The related projects of our work may include development of MPI, HPF,
and other parallel languages such as ZPL and Spar, which are
introduced else where![]() . Here we
explain more backgrounds and future developments about our own
project.
. Here we
explain more backgrounds and future developments about our own
project.
The work originated in our compilation practice in HPF. As introduced in [2], our compiler emphasize runtime system support. Adlib[6], as PCRC runtime kernel library, provides a rich set of collective communication functions. During the practice, it is realized that the runtime interface can be effectively raised to a higher level, and a rather straight-forward (compared to HPF) compiler can be developed to translate the high level language code to a node program calling runtime interface functions.
Currently, Java interface has been implemented on top of the Adlib library. With classes such as Group, Rang and Location in the Java interface, one can write Java programs quite similar to HPJava we proposed here. Yet, the program executed in this way will have large overhead due to function calls (such as address translation) when accessing data inside loop constructs.
Given the knowledge of data distribution plus inquiry functions inside runtime library, one can substitute address translation calls with linear operation on the loop variable, and keep most of the inquiry function calls out side loop constructs. This is the basic idea of the HPJava compiler.
At present time, we are working on the design and implementation of the prototype of this kind ``translator''. Further research works may include optimization and safety-checking techniques in the compiler for HPspmd programming.
Figure 3 shows a preliminary benchmark for hand translated codes of our examples. The parallel programs are executed on 4 sparc-sun-solaris2.5.1 with mpich MPI and Java JIT compiler in JDK 1.2Beta2. For Jacobi iteration, the timing is for about 90 iterations.
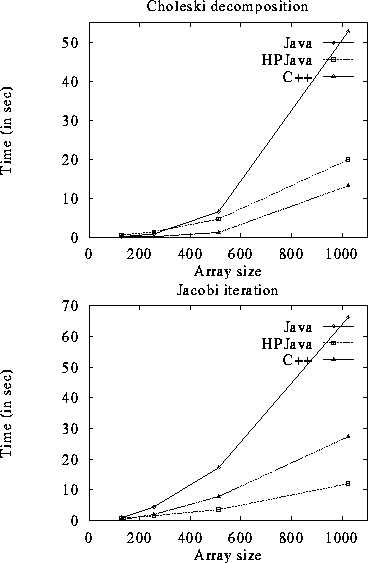
Figure 3: Preliminary performance
We also compared the sequential C++ version of the code. As shown in the figure.
Similar test was made on an 8-node SGI challenge(mips-sgi-irix6.2), the communication time is much smaller than the one on solaris, due to MPI device using shared memory. Yet the overall performance is not as good, because the JIT compiler is not supported on irix. The whole system are being ported to Windows NT, where we may use both shared memory and JIT techniques.