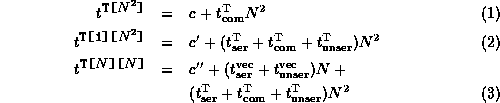For the sake of concrete discussion we will
make an assumption that, in the kind of Grande applications where MPI is
likely to be used, some of the most pressing performance issues
concern arrays
and multidimensional arrays of small objects--especially arrays
of primitive elements such as ints and floats. For
benchmarks we therefore concentrated on the overheads
introduced by object serialization when the objects contain many arrays
of primitive elements. Specifically we concentrated on communication
of two-dimensional arrays with primitive elements![]() .
.
The ``ping-pong'' method was used to time
point-to-point communication of an N by N array of primitive
elements treated as a one dimensional array of objects, and compare it
with communication of an ![]() array without using serialization. As
an intermediate case we also timed communication of a 1 by
array without using serialization. As
an intermediate case we also timed communication of a 1 by ![]() array treated as a one-dimensional (size 1) array of objects.
This allows us to extract an estimate of the overhead to ``serialize''
an individual primitive element.
The code for sending and receiving the various array shapes
is given schematically in Figure 2.
array treated as a one-dimensional (size 1) array of objects.
This allows us to extract an estimate of the overhead to ``serialize''
an individual primitive element.
The code for sending and receiving the various array shapes
is given schematically in Figure 2.

Figure 2: Send and receive operations for various array shapes.
As a crude timing model for these benchmarks, one can assume that there
is a cost ![]() to
serialize each primitive element of type T, an additional cost
to
serialize each primitive element of type T, an additional cost
![]() to serialize each
subarray, similar constants
to serialize each
subarray, similar constants
![]() and
and
![]() for
unserialization, and a cost
for
unserialization, and a cost
![]() to
physically tranfser each element of data.
Then the total time for benchmarked communications should be
to
physically tranfser each element of data.
Then the total time for benchmarked communications should be
These formulae do not attempt to explain the constant initial overhead, don't take into account the extra bytes for type description that serialization introduces into the stream, and ignore possible non-linear costs associated with analysing object graphs, etc. Empirically these effects are small for the range of N we consider.
All measurements were performed on a cluster of 2-processor, 200 Mhz UltraSparc nodes connected through a SunATM-155/MMF network. The underlying MPI implementation was Sun MPI 3.0 (part of the Sun HPC package). The JDK was jdk1.2beta4. Shared memory results quoted are obtained by running two processes on the processors of a single node. Non-shared-memory results are obtained by running peer processes in different nodes.
In a series of measurements, element serialization and unserialization
timing parameters were estimated by independent benchmarks of the
serialization code. The parameters ![]() and
and ![]() were estimated by plotting the
difference between serialization and unserialization times for
T[1][
were estimated by plotting the
difference between serialization and unserialization times for
T[1][ ![]() ] and T[N][N]
] and T[N][N]![]() .
The raw communication speed was
estimated from ping-pong results for
.
The raw communication speed was
estimated from ping-pong results for ![]() .
Table 1
contains the resulting estimates of the various parameters for byte
and float elements.
.
Table 1
contains the resulting estimates of the various parameters for byte
and float elements.
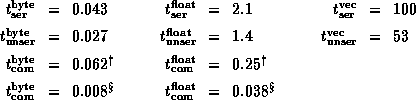
Table 1: Estimated parameters in serialization and communication timing
model. The ![]() values
are respectively for non-shared memory (
values
are respectively for non-shared memory ( ![]() ) and shared memory (
) and shared memory ( ![]() )
implementations of the underlying communication. All timings are in
microseconds.
)
implementations of the underlying communication. All timings are in
microseconds.
Figure 3 plots actual measured
times from ping-pong benchmarks for the mpiJava sends and receives of
arrays with byte and float elements. In the
plots the array extent, N, ranges between 128 and 1024. The measured
times for ![]() ,
, ![]() and
and ![]() are compared
with the formulae given above (setting the c constants to zero). The
agreement is good, so our parametrization is assumed to be realistic in
the regime considered.
are compared
with the formulae given above (setting the c constants to zero). The
agreement is good, so our parametrization is assumed to be realistic in
the regime considered.
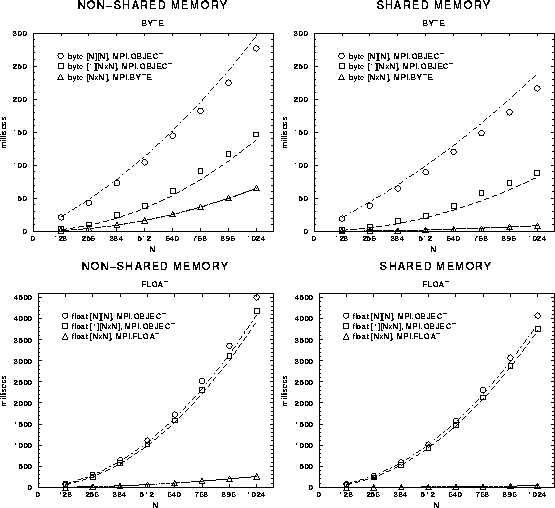
Figure: Communication times from Pingpong benchmark in non-shared-memory
and shared-memory cases. The lines represent the model
defined by Equations 1 to 3 in the text, with
parameters from Table 1.
According to table 1 the overhead of Java serialization nearly always dominates other communiation costs. In the worst case--floating point numbers--it takes around 2 microseconds to serialize each number and a smaller but comparable time to unserialize. But it only takes a few hundredths of a microsecond to communicate the word through shared memory. Serialization slows communication by nearly two orders of magnitude. When the underlying communication is over a fast network rather than through shared memory the raw communication time is still only a fraction of a microsecond, and serialization still dominates that time by about one order of magnitude. For byte elements serialization costs are smaller, but still larger than the communication costs in the fast network and still much larger than the communication cost through shared memory. Serialization costs for int elements are intermediate.
The constant overheads for serializing each subarray, characterized by
the parameters ![]() and
and ![]() are also
quite large, although, for the array sizes considered here they only
make a dominant contribution for the byte arrays, where
individual element serialization is relatively fast.
are also
quite large, although, for the array sizes considered here they only
make a dominant contribution for the byte arrays, where
individual element serialization is relatively fast.