The field of parallel computing changes rapidly with, as in the
workstation market, vendors leapfrogging each other with new models.
Further, any given model is essentially obsolete after some three
years, with new machines having very different design and software
support. Here, we will discuss some of the machines that are
interesting in 1992. There are three broad classes of machines. The
first is the so-called SIMD, or synchronous machine, where we have a
coupled array of computers with distributed memory and processing
units, i.e., each processor unit is associated with its own memory.
On SIMD machines, each node executes the same instruction stream. The
latest example of this is the Maspar MP-1, remarketed with additional
software as the DECmpp by Digital The MP-1 has up to 16K four-bit
processors and one Gigabyte (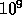 bytes) of memory and approximately
one GigaFLOPS (10
bytes) of memory and approximately
one GigaFLOPS (10 floating point operations per second) peak
performance. The Connection Machine CM-1, CM-2, and CM-200 are also
SIMD distributed memory machines.
floating point operations per second) peak
performance. The Connection Machine CM-1, CM-2, and CM-200 are also
SIMD distributed memory machines.
Thinking Machines surprised the community by changing the architecture of their latest CM-5, shown in Figure 7, to be the so-called MIMD distributed memory architecture. Again, we have a coupled collection of nodes---each with memory and processor---but now each node can execute its own instruction stream. The largest CM-5 delivered has 1,024 nodes, 32 Gigabytes of memory, and can, on some applications, realize 80 GigaFLOPS. The CM-5 installations are not fully implemented, and the largest parallel computer in operation today is the Intel ``Delta Touchstone'' System at Caltech, shown in Figure 8. This is also a MIMD distributed memory machines with 528 nodes, but a very different node interconnection scheme. Intel's Touchstone family continues to evolve, and the latest ``Paragon'' model, which will be available later this year, should have similar performance to the CM-5. The nCUBE, shown in Figure 1, also has the MIMD distributed memory design.

Figure 7: The CM-5 Produced by Thinking Machines

Figure 8: The ``Delta Touchstone'' Parallel Supercomputer Installed at
Caltech and Produced by Intel
All the parallel machines discussed above are ``scalable'' and available in configurations that vary from small $100,000 systems to a full size supercomputer at approximately $30,000,000; the number of nodes and performance scales approximately linearly with the price. The DECmpp (Maspar) has deliberately aimed at the low end of the market and the largest 16K system costs factor of 25--50 less than the 1024-node CM-5 discussed above. In fact, as all the machines use similar VLSI technology, albeit with designs that are optimized in different ways, they very crudely have similar price performance. This, as shown in Figure 2, much better than that of conventional vector supercomputers, such as those from Cray, IBM, and Japanese vendors.
Current Cray and IBM supercomputers are also parallel with up to 16
processors in the latest CRAY C-90. their architecture is MIMD shared
memory with a group of processors accessing a single global memory.
This design is also seen on machines like the Sequent and high-end
Silicon Graphics workstations, but all these machines have a modest
number ( ) processors as they are hard to scale to many
processors, i.e., to ``massive parallelism.''
) processors as they are hard to scale to many
processors, i.e., to ``massive parallelism.''
An ingenious compromise is seen in the recent Kendall Square machine KSR-1, and the experimental DASH computer at Stanford. These have a so-called virtual shared memory. The machine is built with a distributed memory, but special hardware (caches) and software make this distributed memory ``act'' as though it is globally available to all processors.
Currently, the dominant parallel computer vendors are American with only modest competition from Europe, with systems built around the transputer chip from Inmos. Japanese manufacturers have so far made little contribution to this field, but as the technology matures, we can expect them to provide formidable competition.