FG-216
Scaling-out CloudBLAST: Combining Technologies to BLAST on the Sky
Crosscloud Computing
Scaling-out CloudBLAST: Deploying Elastic MapReduce across Geographically Distributed Virtulized Resources for BLAST
Project Details
- Project Lead
- Andrea Matsunaga
- Project Manager
- Andrea Matsunaga
- Project Members
- Mauricio Tsugawa
- Institution
- University of Florida, ECE/ACIS
- Discipline
- Electrical and Related Engineering (106)
- Subdiscipline
- 14.09 Computer Engineering
Abstract
This project proposes and evaluates an approach to the parallelization, deployment and management of embarrassingly parallel bioinformatics applications (e.g., BLAST) that integrates several emerging technologies for distributed computing. In particular, it evaluates scaling-out applications on a geographically distributed system formed by resources from distinct cloud providers, which we refer to as sky-computing systems. Such environments are inherently disconnected and heterogeneous with respect to performance, requiring the combination and extension of several existing technologies to efficiently scale-out applications with respect to management and performance.
Intellectual Merit
An end-to-end approach to sky computing is proposed, integrating several technologies and techniques, namely, Infrastructure-as-a-Service cloud toolkit (Nimbus) to create virtual machines (VMs) on demand with contextualization services that facilitate the formation and management of a logic cluster, virtual network (ViNe) to connect VMs on private networks or protected by firewalls, virtual networking (TinyVine) to overcome additional connectivity limitations imposed by cloud providers or middleware, MapReduce framework (Hadoop) for parallel fault-tolerant execution of unmodified applications, extensions to Hadoop to handle inputs as those required by BLAST, and skewed task distribution to deal with resource imbalance.
Broader Impacts
The outcomes of this project are made available in the form of publications, demos, appliances, presentations and tutorials. This material can be transformative in accelerating future computer engineering developments by taking advantage of a proven integrated cloud-based solution and in facilitating the use of complex systems by non-experts in the field of bioinformatics by offering an end-to-end solution to run BLAST that does not require in-depth knowledge of the underlying cyberinfrastructure technologies.
Scale of Use
Every system you have for blocks of few days for running large experiments (already provided). A few VMs for upgrading and maintaining of existing solution.
Results
The overall integration of technologies has been described in http://escience2008.iu.edu/sessions/cloudBlast.shtml. It also presents the low overhead imposed by the various technologies (machine virtualization, network virtualization) utilized, the advantages using a MapReduce framework for application parallelization over traditional MPI techniques in terms of performance and fault-tolerance, and the extensions to Hadoop required to integrate an application like the NCBI BLAST.
Challenges to the network virtualization technologies to enable inter-cloud communication, and a solution to overcome them called TinyVine is presented in http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5380884. A comparative analysis of existing solutions addressing sky computing requirements is presented along with experimental results that indicates negligible overhead for embarrassingly parallel applications such as CloudBLAST, and low overhead for network intensive applications such as secure copy of files.
In the largest experiment using FutureGrid (3 sites) and Grid’5000 (3 sites) resources, a virtual cluster of 750 VMs (1500 cores) connected through ViNe/TinyViNe was able to execute CloudBLAST achieving speedup of 870X. To better handle the heterogeneous performance of resources, an approach that skews the distribution of MapReduce tasks was shown to improve overall performance of a large BLAST job using FutureGrid resources managed by Nimbus (3 sites). Both results can be found in http://www.booksonline.iospress.nl/Content/View.aspx?piid=21410.
Table 1. Performance of BLASTX on sky-computing environments. Speedup is computed as the time to execute a BLAST search sequentially divided by the time to execute using the cloud resources. A computation that would require 250 hours if executed sequentially, can be reduced to tens of minutes using sky computing.
| Experiment | Number of Clouds | Total VMs | Total Cores | Speedup |
| 1 | 3 | 32 | 64 | 52 |
| 2 | 5 | 150 | 300 | 258 |
| 3 | 3 | 330 | 660 | 502 |
| 4 | 6 | 750 | 1500 | 870 |

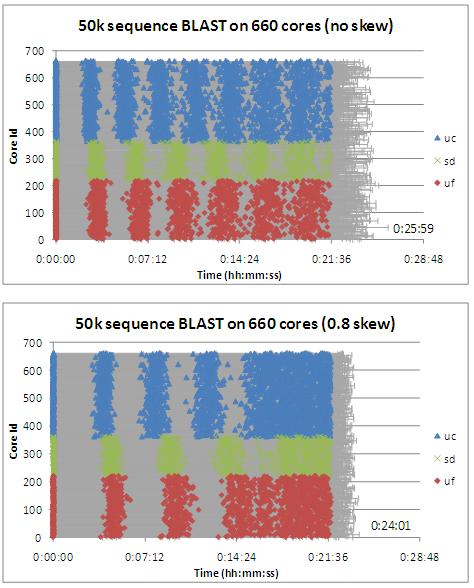

Figure 1: Comparison of executions of a 50000-sequence BLAST job divided into 256 tasks with (a) uniform or (b) skewed sizes on 660 processors across 3 different sites (University of Chicago, University of Florida, and San Diego Supercomputing Center). The progress of time is shown in the horizontal axis and the vertical axis represents each of the 660 individual workers. In this particular setup, the overall time perceived by the end user when running with skewed tasks is 8% shorter than when running with uniform tasks.