accuracy
The results presented above are quite promising for an initial investigation and therefore we are quite eager to continue this research to get even better results. Experimental workflow runs are in progress using the Future Grid resources to have more trace data for improved performance prediction accuracy.
Results for Project "62. Evaluation of using XD TAS (Technology Auditing Service) in FutureGrid"
Charng-Da Lu
SUNY, SUNY
Last Modified:
We have been running application kernels on FG systems for the past two years and we have collected their performance data, which can be viewed at XDMoD website (http://xdmod.ccr.buffalo.edu). We plan to continue running (and expanding) our set of application kernels and analyze the cause of performance fluctuations.
Results for Project "185. Co-Resident Watermarking"
Adam Bates
University of Oregon, CIS Department, OSIRIS Lab
Last Modified:
Our use of Futuregrid led to an accepted paper at the 2012 ACM Cloud Computing Security Workshop entitled "Detecting Co-Residency with Active Traffic Analysis Techniques". This work will be presented on 19 October, 2012. Futuregrid is featured in the acknowledgements section. A copy of the paper is available at:
http://ix.cs.uoregon.edu/~amb/documents/Bates_Ccsw12.pdf
Results for Project "238. HPC meets Clouds"
Li Chunyan
YunNan University, High Performance Computing Center
Last Modified:
Hello,FutureGrid:
Firstly,We are very grateful to you that you provide a very good test-bed for us.
Secondly,We have do some experiments including testing hpc and some cloud IaaS.Meanwhile,we also have analysed performance about that.We just start to study several days because that we join the futuregrid family is late.
In the end,I report our using resources,including HPC,openstake,nimbus,opennebula,hadoop and so on.
Besides,We are already preparing for a publication.
Results for Project "118. Testing new paradigms for biomolecular simulation"
Peter Kasson
University of Virginia, Departments of Molecular Physiology and of Biomedical Engineering
Last Modified:
The first papers on this project have been submitted; references and details will be provided upon publication.
Results for Project "264. Course: 1st Workshop on bioKepler Tools and Its Applications "
Ilkay Altintas
UCSD, SDSC
Last Modified:
The workshop went well with the virtual instances with a few hiccups. As Koji suggested, I tried to start instances one or two days before the workshop. I met a few kinds of errors (one returns error message directly after the start-instance command, another shows the instance status is error and I cannot login). In the end, I was able to start 28 instances and can access every instance. The instances kept running correctly in the first morning of the workshop. Yet suddenly, all my instances are gone around lunch time. So in the afternoon, I restarted 24 instances. I didn't see any error. This time, I didn't get enough time to test all instances. During the hands-on session the afternoon of the second day (Yesterday), I let attendees to access the instances. Quite a few (around five) cannot ssh into their instances. The instances show correct public IP address but ssh shows no route to reach them. I had to let some members of our host team to give their instances for other attendees. The good thing is that all instances that we can access work well throughout the afternoon session.
A list of attendees can be found at http://swat.sdsc.edu/biokepler/workshops/2012-sep#info.
Results for Project "27. Evaluation of Hadoop for IO-intensive applications"
Zhenhua Guo
Indiana University, Pervasive Technology Institute
Last Modified:
The results are presented in detail in the file http://archive.futuregrid.org/sites/default/files/HadoopEvaluationResults.pdf.
Results for Project "260. Improve resource utilization in MapReduce"
Zhenhua Guo
Indiana University, Pervasive Technology Institute
Last Modified:
We ran CPU-, IO-, and network-intensive applications to evaluate our algorithms. The results show resource stealing can achieve higher resource utilization and thus reduce job run time. Our BASE optimization reduces the number of non-beneficial speculative tasks significantly without incurring performance degradation.
The detailed results of this project are presented in our paper "Improving Resource Utilization in MapReduce" [bib]ResStealAndBASE[/bib].
Results for Project "216. Scaling-out CloudBLAST: Deploying Elastic MapReduce across Geographically Distributed Virtulized Resources for BLAST"
Andrea Matsunaga
University of Florida, ECE/ACIS
Last Modified:
The overall integration of technologies has been described in http://escience2008.iu.edu/sessions/cloudBlast.shtml. It also presents the low overhead imposed by the various technologies (machine virtualization, network virtualization) utilized, the advantages using a MapReduce framework for application parallelization over traditional MPI techniques in terms of performance and fault-tolerance, and the extensions to Hadoop required to integrate an application like the NCBI BLAST.
Challenges to the network virtualization technologies to enable inter-cloud communication, and a solution to overcome them called TinyVine is presented in http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5380884. A comparative analysis of existing solutions addressing sky computing requirements is presented along with experimental results that indicates negligible overhead for embarrassingly parallel applications such as CloudBLAST, and low overhead for network intensive applications such as secure copy of files.
In the largest experiment using FutureGrid (3 sites) and Grid’5000 (3 sites) resources, a virtual cluster of 750 VMs (1500 cores) connected through ViNe/TinyViNe was able to execute CloudBLAST achieving speedup of 870X. To better handle the heterogeneous performance of resources, an approach that skews the distribution of MapReduce tasks was shown to improve overall performance of a large BLAST job using FutureGrid resources managed by Nimbus (3 sites). Both results can be found in http://www.booksonline.iospress.nl/Content/View.aspx?piid=21410.
Table 1. Performance of BLASTX on sky-computing environments. Speedup is computed as the time to execute a BLAST search sequentially divided by the time to execute using the cloud resources. A computation that would require 250 hours if executed sequentially, can be reduced to tens of minutes using sky computing.
Experiment Number of Clouds Total VMs Total Cores Speedup 1 3 32 64 52 2 5 150 300 258 3 3 330 660 502 4 6 750 1500 870
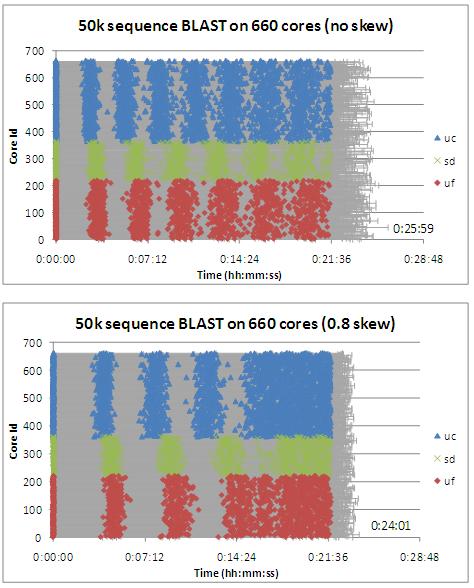
Figure 1: Comparison of executions of a 50000-sequence BLAST job divided into 256 tasks with (a) uniform or (b) skewed sizes on 660 processors across 3 different sites (University of Chicago, University of Florida, and San Diego Supercomputing Center). The progress of time is shown in the horizontal axis and the vertical axis represents each of the 660 individual workers. In this particular setup, the overall time perceived by the end user when running with skewed tasks is 8% shorter than when running with uniform tasks.


Results for Project "133. Supply Chain Network Simulator Using Cloud Computing"
Manuel Rossetti
University of Arkansas, Department of Industrial Engineering
Last Modified:
Supply Chain Network Simulator Using Cloud Computing
Project #: FG-133
Abstract:
Large-scale supply chains usually consist of thousands of stock keep units (SKUs) stocked at different locations within the supply chain. The simulation of large-scale multi-echelon supply chain networks is very time consuming. The purpose of this project is to design a cloud computing architecture to facilitate the computational performance of large scale supply chain network simulations. A Cloud Computing Architecture For Supply Chain Network Simulation (CCAFSCNS) was designed in this project, and a prototype system was developed using the computing resources in the FutureGrid. The simulations are essentially compute-intensive Monte-Carlo experiments requiring multiple replications. Replications are distributed across virtual machines within CCAFSCNS. The results show that the cloud computing solution can significantly shorten the simulation time.
Resources used in this project (which are related to FutureGrid):
1. Virtual Machine: Grid Appliance
2. Hardware Systems: Alamo Network
3. Service Access: Nimbus Cloud Client
Completed Work:
1. Customized the Grid Appliance to be Condor Server, Condor Worker and Condor Client.
2. Designed a Cloud Computing Architecture For Supply Chain Network Simulation (CCAFSCNS).
3. Developed a prototype system that implemented the CCAFSCNS with Excel, Access, Spring Framework, supply chain network simulator, FutureGrid, the Condor System, and the Grid Appliance. The virtual machines (VMs) of the Condor Worker, which is customized based on the Grid Appliance, are started in the Alamo network. These VMs are the computing resources used in the prototype system to run simulation jobs.
4. Did a computational time study on the cloud computing solution based on FutureGird:
a. Analyzed the time components used in the cloud computing solution
b. Estimated the scheduling time for a simulation request
c. Compared the simulation time spent on traditional solution and cloud computing solution and showed that the cloud computing solution can save 70% of the simulation time.
Achievements/Publications:
1. One Master project report has been submitted to fulfill the requirement for the degree of Master of Science.
2. One conference paper has been submitted to the 2012 Winter Simulation Conference.
Broader Impacts:
A Cloud Computing application capable of evaluating the performance of multi-echelon supply networks through simulation is developed in this project. This application includes a web application that can run the simulation from the cloud and a database application that helps users develop the input data and analyze the output data. Companies will be able to use the results to develop better systems and software products that rely on cloud computing for applications involving this use case. In addition, the cloud computing architecture designed in this project can be used to develop other cloud computing solutions. Also, educational materials, such as the tutorials of building the Condor System, are developed to provide how-to knowledge for other researchers and industry collaborators.
Results for Project "120. Workshop: A Cloud View on Computing"
Jerome Mitchell
PTI, Indiana University
Last Modified:
The hands-on workshop was June 6-10, 2011. Participants were immersed in a “MapReduce boot camp”, where ADMI faulty members sought introduction to the MapReduce programming framework. The following were themes for five boot camp sessions:
- Introduction to parallel and distributed processing
- From functional programming to MapReduce and the Google File System (GFS)
- “Hello World” MapReduce Lab
- Graph Algorithms with MapReduce
- Information Retrieval with MapReduce
An overview of parallel and distributed processing provided a transition into the abstractions of functional programming, which introduces the context of MapReduce along with its distributed file system. Lectures focused on specific case studies of MapReduce, such as graph analysis and information retrieval. The workshop concluded with a programming exercise (PageRank or All-Pairs problem) to ensure faculty members have a substantial knowledge of MapReduce concepts and the Twister/Hadoop API.
For more information, please visit http://salsahpc.indiana.edu/admicloudyviewworkshop/
Results for Project "203. Compression on GPUs"
Adnan Ozsoy
Indiana University Bloomington, School of Informatics
Last Modified:
The previous work has been published and the title of the paper is "CULZSS: LZSS Lossless Data Compression on CUDA". The project will be future improvement work.
Results for Project "198. XSEDE Campus Bridging Rocks Roll testing"
Richard Knepper
Indiana University, Research Technologies Campus Bridging
Last Modified:
results will be software installation packages that work -- when we have some, I'll link to them here.
Results for Project "54. Investigating cloud computing as a solution for analyzing particle physics data"
Randall Sobie
University of Victoria, Physics
Last Modified:
Results for Project "95. Comparision of Network Emulation Methods"
David Hancock
Indiana University, UITS - Research Technologies
Last Modified:
The experiment consisted of host-to-host Iperf TCP performance while increasing parallel streams and inducing RTT latency utilizing FutureGrid's Spirent XGEM Network Impairments device. The hosts were two IBM x3650's with Broadcom NetExtreme II BCM57710 NIC's. RedHat release 5.5 Linux distribution was installed on each host, keeping stock kernel tuning in place. An ethernet (eth0) interface on each host was connected back-to-back while the second ethernet (eth1) passed through the Spirent XGEM and Nexus 7018 using an untagged VLAN, as illustrated in the attached diagram.
The direct host-to-host link saw an average delay of .040 ms while the path through the XGEM (.004 ms) and Nexus (.026 ms) was .080 ms.
Dual five minute unidirectional TCP Iperf tests were conducted, one each across the direct and switched path. Tests were initiated independently and occurred at approximately the same start time with a deviation of +/- 3 seconds initiation. Results were gathered for each direct (D) and switched (S) test. Follow-up tests were executed increasing the number of parallel streams Iperf (command line option -P) could transmit. The number of streams included single, sixteen, thirty-two, sixty-four and ninety-six. Delay was added via the Spirent at increments of default (.080 ms), 4.00 ms, 8.00 ms, 16.00 ms, 32.00 ms, 64.00 ms, 96.00 ms and 128.00 ms RTT. The matrix yielded forty data points. Additionally the experiments were repeated utilizing two different kernel tuning profiles, increasing the data points to 80 and 120. The data points and graph (only switched path) show that as delay increased overall TCP performance increased as the number of parallel threads were increased.
Detailed results can be found in the attached text and excel files.

Results for Project "174. RAIN: FutureGrid Dynamic provisioning Framework"
Gregor von Laszewski
Indiana University, Community Grids Laboratory
Last Modified:
fg-1280 fg-1295 fg-1270 fg-1241
Results for Project "2. Deploy OpenNebula on FutureGrid"
Gregor von Laszewski
Indiana University, Community Grids Laboratory
Last Modified:
At this time we do have a small OpenNebula cloud installed internally for the FG software Group. This Group uses this cloud as part of the image management.
Presentations:
fg-1280
Results for Project "170. European Middleware Initiative (EMI)"
Morris Riedel
Juelich Supercomputing Centre, Federated Systems and Data
Last Modified:
* FutureGrid provides its users access to European middleware services out of the EMI releases * Permanent endpoints of EMI products * Tutorial material for the installed EMI products in order to organize tutorial sessions * Interoperability checks with other existing software stacks in FutureGrid * Integration checks whether EMI products can actually work in virtualized environments such as provided by FutureGrid * Several scientific case studies that explore the possibility of using FutureGrid for feasibility studies before large-scale production runs elsewhere * at least one publication per year indicating the use of FutureGrid resources with the EMI products * EMI Webpage part that reports about FutureGrid and its EMI activities
Results for Project "80. Genesis II testing"
Andrew Grimshaw
University of Virginia, Computer Science
Last Modified:
Genesis II scale testing is being performed in the context of the Cross-Campus Grid (XCG), which brings together resources from around Grounds as well as at FutureGrid. The XCG provides access to a variety of heterogeneous resources (clusters of various sizes, individual parallel computers, and even a few desktop computers) through a standard interface, thus leveraging UVa’s investment in hardware and making it possible for large-scale high-throughput simulations to be run. Genesis II, a software system developed at the University by Prof. Andrew Grimshaw of the Computer Science Department and his group, implements the XCG. Genesis II is the first integrated implementation of the standards and profiles coming out of the Open Grid Forum (the standards organization for Grids) Open Grid Service Architecture Working Group.
The XCG is used across a variety of disciplines at UVA, including Economics, Biology, Engineering, and Physics. The services offered by the XCG provide users with faster results and greater ability to share data. By using the XCG, a researcher can run multiple jobs tens to hundreds of times faster than would be possible with a single desktop. The XCG also shares or “exports” data. Local users and XCG users can manipulate the exported data. Through the XCG we also participate in projects supported by the National Science Foundation’s XD (extreme digital) program for supercomputing initiatives.
Results for Project "79. XSEDE system software testing"
Andrew Grimshaw
University of Virginia, Computer Science
Last Modified:
XSEDE software testing on FutureGrid began in earnest mid-October 2011. The work built upon our earlier Genesis II testing and Genesis II/UNIOCRE 6 interoperation testing projects on FutureGrid. Accounts for XSEDE staff have been provided, and enhanced permission for a UNICORE 6 service on each of Alamo, India, Sierra, and X-Ray has been provided. While the testing process is still in progress FutureGrid has been an invaluable resource for the XSEDE testing team. XSEDE-specific UNICORE 6 endpoints have been deployed and tested on India, Sierra, and X-ray, and called by a Genesis II meta-scheduler (grid queue) running at UVA. Similarly Genesis II endpoints have been deployed on India and Alamo for Global Federated File System (GFFS) testing.
The FutureGrid system adminsitrators have been most helpful in this process.
Results for Project "157. Resource provisioning for e-Science environments"
Andrea Bosin
University of Cagliari, Department of Mathematics and Computer Science
Last Modified:
0. Environment inspection
Eucalyptus environment tested, identified a working set of
(image, kernel, ramdisk), inspection of a running VM instance
to extrapolate underlying configuration (virtual devices, kernel
and kernel modules) for subsequent custom image setup
1. VM setup
Setup and deployed custom VM images
- VM for publishing a Java web service: JRE and web service are
dynamically downloaded and executed immediately after boot; a
start-up script is in charge of downloading the web service
configuration from a public URL
- VM for publishing an Apache ODE workflow engine (deployed inside an
Apache Tomcat container) and a supervisor web service; a
start-up script is in charge of downloading the workflows (BPEL
processes) to be deployed into the engine; the supervisor service
is in charge of downloading workflow input from a public URL and
enacting one or more workflow instances
2. VM test
Deployed VM images have been manually instantiated to verify the correct
behavior of start-up scripts
3. Programmatic VM interaction
Programmatic VM instance creation and termination has been
successfully achieved through the EC2 APIs by means of the jclouds
library
Results for Project "26. Bioinformatics and Clouds"
John Conery
University of Oregon, Center for Ecology and Evolutionary Biology
Last Modified:
The goal for our project was to give systems adminstrators and bioinformatics researchers at the University of Oregon some experience with provisioning and launching virtual machines in a cloud computing environment in preparation for our transition to a private cloud to be set up here on campus.
Our group members have been moderately successful. All were able to run the FutureGrid tutorial and learn how to launch a VM and log into it once it was running. A few were able to get beyond that step, uploading QIIME and other VM images. One member reported success with installing software, but found the latency too high to run any sort of interactive software. Interest in using FG began to wane as (a) we decided to use OpenStack instead of Eucalyptus or Nimbus and (b) more of our systems administrators time needed to be directed toward installing and configuring our system.
Overall this has been a very positive experience, and many of the ideas behind how the FG portal is structured will influence how we try to manage the user experience here. I would like to keep this project going and continue to use it as a "sandbox" for new students and potentially for some of the research I plan to work on in the near future.
Results for Project "78. Exploring VMs for Open Science Grid Services "
Scott Teige
Open Science Grid, Fermilab
Last Modified:
The Open Science Grid Operations Center runs several services
enabling users to locate resources and generally use the OSG.
With this project we have investigated the possibility of
virtualizing the few remaining components that are not already
available as virtual machines. In particular, we have built a
"Compute Element", a basic resource unit for the OSG. Currently,
there are a few small technical details to work out. Eventually,
we intend to demonstrate a usable Compute Element integrated
into the usual list of OSG resources.
Results for Project "122. Course: Cloud computing class"
Massimo Canonico
University of Piemonte Orientale, Computer Science Department
Last Modified:
This project is providing various materials for the "Community Educational Material" section in the future grid portal.
At this link, you can find documents, hand-outs, outline and more concerning the "Cloud Computing Class" that
I'm teaching with students from different Universities and companies in the Italy.
Results for Project "50. Performance evaluation of MapReduce applications"
Yunhee Kang
Indiana University, PTI
Last Modified:
Extended Abstract : Performance evaluation of MapReduce applications
Yunhi Kang
Pervasive Technology Institute at IU
Bloomington, IN
e-mail: yunh.kang@gmail.com
Abstract
The purpose of this project is focused on evaluating performance of two kinds of MapReduce applications: a data intensive application and a computational intensive application. For this work, we construct a virtualized cluster systems made of the VM instances for experiments in the FutureGrid. What we have observed in the experiments is that the overall performance of a data intensive application is strongly affected by the throughput of the messaging middleware since it is required to transfer data in a map task and a reduce task. However the performance of computational intensive application is associated with CPU throughput. We have investigated the performance of these MapReduce applications on Future Grid and have done detailed performance variation studies. The results of this experiment can be used for selecting the proper configuration instances in the FutureGrid. It can be used to identify the bottleneck of the MapReduce application running on the virtualized cluster system with various VM configurations. We conclude that performance evaluation according to the type of specific application is essential to choose properly a set of instances in the FutureGrid.
I. Overview of experiment
A. Experiment Environment
In this experiment, a virtualized cluster system composed of a group of an instance is allocated from india cluster, which is one of FuturGrid environments. Each instance provides a predictable amount of dedicated compute capacity that is defined in FutureGrid. The following instance types are used to the experiments:
· c1-medium
· m1-large
· m1-xlarge
We make a configuration for a virtualized cluster system as tested and use various configurations that are used to evaluate performance of two types of a MapReduce application. A configuration has various middleware setups. It is used to represent two different workloads. For example, sim-c1-ml represents an unbalanced load allocation and sim-2-ml represents a balanced load allocation.
The MapReduce application is implemented on a system using:
· Twister 0.8
· Naradabroker 4.2.2
· Linux 2.6.x running on Xen
Before diving into the MapReduce algorithm, we set up virtualized cluster systems of the cloud architecture. To set up the virtualized cluster systems, we deploy images and run the instances. We use a Linux command top that provides a dynamic real-time view of a running system, including information about system resource usage and a constantly updated list of the processes which are consuming the most resources. This can be one of the most useful ways to monitor the system as it shows several key statistics. We set the top command as batch mode, 1 sec. update and 1000 samples to monitor resource usage. By using a tool, top we get the trace of memory and load average while a MapReduce application is running in a specific VM environment.
B. Restrictions of the experiment
This experiment is a micro-level evaluation that is focused on the nodes provided and the application running on them.
· The applications of which are used in the experiment follow a MapReduce programming model
· With regard to this experiment, resource allocation considers in a static way that means how to select computing resources to optimize a MapReduce application running on the nodes
· Performance evaluation is based on the samples, representing a system snapshot of the work system, collected from a command top while a MapReduce application is running
II. Experiment: Data intensive Application
In this experiment, two different computing environments are evaluated, which are running a data intensive application written in MapReduce programming modeling with various configurations: one is a cluster system composed of real machines and the other is a virtualized cluster computing system. For this work, we construct a MapReduce application is used to transforms a data set collected from a music radio site, Last.fm(http://www.last.fm/) that provide the metadata for an artist includes biography by API, on the Internet. The goal program is to histogram the counts referred by musicians and to construct a bi-directed graph based on similarity value between musicians in the data set.
We compare both environments with application’s performance metrics in terms of elapse time and standard variation. The graph in Figure 1 deals with the results using the MapReduce application. In the part of the graph, sim-c1-m1-1 to type sim-2-ml, we see that as the resources of VMs including CPU and memory increase, the elapse time of the application and the value of its standard variation decreases. What we observe that the number of CPUs has less impact on the elapse time in comparison to the results of sim-c1-m1-2 and sim-2-m1. Though performance degrades as the application runs in the virtualization environment, the performance of sim-2-ml still provides 80.9% of the average performance of sim-gf14-fg15 and sim-india when running the real computing environment. However the elapse time of type sim-2-ml is 98.6 % of the elapse time of sim-fg14-fg15.
Figure 1. Elapse time of similarity: 6 configurations - Cluster system(3 types) and Virtualized cluster system(2 types)
Figures 2 and 3 show the load averages as the program runs on different middleware configurations even if those computing resources have the same configuration computing resource that consists of 1 c1-medium and 1 m1-large. We consider two middleware configurations: one is the message broker is run in the node (194) typed with c1-medim. Other is run in the node (196) type m1-medim. As shown in Figures 2 and 3, the overall workload of sim-c1-ml-2 is less than one of sim-c1-m1-2. In sim-c1-m1-1, the average number of running processes is 3.24 and its maximum number of running process is 4.97. The figure 2 shows the node has been overloaded 224% during the application running time. On the other hand, the average number of running processes is 0.80 and its maximum number of running process is 4.97 in sim-c1-m1-2. During the running time (342sec), the CPU was underloaded 20%.
According to this result, performance of a virtualized cluster system is affected by the middleware configuration depends on the location of the message broker that send and receive the message to/from application. The gap of performance is caused by CPU and memory capability of the node running the message broker. What we have observed is that the application is more I/O oriented job that needs more memory than CPU power. We can expect more high throughput when the node typed with c1-medium may be replaced with other node typed with m1-large.
Figure 2. Load average of sim-c1-m1-1(NB running on the node typed with c1-medium)
Figure 3. Load average of sim-c1-m1-2(NB running on the node typed with m1-medium)
III. Experiment: Computation intensive application
To do performance evaluation of a MapReduce application typed computation intensive, one configuration, xlarge, is added to the testbed. In this experiment, we use k-means algorithm with 100,000 data points, which is to organize these points into k clusters. We compare both environments, a virtual cluster computing system and a cluster system, with application’s performance metrics in terms of elapse time and standard variation. Figure 4 shows the elapse time of k-means. Our experiment indicates that the average elapse time can increase by over 375.5% in virtualized cluster computing system, in comparison with cluster system, india. Besides the elapse time decreases proportional as VM’s CPU capability is added to the virtualized cluster computing system. Furthermore the standard deviation is less affected by configuration change and the size of input data. In the real cluster system, the value remains very low at about 1-2% of the variation of elapse time due to the capability of system mainly related with CPU power. In addition, the standard variation in the three configurations of the virtualized cluster computing system remains low at about 2.0-3.78%. A similar trend is observed by in the values of standard deviation of all configurations. Hence we can expect that as the number of available VMs increases, there is a proportional improvement of elapse time.
Figure 4. Elapse time of k-means: 6 configurations - Cluster system(4 types) and Virtualized cluster system(1 types)
IV. Summary of the experiments
In summary, performance evaluation based on the metrics, load average and memory/swap area usage, according to the type of specific application is essential to choose properly a set of instances in the FutureGrid. Based on the performance evaluation we may choose the configuration of a virtualized cluster system to provide 80% of performance of a real cluster system.
· The performance of the application running on the Twister strongly depends on the throughput of a message broker, Naradabroker.
· The pending of the application is caused by broken pipe between a Twister daemon and a Naradabroker server when Naradabroker has a threshold of the limitation to accept a connection from Twister due to its QoS requirement.
· The capability of Naradabroker in the middleware configuration affects the performance of an application as the application runs in the same configuration computing resource.
The paper entitled "Performance Evaluation of MapReduce applications on Cloud Computing Environment, FutureGrid" is accepted in the conference GDC 2011 that will be held in Jeju, KOREA on December 8-10. This paper is partial fulfillment of this FutureGrid Project.
Acknowledgement


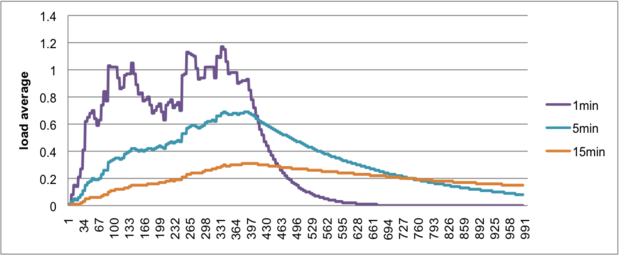

Results for Project "4. Word Sense Disambiguation for Web 2.0 Data"
Jonathan Klinginsmith
Indiana University, School of Informatics
Last Modified:
Using this project we realized there was a gap in researchers creating reproducible eScience experiments in the cloud. So, the research shifted to tackle this problem. Towards this goal, we had a paper accepted to the 3rd IEEE International Conference on Cloud Computing Science and Technology titled "Towards Reproducible eScience in the Cloud."
(http://www.ds.unipi.gr/cloudcom2011/program/accepted-papers.html).
In this work, we demonstrated the following:
- The construction of scalable computing environments into two distinct layers: (1) the infrastructure layer and (2) the software layer.
- A demonstration through this separation of concerns that the installation and configuration operations performed within the software layer can be re-used in separate clouds.
- The creation of two distinct types of computational clusters, utilizing the framework.
- Two fully reproducible eScience experiments built on top of the framework.
Results for Project "17. Comparison of MapReduce Systems"
Judy Qiu
Indiana University, School of Informatics and Computing
Last Modified:
We started a project that evaluate latest version of DryadLINQ founded by MS in December 2010.
We evaluated the programmability and performance of DryadLINQ CTP for data intensive applications in HPC cluster.
The solid results include:
1) Technical report about DryadLINQ CTP Evaluation in July 2011
2) Technical paper in DataCloud-SC11 in Nov 2011
Note: we do not use FG resources this time. We would like to evaluate Dryad cluster when they are available on FutureGrid.
Results for Project "31. Integrating High Performance Computing in Research and Education for Simulation, Visualization and RealTime Prediction"
Anthony Chronopoulos
Unvirsity of Texas San Antonio, Department of Computer Sicence
Last Modified:
No results have been obtained.
We struggled for some time to get learn.
Then, we succeeded to build a virtual cluster using nimbus on hotel cluster but we got stuck afterwards because we could not run our (C++, MPI) program because we could not write the job-script correctly. Just to mention that
we have correct job-scripts for running on TACC (ranger). Somehow we could
write the job-script for the virtual cluster on hotel cloud cluster.
We tried to obtain help from the futuregrid-help but their advice did not help us enough
to resolve this.
Results for Project "116. HPC Scheduling"
Kenneth Yoshimoto
UCSD, SDSC
Last Modified:
Topology scheduling: To support 3d-torus switch clusters, such as the SDSC Gordon cluster,
topology-aware scheduling code was added to the Catalina Scheduler http://www.sdsc.edu/catalina.
When the relationship of nodes to each other, rather than simply individual node attributes,
affects job performance, it becomes necessary to generate schedules using relationship information.
A method to do this for arbitrary switch topologies was added to Catalina Scheduler. The Futuregrid
Nimbus capability was used to create virtual clusters for scheduler development and testing.
Without this facility, this development effort would not have been possible.
This will allow more efficient resource allocation of resources to jobs, depending on job switch requirements.
Virtual Machine Scheduling: Use of Virtual Machines in batch systems to increase scheduling
flexibility has been proposed by others. With the goal of developing a prototype system
capable of doing this, existing OpenNebula facilities were used to start development of
a SLURM-based http://www.schedmd.com VM scheduling system, with suspend/resume
and migrate capabilities. Because we needed access to low-level OpenNebula functions,
Futuregrid very graciously accomodated us with direct access to compute resources.
Using these resources, we were able to develop the system to the point where SLURM
and a prototype external scheduler are able to convert a job script to a set of OpenNebula
VM machine specifications and start the job with those VMs.
Results for Project "113. End-to-end Optimization of Data Transfer Throughput over Wide-area High-speed Networks"
Tevfik Kosar
University at Buffalo, Computer Science and Engineering
Last Modified:
1 PRELIMINARY RESULTS
The End-to-end(E2E) data transfer tool is implemented by using the models and algorithms that we have proposed in our previous study [1] The tool is able to find the actual data transfer capacity of a high-speed network through optimization. The end-system capacities are taken into account and additional nodes of a cluster is used when necessary. The underlying transfer protocol used is GridFTP. The preliminary results we present in this report shows us the throughput gain between the clusters sierra(SDSC) and india(IU). 16 nodes are allocated for the transfer and only memory-to-memory transfer tests are conducted. In each case the data sampling size is increased between the range 2GB-16GB.
Figure 1, shows the throughput measurements of the data transfers that is done by the E2E data transfer tool. In the left figure, GridFTP parallel stream transfers are done with exponentially increasing numbers. When 8 streams is used, the tool’s algorithm decides that both source and destination node capacities are reached since the NIC cards on the nodes are only 1Gbps. The optimal stream number is calculated based on our prediction model. The predicted number in this case is 4. By using 4 streams on each node, the node number is increased exponentially which is shown in the figure to the right. In the x-axis, each label represents stream number per stripe, stripe number per source node, number of source nodes , stripe number per destination node and number of destination nodes (e.g. 4stm-1str-1n-1str-1n). After 16 nodes, the sampling stops because the throughput starts to decrease. The highest throughput obtained is around 3Gbps. The optimal stripe number calculated in this case is 6.
In Figure 2, the algorithm uses similar settings for 4GB sampling size, however the throughput results obtained with stripes are higher, since the sampling size is increased. The highest throughput is around 4Gbps and the optimal stripe number is 7. This value reaches around 6 Gbps for 8 and 16GB sampling sizes (Figure 3 and Figure 4 respectively). Without any optimization with GridFTP only 240Mbps data transfer speed is obtained while with our tool we increase this value to 6Gbps.
REFERENCES
[1] E. Yildirim and T.Kosar, ”End-to-End Data-flow Parallelism for Throughput Optimization in High-speed Networks” Proc. NDM’11(in conjunction with SC’11).
Fig. 1. Sierra-India, Memory-to-Memory Transfers, 2GB sampling size
Fig. 2. Sierra-India, Memory-to-Memory Transfers, 4GB sampling size
Fig. 3. Sierra-India, Memory-to-Memory Transfers, 8GB sampling size
Fig. 4. Sierra-India, Memory-to-Memory Transfers, 16GB sampling size
Results for Project "99. Cloud-Based Support for Distributed Multiscale Applications"
Katarzyna Rycerz
AGH, Krakow, Institute of Computer Science
Last Modified:
The one part of our research was aimed at investigating the usability of business metrics for scaling policies in the cloud using the SAMM monitoring and management system. This system allows for autonomous decision making on the actions to be applied to the
monitored systems based on the retrospective analysis of their behavior over a period of time. The development work and tests were carried out using the FutureGrid project environment .The India Eucalyptus cluster was
used. The following virtual machine types were provided: small - 1 CPU, 512 MB of RAM, 5 GB of storage space, medium - 1 CPU, 1024 MB of RAM, 5 GB of storage space, large - 2 CPUs, 6000 MB of RAM, 10 GB of storage space, xlarge - 2 CPUs, 12000 MB of RAM, 10 GB of storage space, xlarge - 8 CPUs, 20000 MB of RAM, 10 GB of storage space. The test involved a numerical integration algorithm, while exploiting a master-slave paradigm.
The cluster is built up from 50 nodes and each node is able to run up to 8 small instances. Slave nodes in our application do not use much storage space and memory. To have got a fine-grained level of the management of the computing power, we decided to use small instances for them. The Master node application had higher memory requirements, thus we deployed it on a medium instance. To evaluate the quality of our approach we compared two strategies of automatic scaling. The first one exploits a generic metric - the CPU usage. The second strategy uses a business metric . The average time spent by computation requests while waiting in Slave Dispatcher's queue for processing. Upper or lower limits for such a metric could be explicitly included in a Service Level Agreement}, e.g. the service provider might be obliged to ensure that a request won't wait for processing for longer than one minute. In case the computing power was not suffiecient to process a task, additional virtual machines were launched.
The infrastructure was used in parallel with other users, thus, e.g., the startup time of virtual machines differed over time.Our experiments on the FutureGrid infrastructure allowed to infer that using the average wait time metric has a positive impact on the system when considering its operation from the business point of view. Since the end users are mostly interested in making the time required to wait as short as possible, the amount of the resources involved should be increased according to this demand. By improving this factor, the potential business value of the presented service grows. The system was automatically scaled by SAMM not only from the technical point of view but also from the business value perspective.
The results of our research are presented in two papers [1,2].
References
[1] Koperek, P., Funika, W. Automatic Scaling in Cloud Computing Environments Based on Business Metrics, in: Proc. of International
Conference on Parallel Programming and Applied Mathematics (PPAM'2011), 11-14 September 2011, Torun, Poland, LNCS, Springer, 2012 (to be
published)
[2] Funika, W., Koperek, P. Scalable Resource Provisioning in the Cloud Using Business Metrics, in: Proc. of the Fifth International Conference on
Advanced Engineering Computing and Applications in Sciences (ADVCOMP'2011), 20-25 November 2011, Lisbon, Portugal, 2011 (to be
published)
The other part of our research was to invesigate possibility of usage of FG resources for multiscale MUSCLE-based applications (in particular Instent restenosis application). We have already developed a system based on Amazon AWS API and we are in a process of testing it on FG resources (Eucaliptus). This is still ongoing work.
Results for Project "52. Cost-Aware Cloud Computing"
David Lowenthal
University of Arizona, Dept. of Computer Science
Last Modified:
Abstract:
Minimizing the operational cost while improving application execution times
and maximizing resource usage is a key research topic in Cloud Computing.
Different virtual machine configurations, associated cost and input
sizes make it challenging for the user to maximize resource usage while
minimizing total cost. In this project, we attempt to maximize the
resource usage by finding the largest possible input size considering
user constraints on the execution time and the operational cost.
Work done:
As Amazon EC2 is our commercial target platform, we came up with
different VM specifications. To understand system characteristics, we
wrote our own synthetic benchmarks. Following are the benchmarks we ran on FutureGrid:
- Pingpong (latency/bandwidth) tests
- Compute bound application tests, which we use in both strong and weak
scaling modes
- Memory access tests
- Scalability tests with NAS, ASCII Purple and synthetic benchmarks
on larger number of cores (both intra- and inter- VM)
Achievements/Results:
- We executed and studied benchmarks at different sites within FutureGrid.
- We used Eucalyptus and
Nimbus clients extensively to develop and test set of scripts aimed to
be used with Amazon EC2. This was possible due to compatibility
between EC2 and Eucalyptus APIs.
Overall, based on all of this, we have launched a project to develop a cloud service to automatically choose the most cost-effective cloud instance for a scientific application. FutureGrid has been extremely valuable to our research.
Results for Project "36. Advanced Technology for Sensor Clouds"
Ryan Hartman
Indiana University, University Information Technological Services
Last Modified:
Alex Ho and Geoffrey Fox Distributed FutureGrid Clouds for Scalable Collaborative Sensor-Centric Grid Applications Ball Aerospace Dayton (Fairborn) July 27 2011
Results for Project "8. Running workflows in the cloud with Pegasus"
Gideon Juve
University of Southern California, Information Sciences Institute
Last Modified:
Gideon Juve, Ewa Deelman, Automating Application Deployment in Infrastructure Clouds, 3rd IEEE International Conference on Cloud Computing Technology and Science (CloudCom 2011), 2011.
Jens-S. Vöckler, Gideon Juve, Ewa Deelman, Mats Rynge, G. Bruce Berriman, Experiences Using Cloud Computing for A Scientific Workflow Application, Proceedings of 2nd Workshop on Scientific Cloud Computing (ScienceCloud 2011), 2011.
Gideon Juve and Ewa Deelman, Wrangler: Virtual Cluster Provisioning for the Cloud, short paper, Proceedings of the 20th International Symposium on High Performance Distributed Computing (HPDC 2011), 2011.
Results for Project "125. The VIEW Project"
Shiyong Lu
Wayne State University, Department of Computer Science
Last Modified:
The VIEW scientific workflow management system will become available at (http://www.viewsystem.org) for scientists to design and execute scientific workflows remotely in a Grid or a Cloud environment that is provisioned by FutureGrid or other cyberinfrastructures.
Results for Project "14. Course: Distributed Scientific Computing Class"
Shantenu Jha
Louisiana State University, Center for Computation & Technology
Last Modified:
FutureGrid supported a new class focusing on a practical and comprehensive graduate course preparing students for research involving scientific computing. Module E (Distributed Scientific Computing) taught by Shantenu Jha used FutureGrid in hands-on assignments on:
- Introduction to the practice of distributed computing;
- Cloud computing and master-worker pattern;
- and Distributed application case studies.
- Two papers were written about this course: ICCS and TG'11
Results for Project "145. CloVR - Cloud Virtual Resource for Automated Sequence Analysis From Your Desktop"
Samuel Angiuoli
University of Maryland, Institute for Genome Sciences
Last Modified:
We have two publications describing the CloVR VM in press. The abstract for the main paper is Background: Next-generation sequencing technologies have decentralized sequence acquisition, increasing the demand for new bioinformatics tools that are easy to use, portable across multiple platforms, and scalable for high-throughput applications. Cloud computing platforms provide on-demand access to computing infrastructure over the Internet and can be used in combination with custom built virtual machines to distribute pre-packaged with pre-configured software. Results: We describe the Cloud Virtual Resource, CloVR, a new desktop application for push-button automated sequence analysis that can utilize cloud computing resources. CloVR is implemented as a single portable virtual machine (VM) that provides several automated analysis pipelines for microbial genomics, including 16S, whole genome and metagenome sequence analysis. The CloVR VM runs on a personal computer, utilizes local computer resources and requires minimal installation, addressing key challenges in deploying bioinformatics workflows. In addition CloVR supports use of remote cloud computing resources to improve performance for large-scale sequence processing. In a case study, we demonstrate the use of CloVR to automatically process next-generation sequencing data on multiple cloud computing platforms. Conclusion: The CloVR VM and associated architecture lowers the barrier of entry for utilizing complex analysis protocols on both local single- and multi-core computers and cloud systems for high throughput data processing.
Results for Project "38. Fine-grained Application Energy Modeling"
Catherine Olschanowsky
UCSD, SDSC/PMaC
Last Modified:
The following success story illustrates bare-metal access to FutureGrid where the user’s experiment required physical access to a FutureGrid node to attach a device needed to gather data for their research.
As with performance, energy-efficiency is not an attribute of a compute resource alone; it is a function of a resource-workload combination. The oper
ation mix and locality characteristics of the applications in the workload affect the energy consumption of the resource. Data locality is the primary source of variation in energy requirements. The major contributions of this work include a method for performing fine-grained DC power measurements on HPC resources, a benchmark infrastructure that exercises specific portions of the node in order to characterize operation energy costs, and a method of combining application information with independent energy measurements in order to estimate the energy requirements for specific application-resource pairings.
During August 2010, UCSD allocated a single node of the Sierra cluster to Olschanowsky for two weeks. During that time Olschanowsky attached a custom-made power monitoring harness to the node as shown in Figure 1.
Figure 1: Attached a custom-made power monitoring harness to the node.
Fine-grained power measurements of components were taken by measuring the current close to each component; this is done using a custom harness to intercept the DC signals. Both CPUs and each memory DIMM were measured this way. The CPUs are measured by intercepting the signal at the power socket between the power supply and the motherboard; the DIMMs are measured using extender cards. In addition to the DC measurements course-grained power measurements are taken using a WattsUp device (a readily available power analyzer). Once installed a series of benchmarks were run to gather needed data for their models. This data will be included as part of Olschanowky’s PhD dissertation. Olschanowsky is a PhD candidate for the Department of Computer Science and Engineering at UC San Diego.
The node that Olschanowsky used was tested and returned to service and will be recertified by IBM.

Results for Project "159. Evaluation of MPI Collectives for HPC Applications on Distributed Virtualized Environments"
Ivan Rodero
Rutgers University, NSF Center for Autonomic Computing
Last Modified:
We are working on setting up a project web site. Publications: [1] D. Villegas, I. Rodero, A. Devarakonda, Y. Liu, N. Bobroff, L. Fong, S.M. Sadjadi, M. Parashar, "Leveraging Cloud Federation in a Layered Service Stack Model", Journal of Computer and System Sciences, Special Issue on Cloud Computing, to appear.
Results for Project "143. Course: Cloud Computing for Data Intensive Science Class"
Judy Qiu
Indiana University, School of Informatics and Computing
Last Modified:
See class web page http://salsahpc.indiana.edu/csci-b649-2011/
This class involved 24 Graduate students with a mix of Masters and PhD students and was offered fall 2011 as part of Indiana University Computer Science program. Many FutureGrid experts went to this class which routinely used FutureGrid for student projects. Projects included
- Hadoop
- DryadLINQ/Dryad
- Twister
- Eucalyptus/Nimbus
- Virtual Appliances
- Cloud Storage
- Scientific Data Analysis Applications
Results for Project "139. Course: Cloud Computing and Storage Class"
Andy Li
University of Florida, Department of Electrical and Computer Engineering
Last Modified:
Education and course projects.
Results for Project "124. Course: CCGrid2011 Tutorial"
Gregor von Laszewski
Indiana University, Community Grids Laboratory
Last Modified:
We gave a tutorial to about 16 participants at TG11. 12 of them decided to participate in the online portion and engage in creating accounts.
The tutorial contents has been made available in the svn at
* http://futuregrid.svn.sourceforge.net/viewvc/futuregrid/presentations/tutorial-half-day/
We attempt to keep the material in this directory up to date. As a result of this tutorial we had additional projects been formulated such as from UNiversity of Fresno listed at
* http://archive.futuregrid.org/project/127
Lessons learned:
* portal account generation via the portal worked flawlessly and can be conducted throughout a tutorial. There is no need to create "fake" accounts or educational accounts.
* during the tutorial a tornado took place requiring the system staff that needs to be available to approve HPC, Nimbus, and EUcalyptus accounts to evacuate the building. We have devised a task to a) address the lack of a missing script to more easily generate accounts b) we recommend to distribute accunt generation to more than 1 members of the IU staff.
The project to deal with the modifications is available in jira at
http://jira.futuregrid.org/secure/Dashboard.jspa?selectPageId=10057
Results for Project "75. Cumulus"
John Bresnahan
Nimbus, Argonne National Lab
Last Modified:
Problem: The advent of cloud computing introduced a convenient model for storage outsourcing. At the same time, the scientific community already has large storage facilities and software. How can the scientific community that already has accumulated vast amounts of data and storage take advantage of these data storage cloud innovations? How will the solution compare with existing models in terms of performance and fairness of access?
Project: John Bresnahan at the University of Chicago developed Cumulus, an open source storage cloud and performed a qualitative and quantitative evaluation of the model in the context of existing storage solutions, and needs for performance and scalability. The investigation defined the pluggable interfaces needed, science-specific features (e.g., quota management), and investigated the upload and download performance as well as scalability of the system in the number of clients and storage servers. The improvements made as a result of the investigation were integrated into Nimbus releases.
This work, in particular the performance evaluation part was performed on 16 nodes of the FutureGrid hotel resource. It was important to obtain not only dedicated nodes but also a dedicated network for this experiment because network disturbances could affect the measurement of upload/download efficiency as well as the scalability measurement. Further, for the scalability experiments to be successful it was crucial to have a well maintained and administered parallel file system. The GPFS partition on FutureGrid's Hotel resource provided this. Such requirements are typically hard to find on platforms other than dedicated computing resources within an institution.
Figure: Cumulus scalability over 8 replicated servers using random and round robin algorithms
References:
- Cumulus: Open Source Storage Cloud for Science, John Bresnahan, Kate Keahey, Tim Freeman, David LaBissoniere. SC10 Poster. New Orleans, LA. November 2010.
- http://www.nimbusproject.org/files/cumulus_poster_sc10.pdf
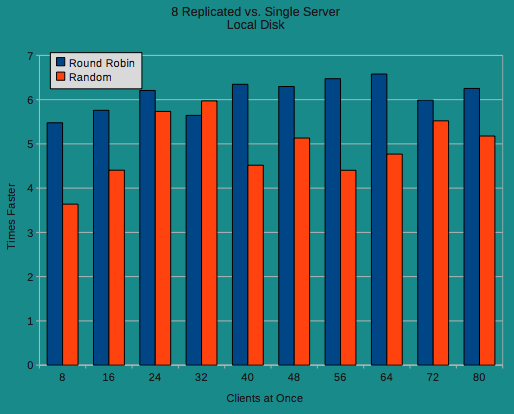
Results for Project "136. JGC-DataCloud-2012 paper experiments"
Mats Rynge
USC, ISI
Last Modified:
(will be posted as paper submission.)
Results for Project "47. Parallel scripting using cloud resources"
Michael Wilde
Argonne National Laboratory, Computation Institute
Last Modified:
http://www.ci.uchicago.edu/swift
Results for Project "76. Differentiated Leases for Infrastructure-as-a-Service"
Paul Marshall
University of Colorado at Boulder, Computer Science
Last Modified:
Problem: A common problem in on-demand IaaS clouds is utilization: in order to ensure on-demand availability providers have to ensure that there are available resources waiting for a request to come. To do that, they either have to significantly overprovision resources (in which case they experience low utilization) or reject a large proportion of requests (in which case the cloud is not really on-demand). The question arises: how can we combine best of both worlds?
Approach: Paul Marshall from the University of Colorado at Boulder approached this problem by deploying always-on preemptible VMs on all nodes of an IaaS cloud. When an on-demand request comes, the preemptible VMs are terminated in order to release resources for the on-demand request; when the nodes again become available the preemptible VMs are redeployed. Using this method, Paul was able to solve the utilization problem described above and demonstrate cloud utilization of up to 100%. Since sudden preemption is typical in volunteer computing systems such as SETI@home or various Condor installations, this solution was therefore evaluated in the context of a Condor system measure its efficiency for the volnteer computing execution which was shown to be over 90%.
In order to evaluate his system experimentally, Paul first modified the open source Nimbus toolkit to extend its functionality to supports the backfill approach. He then had to deploy the augmented implementation on a sizable testbed that gave him enough privilege (root) to install and configure the augmented Nimbus implementation -- Such requirements are typically hard to find on platforms other than dedicated local resources. In this case however, this testbed was provided by the FutureGrid hotel resource (specifically we used 19 8-core FG nodes on hotel).
Cloud utilization comparison for the same on-demand request trace.
Figure: Cloud utilization comparison for the same on-demand request trace: backfill VMs are disabled and the cloud is very little utilized ("cold");
Figure: Backfill VMs are enabled and the cloud achieves close to 100% utilization over the period of observation.
References:
- Improving Utilization of Infrastructure Clouds, Paul Marshall, Kate Keahey, Tim Freeman, submitted to CCGrid 2011.
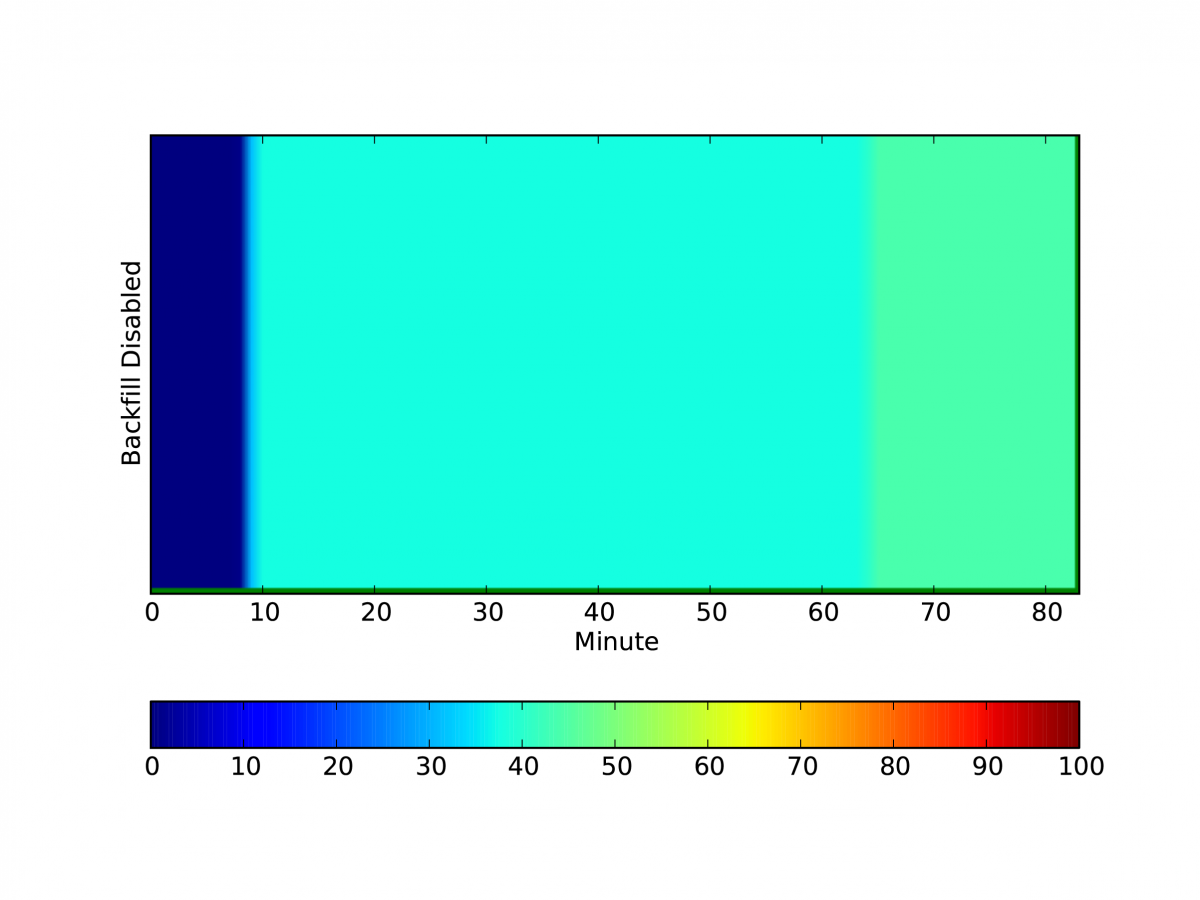
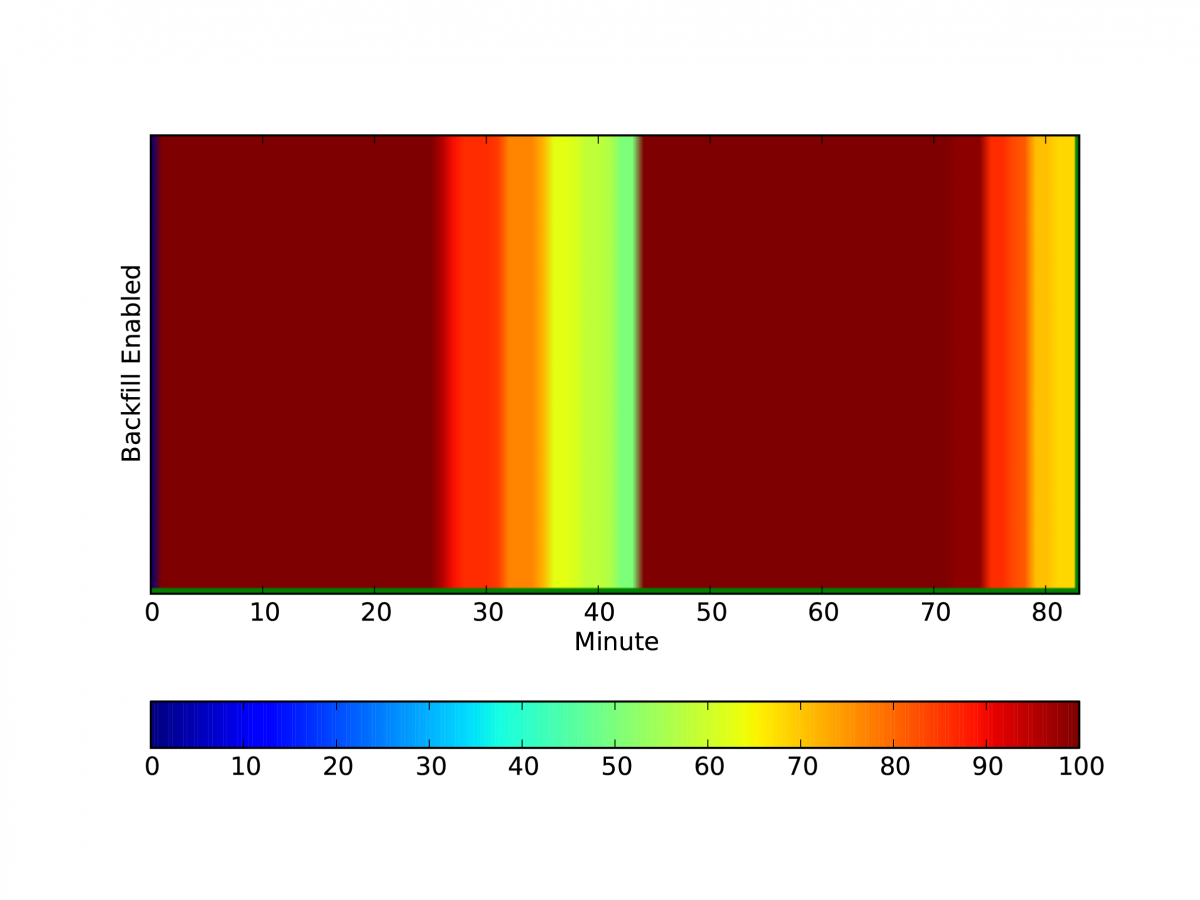
Results for Project "112. University of California (UC) Grid and Cloud Project"
Prakashan Korambath
UCLA, ATS
Last Modified:
Will be provided later
Results for Project "77. Periodogram Workflow Running on FutureGrid Using Pegasus"
Jens-S. Vöckler
University of Southern California, Information Sciences Institute
Last Modified:
Pegasus Does Sky Computing
Jens-S. Vöckler
USC-ISI
Gideon Juve
USC-ISI
Bruce Berriman
IPAC-CalTech
Ewa Deelman
USC-ISI
Mats Rynge
USC-ISI
A FutureGrid Success Story
The Periodogram workflow searches for extra-solar planets, either by “wobbles” in the radial velocity of a star, or dips in the star’s intensity. In either case, the workflow searches for repeating variations over time in the input “periodogram” data, a sub-set of the light curves released by the Kepler project. The workflow in this scenario only executed the “plav-chan”[1] algorithm, which is the computationally most intense. A full search needs to execute all three algorithms.
Figure 1: Workflow processing first release with one algorithm.Figure 1 shows the complete workflow of 1,599 Condor jobs and 33,082 computational tasks, computing every periodogram twice.[2] The top (root) node in the workflow graph is an ancillary job, creating the necessary directory to receive the computational output.
In the first level under the top, the 33k computational tasks were binned into 799 Condor jobs depending on their run-time estimate: extremely fast (sub-second), fast (minutes) and slow (hours). The last bin for extremely fast and fast jobs was not completely filled. Each Condor job stages in all “.tbl” files that the job requires, and stages back all “.out” and “.out.top” result files. The staging happens through Condor-I/O between the submit machine at ISI, and the remote resources in FutureGrid. The “heavy lifting” with regards to staging happens this point.
In the last level, 799 Condor staging jobs, ancillary jobs that Pegasus generated, copy a file on the submit host between directories. This seemingly redundant stage takes almost no time, and is not reflected in the timings except total run-time. We are working on removing this stage from the workflow plan.
Figure 2: Requested Resources per Cloud.
Figure 2 describes the resource request setup. We requested 90 resources from Nimbus clouds (blues), and 60 from Eucalyptus clouds (greens). 1/3 of combined resources were provided by sierra (SDSC), 1/3 by hotel (UofC), and the final 1/3 shared between india (IU) and foxtrot (UFl). 150 machines in five clouds at four sites with two cloud middleware systems justify the term Sky Computing for this experiment.
The resources boot a Pegasus VM image that has the Periodogram software installed. Each provisioned image, based on a CentOS 5.5 system, brings up a Condor startd, which reports back to a Condor collector at ISI. As much as possible, we tried to request non-public IP modes, necessitating the use of the Condor connection broker (CCB).
On the provisioned image, each host came up with 2 cores, and each core had 2 Condor slots assigned to it. This computational over-subscription of the remote resources is considered not harmful for the periodogram workflow. Further experimentation will be required to validate this decision.
The provision requests were entered manually, using the Nimbus- and Eucalyptus client tools. After the first resources started reporting back to the Condor collector, the Pegasus-planned workflow was started, resulting in an instance of Condor DAGMan executing the workflow. Once the workflow terminated successfully, the resources were manually released.
Figure 3 shows a combination of available Condor slots and jobs in various states for the duration of the workflow. The blue line shows the provisioned slots as they become available over time, thus starting in negative time with regards to the workflow. The start of the workflow indicates 0 in the x-axis.
Figure 3: Slots and Job State over time.
The blue line tops out at 622 resource slots. However, since this is a total derived from condor_status, the submit host slots (6) and any other non-participating slots (20) need to be subtracted, bringing the total to 596 slots, or 298 participating cores, or 149 remote hosts. It also shows that a single remote resource never reported back properly.
For this workflow, partial success for a resource request is not a problem. However, other workflows do rely on the all-or-nothing principle, and the middleware should never provision a partial success, unless expressly permitted.
The red line in Figure 3 shows the slots that Condor perceived to be busy. This curve is over-shadowed by the tasks in state executing found in the Condor queue. At one point during the workflow, the number of executing tasks topped out at 466 parallel executing tasks.
The yellow line shows the number of idle tasks in the Condor queue. The workflow manager DAGMan was instructed to only release more jobs into the queue, if there were less than 100 idle jobs. It does not make sense to drop hundreds of jobs into the queue, if only a limited number of them can run. While a maximum of 117 idle jobs does not hit the target perfectly, it is quite sufficient to balance between saturation and scalability.
Figure 4: Display of Table 1.
Site
Avail. Hosts
Active Hosts
Jobs
Tasks
Cumulative Duration (h)
Eucalyptus india
30
8
19
1900
0.4
Eucalyptus sierra
29
28
162
7080
119.2
Nimbus sierra
20
20
140
7134
86.8
Nimbus foxtrot
20
17
126
6678
77.5
Nimbus hotel
50
50
352
10290
250.6
TOTAL
149
123
799
33082
534.5
Table 1: Statistics about Sites, Jobs and Tasks.
Table 1 and Figure 4 summarize the hosts that, according to Condor, were actually participating in the workflow. With only 123 actively participating hosts that received work from the Condor scheduler, the maximum number of job slots is 492, over 100 slots less than we requested.
Even though the Eucalyptus resources on sierra were only participating with 8 hosts, they managed to deal with 1,900 tasks. The amount of tasks computed per site reflects the number of resources closely, albeit not the time taken.
Overall, the workflow contained over 22 days of computational work, including staging of data. The workflow executed in a little more than 2 hours total workflow duration.
Even though every periodogram was computed twice, input files were staged from separate locations, with 33,082 compressed files totaling 3.4 GB over Condor-I/O. The output totals 66,164 transfers of compressed files with over 5.8 GB size in transferred volume.
Size range
Input
.tbl.gz
Output
.top.gz
Output
.out.gz
1,024
2,047
606
2,048
4,095
32,476
4,096
8,191
8,192
16,383
8,457
16,384
32,767
1,065
32,768
65,535
1,297
21,638
65,536
131,071
5,665
131,072
262,143
52
262,144
524,287
1
11,434
524,288
1,048,575
4
10
1,048,576
2,097,152
Table 2: Ranges of compressed input and output sizes.
- [1] Binless phase-dispersion minimization algorithm that identifies periods with coherent phased light curves (i.e., least “dispersed”) regardless of signal shape: Plavchan, Jura, Kirkpatrick, Cutri, and Gallagher. ApJS, 175,19 (2008)
- [2] We will fix this in future re-runs.
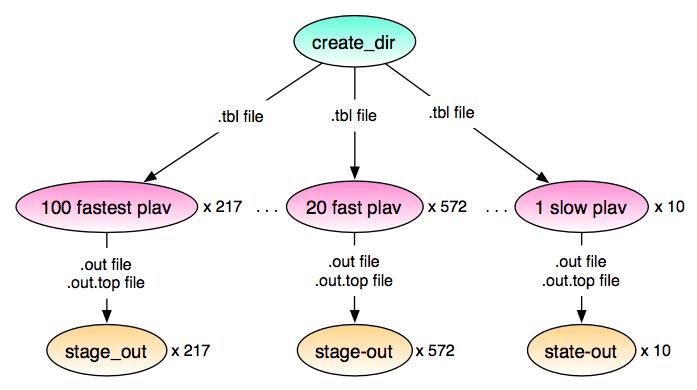
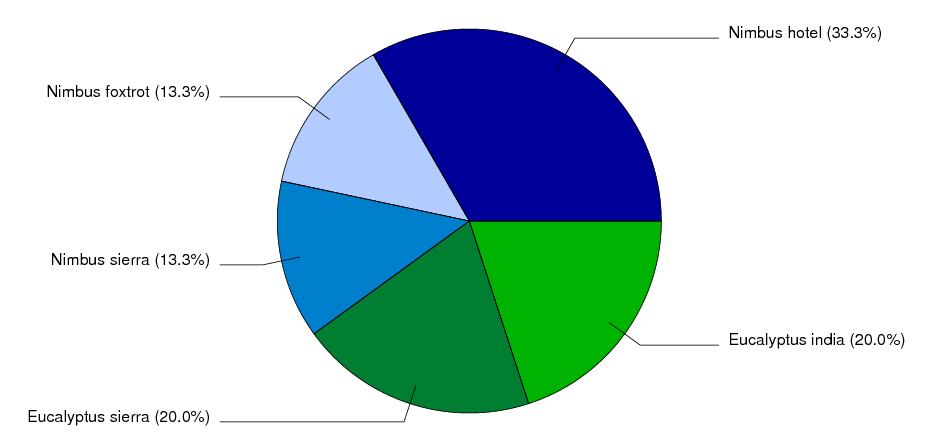
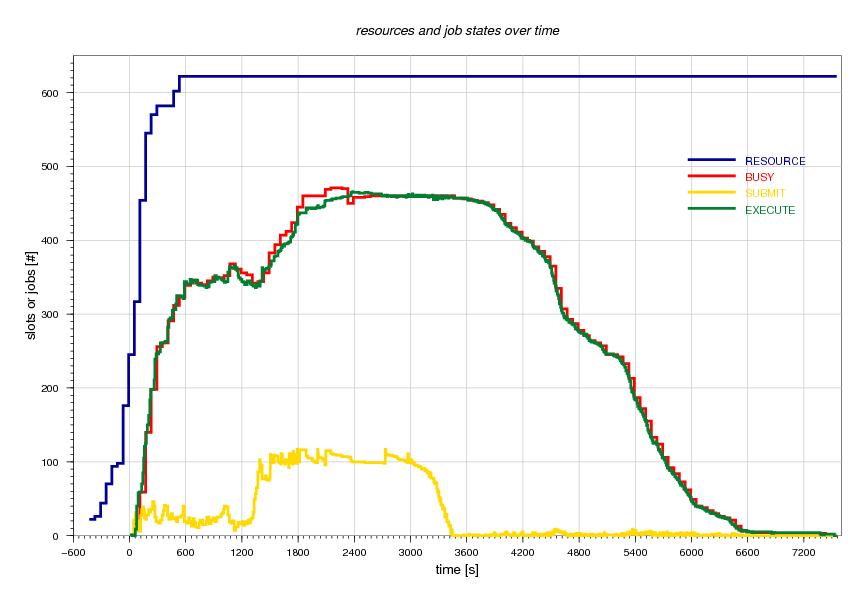
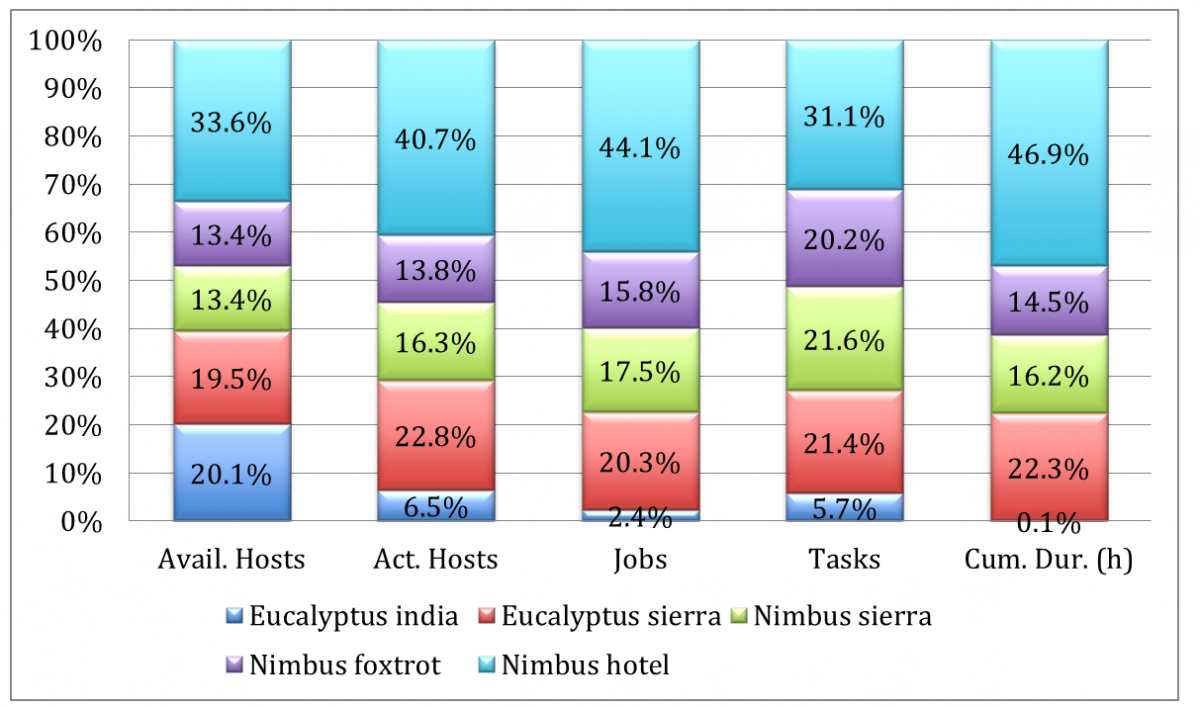
Results for Project "74. Sky Computing"
Pierre Riteau
University of Chicago, Computation Institute
Last Modified:
Problem: Scientific problems are often large and distributed by nature as they combine processing of data produced at various sources. In the context of cloud computing this leads to a question of what problems would arise if we were to use resources obtain from not just one IaaS cloud, but a federation of multiple geographically distributed infrastructure clouds. Such multi-cloud federations have been called “sky computing” (see [1]) and involve challenges of standardization, security, configuration, and networking.
Project: Pierre Riteau from the University of Rennes 1 proposed one solution in this space by creating a virtual cluster combining resources obtained from six geographically distributed Nimbus clouds: three hosted on Grid’5000 and three hosted on FutureGrid. Experimenting with distribution and scale he succeeded in creating a geographically distributed virtual cluster of over 1000 cores. His solution overcame firewall and incompatible network policy problems by using the ViNe overlay to create a virtual network and secure creation of a virtual cluster by using the Nimbus Context Broker. Further, in order to overcme the image distribution problem which becomes a significant obstacle to fast deployment at this scale Pierre developed a QCOW system which uses copy-on-write techniques to speed up image distribution.
Widely distributed compatible cloud resources needed for this experiment would have been impossible to obtain with the existence of resources such as Grid’5000 and FutureGrid and their close collaboration. In addition to experimenting with research problems at unprecedented scale, this project was also a proof-of-concept and a trail blazer for a close collaboration between Grid’5000 and FutureGrid. Because of its integrative nature, this project was demonstrated at OGF 29 in June 2010.
Figure: The sky computing experiment built a virtual cluster distributed over six Nimbus clouds using the ViNe virtual network overlay and the Nimbus Context Broker.
References:
- Sky Computing on FutureGrid and Grid’5000, Pierre Riteau, Mauricio Tsugawa, Andrea Matsunaga, José Fortes, Tim Freeman, David LaBissoniere, Kate Keahey. TeraGrid 2010, Pittsburgh, PA. August 2010 http://www.nimbusproject.org/files/riteau_tg10.ppt
- ISGTW article: Reaching for sky computing www.isgtw.org/?pid=1002832
- ERICM article: Large-Scale Cloud Computing Research: Sky Computing on FutureGrid and Grid’5000 http://ercim-news.ercim.eu/en83/special/large-scale-cloud-computing-research-sky-computing-on-futuregrid-and-grid5000
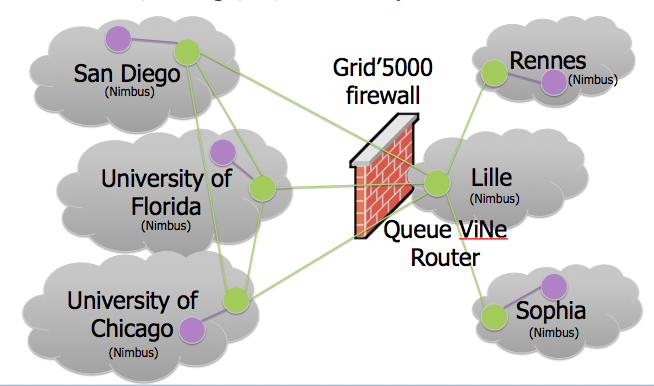
Results for Project "56. Windows and Linux performance comparison"
Robert Henschel
Indiana University, RT
Last Modified:
A collection of performance benchmarks have been run on the FutureGrid IBM System X iDataPlex cluster using two different operating systems. Windows HPC Server 2008 (WinHPC) and Red Hat Enterprise Linux v5.4 (RHEL5) are compared using SPEC MPI2007 v1.1, the High Performance Computing Challenge (HPCC) and National Science Foundation (NSF) acceptance test benchmark suites. Overall, we find the performance of WinHPC and RHEL5 to be equivalent but significant performance differences exist when analyzing specific applications. We focus on the results from the application benchmarks and include the results of the HPCC microbenchmark for completeness.
See also: http://hdl.handle.net/2022/9919
Results for Project "85. Exploring HPC Fault Tolerance on the Cloud"
Hui Jin
Illinois Insitute of Technology, Computer Science Department
Last Modified:
1 Overview
The potential of running traditional High-Performance Computing (HPC) applications on the emerging cloud computing environment has been gained intensive attractions recently. ScienceCloud [1] is the workshop that dedicates to study the potentials of scientific computing on the cloud environment. Furthermore, the projects such as FurtureGrid and Magellan has been created to as a testbeds to study the potential of science on the cloud.
While most existing studies focus on the performance, scalability and productivity of the HPC applications on the cloud, the reliability issue, however, has been rarely studied in the context. The reliability in HPC community has already been recognized as a critical challenge in limiting the scalability, especially for the upcoming exascale computing environment [2, 3]. The cloud
environment introduces more complicated software architecture and exposes the system with a higher risk of failures. Distinctive applications running on different virtual machines may share the same physical resource, which causes resource contention, application interaction and threatens the reliability further.
Checkpointing is the mostly used mechanism to support fault tolerance in HPC applications. While checkpointing and its behaviors have been well studied on high-end computing systems (HEC), there is limited study on evaluating the impact of cloud on the performance of checkpointing. Checkpointing on the cloud may present distinctive features differentiating it from the traditional HEC checkpointing. For example, in the cloud, hard disk of one physical machine is shared by multiple virtual machines, which burdens the performance since the checkpointing requests are usually issued in a burst. Also, if the checkpointing images go to the dedicated storage service in the cloud, more variations may be presented due to the fact that
multiple virtual machines of one node share one NIC and makes the performance difficult to predict.
2 Proposed Work
The objective of this project is to study the reliability implications of running HPC applications on the cloud. As the first stage of the project, we will focus on evaluating the performance of parallel checkpointing on the cloud.
The project requires the software that supports parallel system-level checkpointing. More specially, we will build the experiments on Open MPI [4] and BLCR [5]. Open MPI as a MPI-2 implementation that fully supports system level checkpointing. The lower level component that implements checkpointing on Open MPI is BLCR, a system level checkpointing on Linux. PVFS2 [6] is also required to evaluate the potential of checkpointing on the parallel file systems. The experiments will study the checkpointing performance on classical MPI benchmarks such as NPB [7] and MPI 2007 [8]. We are also planning to test the classical scientific computing modules such as Matrix Multiplication on FutureGrid.
The Scalable Computing Software (SCS) [9] Lab from Illinois Institute of Technology (IIT) has accumulated extensive expertise on the research of HPC reliability. Funded by NSF, the FENCE [10] project has been conducted successfully at SCS. The objective of FENCE is to build a Fault awareness ENabled Computing Environment for high performance computing. As part of the project, we have conducted research on the performance evaluation and optimization of checkpointing in HPC [11, 12, 13]. The experiments were based on the Sun ComputeFarm [14] of the SCS lab to evaluate the performance of the parallel checkpointing in cluster environment. The ComputeFarm is composed of 64 Sun File X2200 servers. Each node is equipped with
2.7GHz Opteron quad-core processors, 8GB memory and 250GB SATA hard drive. All the nodes are connected by 1 gigabit NICs in a fat tree topology. We have carried out experiments to examine the checkpointing performance for the NPB benchmarks. Different benchmarks present different checkpointing overhead in our system. We have observed a decreasing
performance as the application scales up, which implies the scalability limitations of parallel checkpointing in the cluster.
On the FutureGrid platform, we will scale the application size of our previous experiments with higher degree, potentially to the entire system if possible. The performance will be tested on both local storage of each virtual machine and the shared storage. We expect to reach scales of at least 2048 VM instances and evaluate the corresponding checkpointing performance. The
initial part of the project is planned to last about 3 months, with an estimated total CPU hours required of 409600 (2048vms*4hrs*50runs).
This project will evaluate the performance results of parallel checkpointing, observe the bottlenecks and propose solutions for the potential problems. The project will deliver a paper submission to a referenced conference (e.g. Supercomputing with an April 2011 deadline should be realistic) and be part of the Ph.D thesis of Hui Jin.
[1] 1st ACM Workshop on Scientific Cloud
http://dsl.cs.uchicago.edu/ScienceCloud2010/
[2] N. DeBardeleben, J. Laros, J. T. Daly, S. L. Scott, C. Engelmann, and B. Harrod. High-End Computing Resilience: Analysis of Issues Facing the HEC Community and Path-Forward for Research and Development. White paper, 2009. Online:
http://www.csm.ornl.gov/~engelman/publications/debardeleben09high-end.pdf
[3] F. Cappello, A. Geist, B. Gropp, L. Kale, B. Kramer, and M. Snir, Toward Exascale Resilience, International Journal of High Performance Computing Applications, vol. 23, no. 4, pp. 374-388, 2009.
[4] Open MPI Website, http://www.open-mpi.org/
[5] BLCR Website, https://ftg.lbl.gov/CheckpointRestart/CheckpointRestart.shtml
[6] PVFS2 Website, http://www.pvfs.org
[7] NAS Parallel Benchmarks, http://www.nas.nasa.gov/Resources/Software/npb.html
[8] MPI2007 Website, http://www.spec.org/mpi2007/
[9] SCS Website, http://www.cs.iit.edu/~scs
[10] FENCE Project Website, http://www.cs.iit.edu/~zlan/fence.html
[11] H. Jin, Checkpointing Orchestration for Performance Improvement, DSN 2010 (Student Forum)
[12] H. Jin, Y. Chen, T. Ke and X.-H. Sun, REMEM: REmote MEMory as Checkpointing Storage, CloudCom 2010.
[13] H. Jin, T. Ke, Y. Chen and X.-H. Sun, Checkpointing Orchestration: Towards Scalable HPC Fault Tolerance. IIT Technical Report, Sep 2010.
[14] Sun ComputeFarm at SCS Website: http://www.cs.iit.edu/~scs/research/resources.html
Results for Project "30. Publish/Subscribe Messaging as a Basis for TeraGrid Information Services"
Warren Smith
University of Texas at Austin, Texas Advanced Computing Center
Last Modified:
W. Smith. An Information Architecture Based on Publish/Subscribe Messaging. In Proceedings of the 2011 TeraGrid Conference. July, 2011. (Extended Abstract). Slides.
As outlined in the publication above, this project has used FutureGrid to prototype candidate implmementations for a new information service for TeraGrid/XSEDE and to gather performance information about the implementations. XSEDE has not yet begun serious discussions about how to implement a new information service, but I expect that FutureGrid will be used to gather data during that discussion and to perform testing on any new information service components before they go in to production on XSEDE.
Results for Project "73. TeraGrid QA Testing and Debugging"
Shava Smallen
UC San Diego, San Diego Supercomputer Center
Last Modified:
This success story illustrates collaboration with TeraGrid and the ability to acquire short-term access to FutureGrid resources in order to perform QA testing of software.
The mission of the TeraGrid Quality Assurance (QA) working group is to identify and implement ways in which TeraGrid software components/services and production deployments can be improved to reduce the number of failures requiring operator intervention that are encountered at TeraGrid resource provider sites. The TeraGrid QA group utilized FutureGrid in the below experiments:
GRAM 5 scalability testing: The TeraGrid Science Gateway projects tend to submit large amounts of jobs to TeraGrid resources usually through the Globus GRAM interfaces. Due to scalability problems with GRAM, members of the Science Gateway team at Indiana University extracted code from their GridChem and UltraScan Gateways anddeveloped a scalability test for GRAM. When GRAM 5 was released, GRAM 5 was deployed to a TACC test node on Ranger and scalability testing was started. Due to the possibility that the Ranger test node might be re-allocated, the group created an alternate test environment on FutureGrid in July 2010. A virtual cluster running Torque and GRAM 5 was created on UF’s Foxtrot machine using Nimbus. Access to the virtual cluster was provided to the Science Gateway team as well. One problem that was debugged on the virtual cluster was numerous error messages showing up in a log file in the user’s home directory. This did not effect job execution but took up space in the user’s home directory and was reported to the Globus developers. The effort is summarized in the following Wiki page at http://www.teragridforum.org/mediawiki/index.php?title=GRAM5_Scalability_Testing
GridFTP 5 testing: In order to test the newest GridFTP 5 release, the TeraGrid QA group again turned to FutureGrid and instantiated a single VM with GridFTP 5 on UCSD’s Sierra and UF’s Foxtrot machine in October 2010. They then verified several of the new features, such as data set synchronization and the offline mode for the server. No major problems were detected in this testing, though a bug related to the new dataset synchronization feature was reported. The results are summarized on the TeraGrid Wiki at http://www.teragridforum.org/mediawiki/index.php?title=GridFtp5_Testing.
Some results:
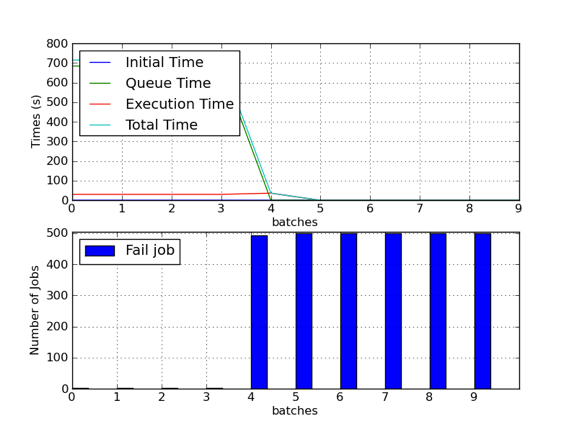
Results for Project "48. Cloud Technologies for Bioinformatics Applications"
Thilina Gunarathne
Indiana University, Community Grids Laboratory
Last Modified:
Ongoing with results:
For the first step of our project, we performed an in-detail performance analysis of different implementations of two popular bio-informatics applications, namely sequence alignment using SmithWaterman-GOTOH algorithm and sequence assembly using CAP3 program. These applications were implemented using cloud technologies such as Hadoop MapReduce and Microsoft DryadLINQ as well as using MPI. The performance comparison consisted of comparing the performance scalability of the different implementations, analyzing the effects of inhomogeneous data on the performance of cloud technology implementations and comparing the performance of cloud technology implementations under virtual and non-virtual (bare metal) environments. We also performed an auxiliary experiment to calculate the systematic error of these applications in different environments.
We used Apache Hadoop on 33 bare metal Linux Futuregrid nodes as well as on 33 future grid Linux virtual instances (deployed using Eucalyptus). We also used Microsoft DryadLINQ on 33 bare metal Windows HPCS cluster on Futuregrid.The results are published in the following paper.J. Ekanayake, T. Gunarathne, J. Qiu, and G. Fox. "Cloud Technologies for Bioinformatics Applications", Accepted for publication in Journal of IEEE Transactions on Parallel and Distributed Systems, 2010
Following graphs present few selected results from our project. For more information refer to the above paper.
For the second step of our project, we implemented few pleasingly parallel bio-medical applications using cloud technologies, Apache Hadoop MapReduce and Microsoft DryadLINQ, and using cloud infrastructure services provided by commercial cloud service providers, naming it the "Classic Cloud" model. The applications used were sequence assembly using Cap3, sequence alignment using BLAST, Generative Topographic Mapping (GTM) interpolation and Multi Dimensional Scaling (MDS) interpolation. We used Amazon EC2 and Microsoft Windows Azure platforms for obtaining the "Classic Cloud" implementation performance results, while we used FutureGrid compute resources to obtain the Apache Hadoop and Microsoft DryadLINQ performance results. The results were published in the following papers.
Thilina Gunarathne, Tak-Lon Wu, Judy Qiu, and Geoffrey Fox, Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications March 21 2010. Proceedings of Emerging Computational Methods for the Life Sciences Workshop of ACM HPDC2010 conference, Chicago, Illinois, June 20-25, 2010.
Thilina Gunarathne, Tak-Lon Wu, Jong Youl Choi, Seung-Hee Bae, Judy Qiu Cloud Computing Paradigms for Pleasingly Parallel Biomedical Applications, Submitted for publication in ECMLS special edition of Concurrency and Computations Journal (invited).
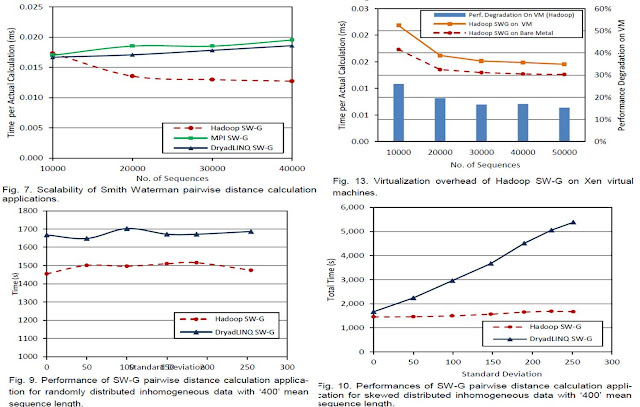
Results for Project "209. Quantifying User Effort to Migrate MPI Applications"
Karolina Sarnowska-Upton
University of Virginia, Computer Science
Last Modified:
Results for Project "219. FutureGrid Project Challenge: A CLOUD COMPUTING ARCHITECTURE FOR SUPPLY CHAIN NETWORK SIMULATION"
Yaohua Chen
University of Arkansas, Fayetteville, Industrial Engineering
Last Modified:
Abstract:
Large-scale supply chains usually consist of thousands of stock keep units (SKUs) stocked at different locations within the supply chain. The simulation of large-scale multi-echelon supply chain networks is very time consuming. The purpose of this project is to design a cloud computing architecture to facilitate the computational performance of large scale supply chain network simulations. A Cloud Computing Architecture For Supply Chain Network Simulation (CCAFSCNS) was designed in this project, and a prototype system was developed using the computing resources in the FutureGrid. The simulations are essentially compute-intensive Monte-Carlo experiments requiring multiple replications. Replications are distributed across virtual machines within CCAFSCNS. The results show that the cloud computing solution can significantly shorten the simulation time.
Resources used in this project:
- Virtual Machine: Grid Appliance
- Hardware Systems: Alamo Network
- Service Access: Nimbus Cloud Client
Completed Work:
- Customized the Grid Appliance to be Condor Server, Condor Worker and Condor Client.
- Designed a Cloud Computing Architecture For Supply Chain Network Simulation (CCAFSCNS).
- Developed a prototype system that implemented the CCAFSCNS with Excel, Access, Spring Framework, supply chain network simulator, FutureGrid, the Condor System, and the Grid Appliance. The virtual machines (VMs) of the Condor Worker, which is customized based on the Grid Appliance, are started in the Alamo network. These VMs are the computing resources used in the prototype system to run simulation jobs.
- Analyzed the impacts of large scale data on the prototype system
- Did a computational time study on the cloud computing solution based on FutureGird:
- Analyzed the time components used in the cloud computing solution
- Estimated the scheduling time for a simulation request
- Compared the simulation time spent on traditional solution and cloud computing solution and showed that the cloud computing solution can save 70% of the simulation time
Achievements/Publications:
- One Master project report has been submitted to fulfill the requirement for the degree of Master of Science.
- One conference paper has been submitted to the 2012 Winter Simulation Conference.
Broader Impacts:
A Cloud Computing application capable of evaluating the performance of multi-echelon supply networks through simulation is developed in this project. This application includes a web application that can run the simulation from the cloud and a database application that helps users develop the input data and analyze the output data. Companies will be able to use the results to develop better systems and software products that rely on cloud computing for applications involving this use case. In addition, the cloud computing architecture designed in this project can be used to develop other cloud computing solutions. Also, educational materials, such as the tutorials of building the Condor System, are developed to provide how-to knowledge for other researchers and industry collaborators.
Results for Project "220. FutureGrid Project Challenge (Project FG-172)"
Sebastiano Peluso
IST / INESC-ID, INESC-ID / Distributed Systems Group
Last Modified:
Publications:
- Sebastiano Peluso, Pedro Ruivo, Paolo Romano, Francesco Quaglia and Luís Rodrigues, "When Scalability Meets Consistency: Genuine Multiversion Update-Serializable Partial Data Replication". Proc. of 32nd IEEE International Conference on Distributed Computing Systems (ICDCS), June 2012
Results for Project "225. Budget-constrained workflow scheduler"
Adrian Muresan
ENS Lyon, France, Parallel algorithms laboratory (LIP)
Last Modified:
work progress...
Results for Project "244. Course: Data Center Scale Computing"
Dirk Grunwald
Univ. of Colorado, Boulder, Computer Science
Last Modified:
Results are not known at this time.
Results for Project "254. Information Diffusion in Online Social Networks"
Karissa McKElvey
Indiana University, Center for Complex Networks and Systems Research
Last Modified:
truthy.indiana.edu is a website which visualizes tweets collected from Twitter specifically relating to politics, social movements, and news from the past 90 days. We would like to increase this capacaity to over a year and compute the statistics at more frequent intervals.
Results for Project "256. QuakeSim Evaluation of FutureGrid for Cloud Computing"
Andrea Donnellan
Jet Propulsion Laboratory, California Institute of Technology, Science Division
Last Modified:
http://quakesim.org
Results for Project "276. Course (1 day): K12 Introduction High Performance and Cloud Computing"
Thomas Hacker
Purdue University, Computer & Information Technology
Last Modified:
The students were able to use susestudio easily. However, preparation of the environment was still too complex as the instalation requires flash to be on the system. As a Linux distribution was used, flash needed to be installed by the users. In retorspect the image that we gave to the stuudents should have flash already integrated.
Form the 12 students that participated, 1 was female. Two high school teachers participated.
We suggested the teachers to create science videos that demonstrate the use of parallel computers
Results for Project "323. Biomedical Natural Language Processing"
Euisung Jung
University of Wisconsin at Milwaukee, Business / MIS department
Last Modified:
Statistical and linguistical analysis of clinical text
Results for Project "358. Course: UoIceland Teaching"
Morris Riedel
Juelich Supercomputing Centre, Federated Systems and Data
Last Modified:
Students will have an understanding of the open source frameworks in the field of data mining, machine learning in combination with (batch) execution frameworks. Selected contributions of student project results will be given as an input to the RDA Big Data Analytics Group that in turn creates a classification of feasible big data analytics approaches including algorithms, frameworks, and underlying resources.
Results for Project "333. Intrusion Detection and Prevention for Infrastructure as a Service Cloud Computing System"
Jessie Walker
University of Arkansas at Pine Bluff , Computer Science
Last Modified:
No results as of yet.
Results for Project "379. The genome of a terrestrial metazoan extremophile"
Luis Cunha
Cardiff University, School of Biosciences
Last Modified:
The complete genome of Pontoscolex corethrurus
Results for Project "382. Reliability Analysis using Hadoop and MapReduce "
Carl Walasek
University of the Sciences , Mathematics, Physics, and Statistics Department
Last Modified:
Results will be made available.
Results for Project "391. Course: Topics in Parallel Computation"
Heru Suhartanto
Universitas Indonesia, Faculty of Computer Science
Last Modified:
home work reports related with MPI and CUDA programming.
Results for Project "194. SGVO Cloud Options Working Group"
Alan Sill
Texas Tech University, High Performance Computing Center
Last Modified:
Pending project request approval, we would expect to provide ongoing communication as to progress.
Results for Project "176. Cloud Interoperability Testbed"
Alan Sill
Texas Tech University, High Performance Computing Center
Last Modified:
The different groups using access to FutureGrid through this project have a variety of expected output types. The OGF group with the same name as this project (Cloud Interoperability) will be charged with producing Experience documents and Community Practice documents that capture the output of its tests. Related groups from other SDOs will be asked to provide output also or to provide the results of their efforts to the OGF CI-WG as input to their efforts for eventual categorization and documentation as above. Finally, where possible code will be provided to the community to encourage adoption of implementations of standards that prove useful as a result of these efforts.
Results for Project "445. Deployment of Virtual Clusters on a Commercial Cloud Platform for Molecular Docking"
Anthony Nguyen
University of California, San Diego, PRIME/PRAGMA
Last Modified:
By the conclusion of this project, we expect to have a functional set of virtual clusters running protein-ligand interaction simulations. These virtual clusters will be able to be networked with similar virtual clusters on different clouds to allow the tasks to be split amongst more resources. We will also have an understanding of the limits of the system through our fault tolerance and elasticity testing.
Results for Project "447. Using SNORT and AFTERGLOW to detect and visualize all malicious attacks within IaaS Cloud COmputing Systems"
Tofuli Baendo
University of Arkansas at Pine Bluff (UAPB), Mathematics and Computer Science Division
Last Modified:
Not yet.