The work of [17] and others has established that there is considerable scope to optimize the JDK serialization software. Here we pursue an alternative that is interesting from the point of view of ultimate efficiency in messaging APIs, namely to replace calls to the writeObject, readObject methods with specialized, MPI-specific, functions. A call to standard writeObject, for example, might be replaced with a native method that creates a native MPI derived datatype structure describing the layout of data in the object. This would provide the conceptually straightforward object serialization model at the user level, while retaining the option of fast (``zero-copy'') communication strategies inside the implementation.
Implementing this general scheme for every kind of Java object is difficult or impractical because the JVM hides the internal representation of most objects. Less ambitiously, we can attempt to eliminate the serialization and copy overheads for arrays of primitive elements embedded in the serialization stream. The general idea is to produce specialized versions of ObjectOutputStream and ObjectInputStream that yield byte streams identical to the standard version except that array data is omitted from those streams. The ``data-less'' byte stream is sent as a header. This allows the objects to be reconstructed at the receiving end. The array data is then sent separately using, say, suitable native MPI_TYPE_STRUCT types to send all the array data in one logical communication. In this way the serialization overhead parameters measured in the benchmarks of the previous section can drastically reduced or eliminated. An implementation of this protocol is illustrated in Figure 4.
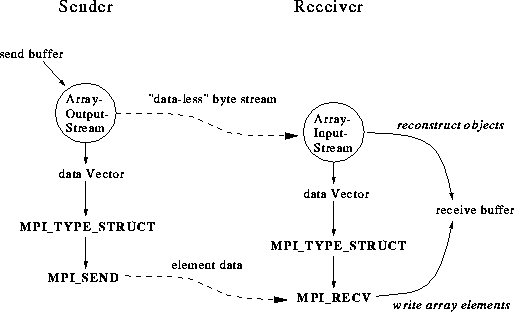
Figure 4: Improved protocol for handling arrays.
A customized version of ObjectOutputStream called ArrayOutputStream behaves in exactly the same way as the original stream except when it encounters an array. When an array is encountered a small object of type ArrayProxy is placed in the stream. This encodes the type and size of the array. The array reference itself is placed in a separate container called the ``data vector''. When serialization is complete, the data-less byte stream is sent to the receiver. A piece of native code unravels the data vector and sets up a native derived type, then the array data is sent. At the receiving end a customized ArrayInputStream behaves exactly like an ObjectInputStream, except that when it encounters an ArrayProxy it allocates an array of the appropriate type and length and places a handle to this array in the reconstructed object graph and in a data vector container. When this phase is completed we have an object graph containing uninitialized array elements and a data vector, created as a side effect of unserialization. A native derived data type is constructed from the data vector in the same way as at the sending end, and the data is received into the reconstructed object in a single MPI operation.
Our implementation of ArrayOutputStream and ArrayInputStream is straightforward. The standard ObjectOutputStream provides a method, replaceObject, which can be overridden in subclasses. ObjectInputStream provides a corresponding resolveObject method. Implementation of the customized streams is sketched in Figure 5.

Figure 5: Pseudocode for ArrayOutputStream and
ArrayInputStream
Figure 3 shows the effect this change of protocol has on the original timings. As expected, eliminating the overheads of element serialization dramatically speeds communication of float arrays (for example) treated as objects, bringing bandwidth close to the raw performance available with MPJ.FLOAT.
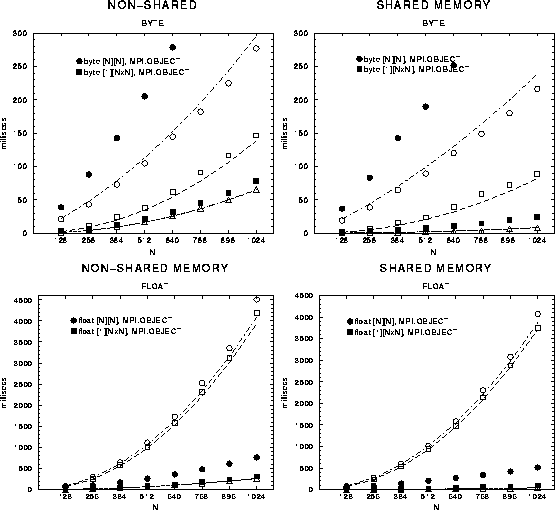
Figure: Pingpong timings with primitive array data sent separately (solid
points), compared with the unoptimized results from Figure 3
(open points). Recall that the goal is to bring times for ``object-oriented''
sends of arrays down to the ``native'' send times,
most closely approximated by the triangular points.
Each one-dimensional array in the stream needs some separate processing
here (associated with calls to replaceObject, resolveObject,
and setting up the native MPI_TYPE_STRUCT). Our fairly
simple-minded prototype happened to increase the constant overhead
of communicating each subarray (parametrized by ![]() and
and ![]() in the previous section).
As mentioned at the end of section 4,
this overhead
typically dominates the time for communicating two-dimensional byte arrays
(where the element serialization cost is less extreme), so performance
there actually ends up being worse. A more highly tuned implementation
could probably reduce this problem. Alternatively we can go a
step further with our protocol, and have the serialization stream
object directly replace two-dimensional arrays of primitive
elements
in the previous section).
As mentioned at the end of section 4,
this overhead
typically dominates the time for communicating two-dimensional byte arrays
(where the element serialization cost is less extreme), so performance
there actually ends up being worse. A more highly tuned implementation
could probably reduce this problem. Alternatively we can go a
step further with our protocol, and have the serialization stream
object directly replace two-dimensional arrays of primitive
elements![]() . The benefits
of this approach are shown in Figure 7.
. The benefits
of this approach are shown in Figure 7.
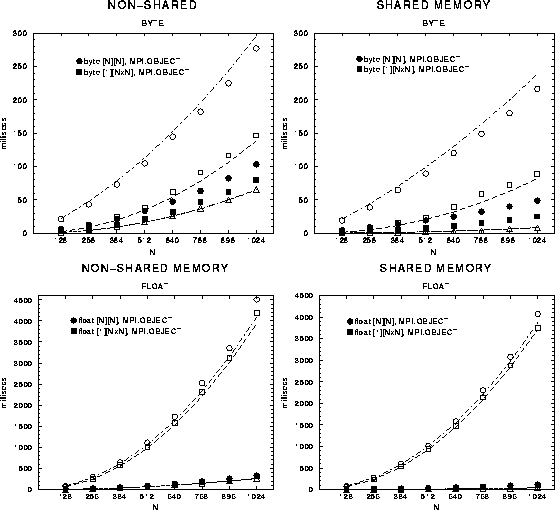
Figure: Timings allowing two-dimensional array proxies in the
object stream (solid points),
compared with the unoptimized results from Figure 3
(open points).
Sends of two-dimensional Java arrays (solid circles) are now much closer to
the native bandwidth (of which the triangular points are representative).
This process could continue almost indefinitely--adding special cases for
arrays and other structures considered critical to Grande applications.
Currently we do not envisage pushing this approach any further than
two-dimensional array proxies. Of course three-dimensional
arrays and higher will automaticall benefit from the optimization of
their lower-dimensional component arrays. Recognizing a rectangular
two-dimensional arrays already adds some unwanted complexity to the
serialization process![]() .
.